标签:
内部排序是一件具有重大意义的问题,许多项目的实现中都需要用到排序。
我们知道,排序的算法有许多种,每种排序算法的时间复杂度和空间复杂度不尽相同。在解决实际问题时,往往需要根据实际需要选择排序算法。
上次实验已经讨论了希尔排序的实现及其原理,本实验重点介绍另一种排序算法——快速排序。实验中将讨论快速排序的实现及其原理。
本实验重点在算法实现上,数据结构的思想被弱化了。在排序过程中,由于维护序关系的需要,要有交换的操作,这就破坏了ADT的物理位置的相邻反映逻辑的依次的性质,可以说这里的顺序结构只是一个二次结构。因此,本实验不对此作过多说明。
1、算法描述
快速排序是一种基于比较的排序算法,算法是不稳定的。有一种形象的叫法是“挖坑+分治”排序来形容快速排序。以下简要说明其操作。
以不降序排序为例。选择序列中一个元素作为基准元素,本实验中选择的是序列区间的第一个元素。定义两个指针(这里的指针只是一个意指,不一定用c++语言中真正的指针来实现,可以是一个整型数)i和j,初始时分别指向待排序列区间的首、尾。
每一轮排序时,选择第一个元素作为基准元素,相当于在序列区间的第一个位置挖了一个坑,现在要填坑。移动j,直到Elem[j]比基准元素小,将Elem[j]挖出来填到第一个位置,这时坑就是j这个位置了;移动i,知道Elem[i]比基准元素大,将Elem[i]挖出来填到j位置,这时坑就是i这个位置了。重复上述挖坑、填坑的操作,直到i == j,结束循环。此时,将基准元素填入当前的坑里,于是在该基准元素的左侧的元素都比它小,右侧的都比它大。这时就出现了一个自相似的子结构,于是很自然地选择递归,将当前的待排序序列区间以基准元素的位置一分为二,分别重复上述过程。递归的边界是当前区间只有一个元素,平凡有序。
所谓“挖坑”上面已经提到了,所谓“分治”就是指的区间一分为二的递归过程。
2、算法复杂度分析
快速排序的时间主要耗费在划分操作上,设当前待排序区间长度为k,则共需要k-1次关键字的比较。
最坏情况是每次划分选取的基准元素都是当前区间的最小(或者最大)元素,那么划分的结果将是左边的子区间(或者右边的子区间)为空,而右边的子区间(或者左边的子区间)长度为k-1,仅比之前少一个元素。此时的时间复杂度为O(n^2)。
最好情况是每次划分选取的基准元素都正好是当前区间的中位数,划分的结果是左、右子区间元素个数大致相等,总的复杂度为O(n lgn)。
尽管快速排序的最坏情况复杂度逼近平方级别,但就平均性能而言,它是基于关键字比较的内部排序算法中速度最快的(这个网上有许多算法的时间测试,这里不再赘述),它的平均时间复杂度为O(n lgn)。
3、例子
(1)第一轮
| 基准元素下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 72 | 72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 | |
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 | |
| 48 | 6 | 57 | 42 | 60 | 42 | 83 | 73 | 88 | 85 | |
| 48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
(2)第二轮
a)区间[1,5]
| 基准元素下标 | 1 | 2 | 3 | 4 | 5 |
| 48 | 48 | 6 | 57 | 42 | 60 |
| 42 | 6 | 57 | 42 | 60 | |
| 42 | 6 | 57 | 57 | 60 | |
| 42 | 6 | 48 | 57 | 60 |
b)区间[7,10]
| 基准元素下标 | 7 | 8 | 9 | 10 |
| 83 | 83 | 73 | 88 | 85 |
| 73 | 73 | 88 | 85 | |
| 73 | 83 | 88 | 85 |
c)总的序列
| 42 | 6 | 48 | 57 | 60 | 72 | 73 | 83 | 88 | 85 |
(3)第三轮
a)区间[1,2]
| 基准元素下标 | 1 | 2 |
| 42 | 42 | 6 |
| 6 | 6 | |
| 6 | 42 |
b)区间[4,5]
| 基准元素下标 | 4 | 5 |
| 57 | 57 | 60 |
| 57 | 60 |
c)区间[7,7],直接返回
d)区间[9,10]
| 基准元素下标 | 9 | 10 |
| 88 | 88 | 85 |
| 85 | 85 | |
| 85 | 88 |
e)总的序列
| 6 | 42 | 48 | 57 | 60 | 72 | 73 | 83 | 85 | 88 |
排序完成
1、预期结果
程序能够正确地将一个序列按照不递减的顺序排序。下图为一个例子。
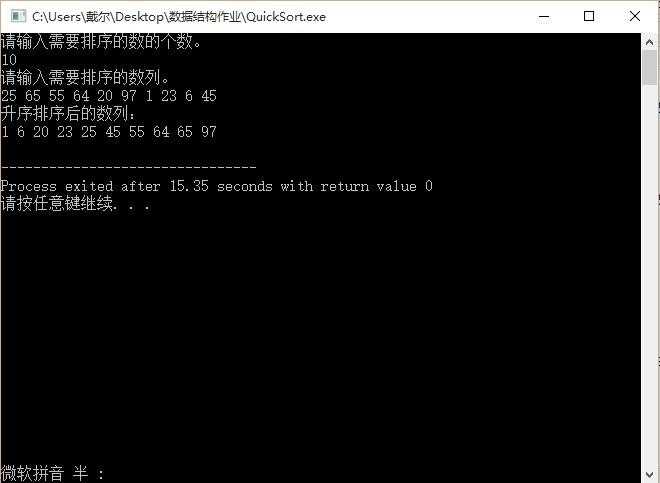
2、实验中的问题及思考
快速排序还有一些改进的版本,当然比较常见的是在选择基准元素的时候采用随机选择的方式。据研究表明,选择黄金分割点处的数作为基准元素的期望速度最快,这个我还没有仔细学习过。

1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 5 using namespace std; 6 #define MaxN 120 7 8 int gap[200]; //步长 2^k+1 第一项改为1 9 int n; 10 11 template <class T> class My_list 12 { 13 private: 14 T Elem[MaxN]; //待排序的元素 15 int Len; //元素个数 16 public: 17 void Init() 18 { 19 memset(Elem, 0, sizeof(Elem)); 20 Len = 0; 21 } 22 void Insert_back(T x) 23 { 24 Elem[++Len] = x; 25 } 26 void Print() 27 { 28 int i; 29 for(i = 1; i < Len; i++) 30 printf("%d ", Elem[i]); 31 printf("%d\n", Elem[i]); 32 } 33 int GetLen() 34 { 35 return Len; 36 } 37 void QuickSort(int st, int ed) 38 { 39 if(st < ed) 40 { 41 int i = st, j = ed, x = Elem[st]; 42 while(i < j) 43 { 44 while(i < j && Elem[j] > x) //找右侧比x大的元素 45 j--; 46 if(i < j) 47 Elem[i++] = Elem[j]; 48 while(i < j && Elem[i] < x) //找左侧比x小的元素 49 i++; 50 if(i < j) 51 Elem[j--] = Elem[i]; 52 } 53 Elem[i] = x; 54 QuickSort(st, i - 1); //分治左侧区间 55 QuickSort(i + 1, ed); //分治右侧区间 56 } //if 57 } 58 }; 59 60 void Read(My_list <int> &L) 61 { 62 int i, x; 63 L.Init(); 64 printf("请输入需要排序的数的个数。\n"); 65 scanf("%d", &n); 66 printf("请输入需要排序的数列。\n"); 67 for(i = 1; i <= n; i++) 68 { 69 scanf("%d", &x); 70 L.Insert_back(x); //把x插入到最后 71 } 72 } 73 74 int main() 75 { 76 int GapNum; 77 My_list <int> L; 78 Read(L); 79 L.QuickSort(1, n); 80 printf("升序排序后的数列:\n"); 81 L.Print(); 82 return 0; 83 }
标签:
原文地址:http://www.cnblogs.com/CQBZOIer-zyy/p/5185409.html
