标签:
HashSet类
关于HashMap的实现细节
HashMap是用LinkedList实现的,每个list被称为一个桶(bucket),在hashmap中要查找一个元素,首先对传入的key进行散列,并根据散列函数(最简单的散列函数是取余运算)找到是哪个桶,然后在顺着桶的linkedlist寻找这个key。
向HashMap插入一个元素时也一样,先算散列函数,应该存在到哪个桶上,如果这个桶上没有存任何元素,就叫没有散列冲突(hash collision),那直接存进去即可。如果发生了冲突,即已经有元素存在此桶对应的linkedlist上了,那么就将此插入元素插入对应list中。 如下图: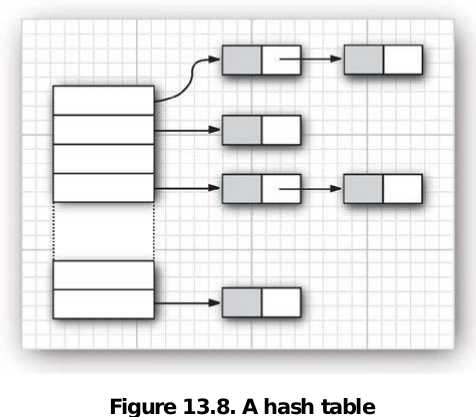
当然,如果Hash table太满的话,就需要重新散列,即准备一个更大的table,将原来老的table中的元素放到新的table中,并将老的table废弃。
treeset是一个排序后的集合,当遍历其中的元素时是已经排序好的:
SortedSet<String> sorter = new TreeSet<>(); // TreeSet implements
SortedSet
sorter.add("Bob");
sorter.add("Amy");
sorter.add("Carl");
for (String s : sorter) System.println(s);
输出:
Amy Bob Carl
这种排序是内部使用红黑树数据结构实现的。
将一个元素插入到treeset的时间消耗要比hashmap慢,但是要比插入到arraylist和linkedlist要快(linkedlist如果只是插入操作会很快,问题是要先寻找到插入的正确位置,故要先从头遍历list,消耗时间)。
如果一个tree中包含n个元素,那么平均要花 log 2 n 次比较找到元素正确插入的位置。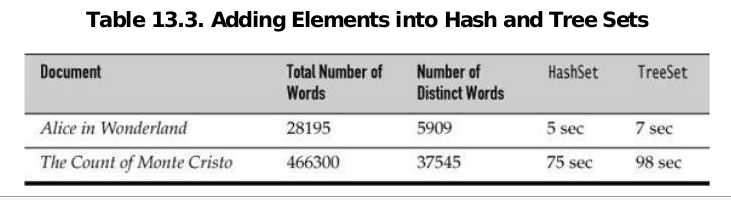
上面的TreeSet类需要对象的比较,默认情况下,假定你要插入的元素实现了接口Comparable:
public interface Comparable<T>
{
int comparaTo(T other);
}
还有一种方式是新创建一个类并实现接口Comparator:
public ItemComparator implements Comparator<Item>
{
public int compare(Item a, Item b)
{
...
}
}
然后在TreeSet的构造函数中传入这个比较器:
ItemComparator comp = new ItemComparator();
SortedSet<Item> sortByDescription = new TreeSet<>(comp);
标签:
原文地址:http://www.cnblogs.com/liupengblog/p/5181827.html