标签:
比较完常见后置处理器的性能之后,又顺便比较了下Groovy和BeanShell
2者都是基于JVM的脚本语言,2者都能直接用Java的语法和类库
这些国外网站都推荐用Groovy:
http://jmeter.apache.org/usermanual/best-practices.html
http://www.ubik-ingenierie.com/blog/magento-performance-toolkit-and-jmeter-best-practices/
https://blazemeter.com/blog/beanshell-vs-jsr223-vs-java-jmeter-scripting-its-performance
因为JMeter支持的一堆脚本语言里,只有它有预编译
关于jmeter的中文网站里提到groovy的很少,不知有人比较过预编译带来的速度提升有多大没
正好闲着来试一下
环境:jmeter 2.13、JDK 1.8u73、JVM参数从来没动过、win 10 pro
在项目里我就是直接上Groovy的,可以用现成的脚本来测试 :)

生成随机手机号的脚本,注释就不截了
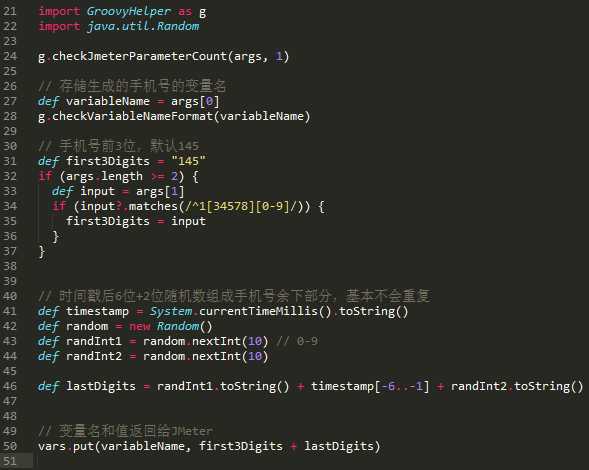
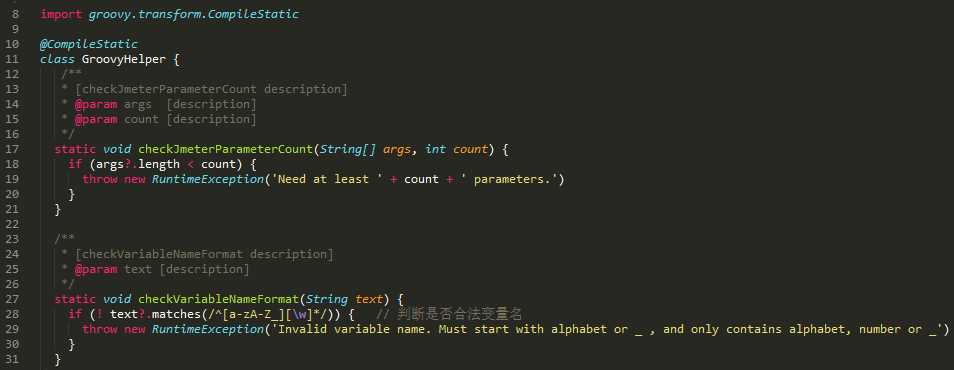
提取到另一个脚本的公用方法,无关的也不截了
为了效率,用了静态编译(性能比较见这里)
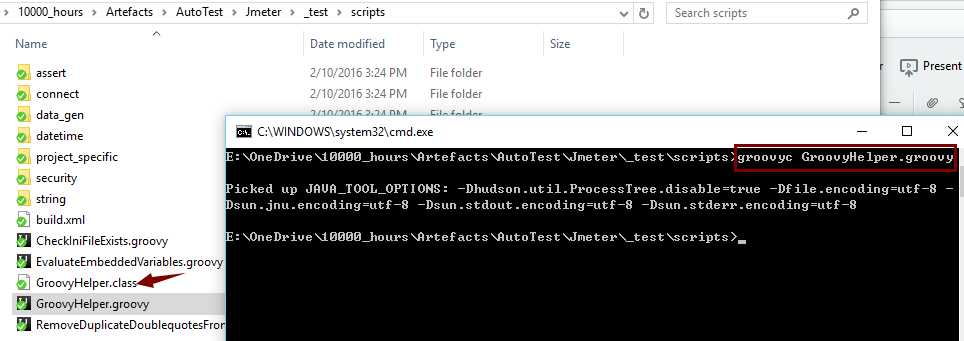
每当这脚本有改动,要用groovyc重新编译(生成的class文件跟java一样,用jad反编译就能看到java代码)
其他脚本引用的就是这个class文件
scripts目录加入了jmeter的properties文件里,所以哪里都能引用到这文件
为了测试,创建个beanshell脚本文件,就是文本文档把后缀改为.bsh

不知道beanshell风格是怎样,直接套java语法
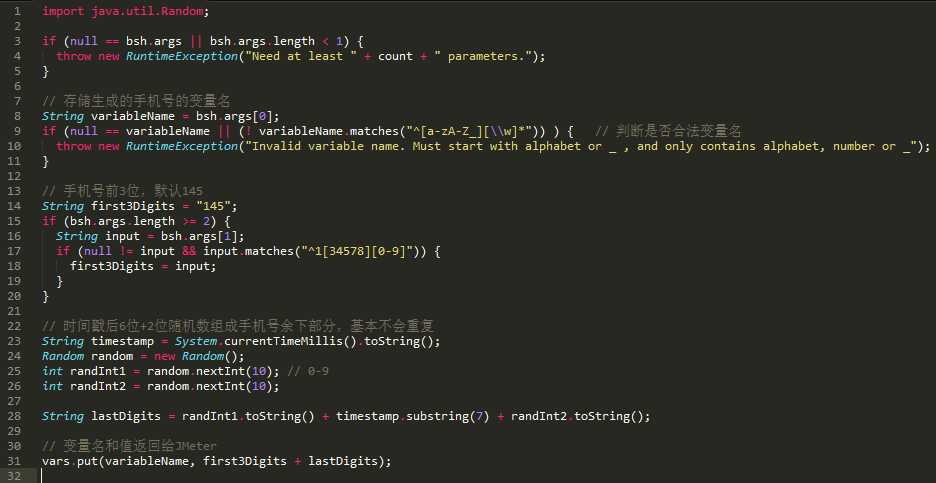
现在2边做的事是一样的,beanshell脚本还少几次调用
我们进JMeter,建好如下的测试计划:
暂时用不着的组件先ctrl + t禁用掉
先测试最简单的hello world,采样器配置如下:
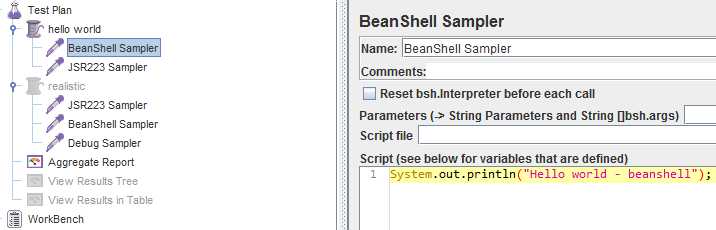
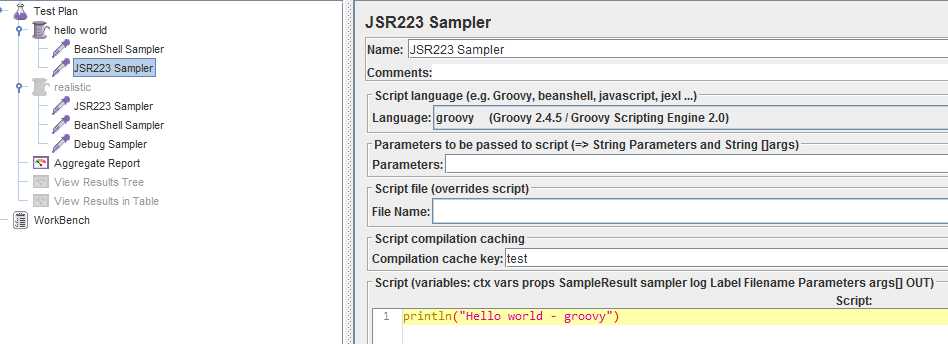
* 要先下载安装groovy,安装目录下找到embeddable文件夹,把groovy-all-2.x.x.jar拷到jmeter安装目录下的lib文件夹下
然后重启jmeter才能在jsr223的菜单里看到groovy的选项
* cache key随便写点什么,保证唯一就行。直接在下面写脚本时需要写上cache key才有预编译
重启jmeter,运行测试1次,看到jmeter的命令行窗口里有了正确的输出
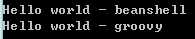
然而2边都慢得离谱,尤其是groovy慢得吓死人

清掉记录再来,预热之后好看点了
之后n次都差不多,groovy从来没低于10毫秒

一个hello world都比beanshell慢3~十几倍,这能用吗?
我们看看拿正经的脚本,跑足够多的次数会怎样
首先2个采样器的设置如下:
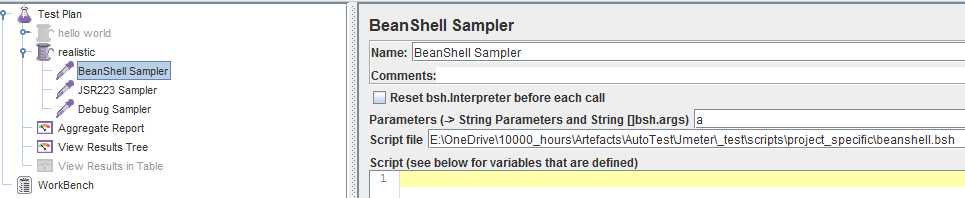
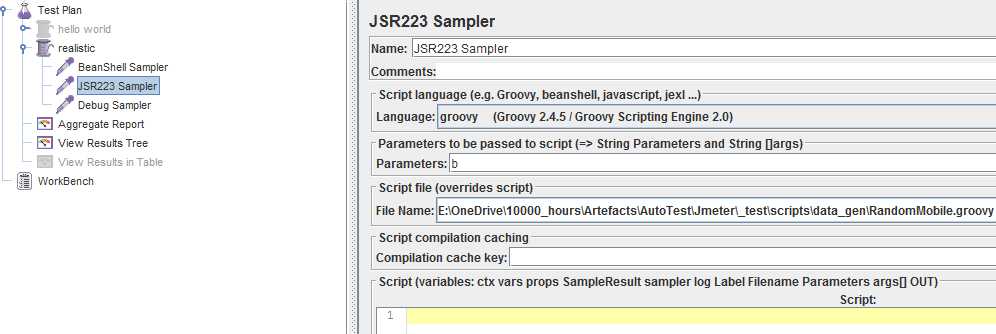
就是填脚本文件的路径和传个变量名给脚本,没啥特别
值得注意的是groovy只要使用了外部脚本文件就有预编译,这时不用填cache key
用1个线程循环1次调试通过
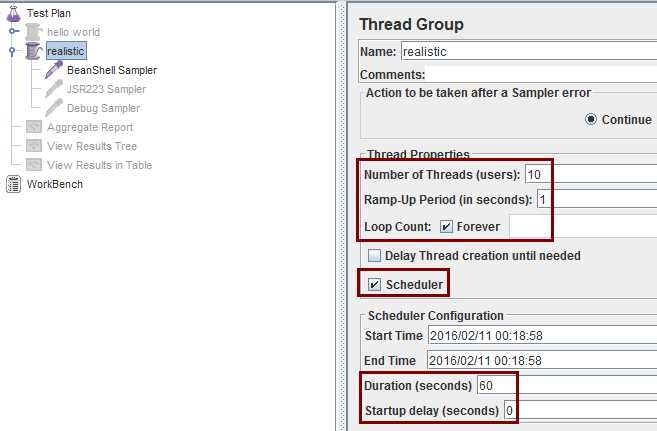
修改线程组设置为:10个线程,1秒集结(0.1秒来1个),持续60秒,无启动延迟
ctrl + t禁用无关的组件(变灰那些),注意关掉所有监听器,因为接下来要用命令行运行,留着它们会拖累吞吐率
关掉界面,用命令行跑测试,结果如下:
BeanShell

再进界面改成用jsr223采样器,等爆表的cpu内存占用率回落后再跑,结果如下:
Groovy

留意summary + 的那几行,groovy一开始特别慢,请求耗时的最大值吓死人,之后减少了10倍,最终结果就是
3倍速!
没什么好说的,选Groovy就对了(而且Gradle和Jenkins也用得到它)
PS:
上述测试保存报告文件为csv格式,使用如下设置
大部分数据在这里都用不上,关到剩下最精简的几个
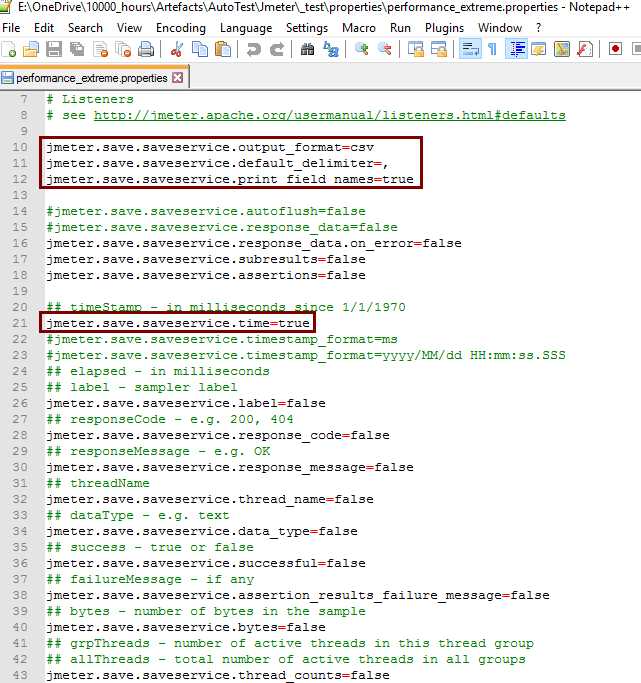
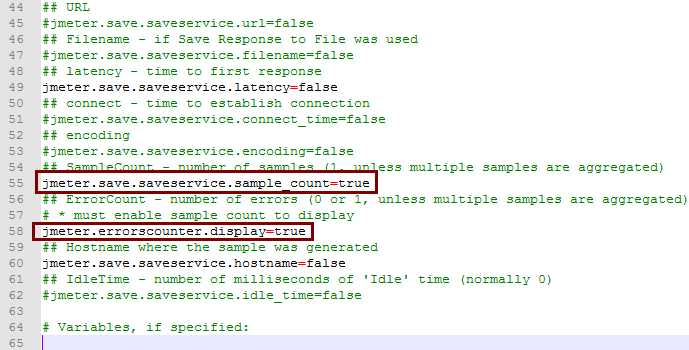
如果用通常的设置,报告文件估计要大5倍不止

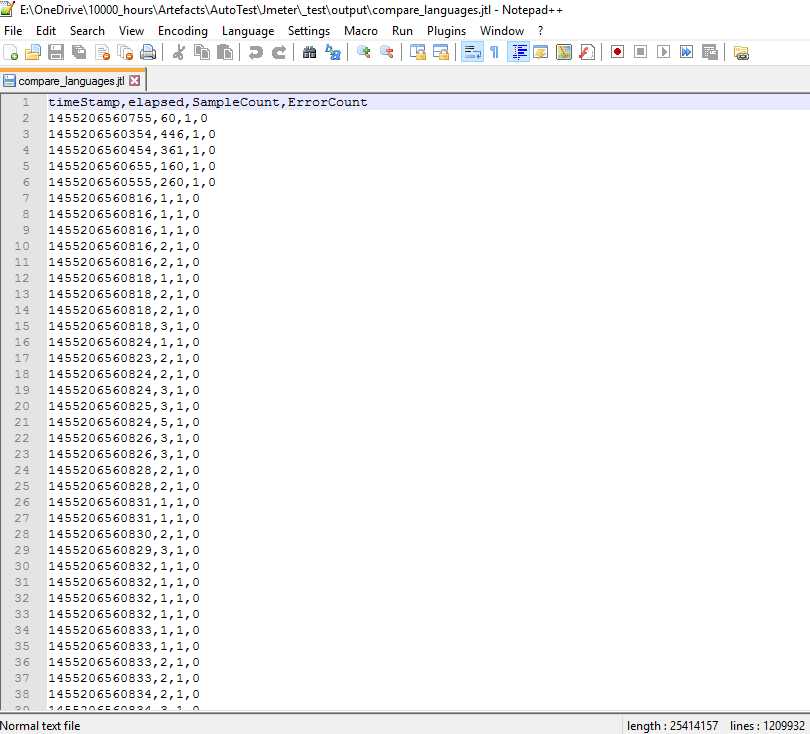
就剩4列,似乎没法再少了
留意耗时最长的一般都是前几次,之后就快了,统计时忽略开头某段时间的数据就好
又PS:
上面的生成手机号的脚本是给接口测试用的,性能测试就别当场生成了
先搞好几十万个塞进数据库或csv文件慢慢用吧
JMeter中Groovy和BeanShell脚本的性能比较
标签:
原文地址:http://www.cnblogs.com/keithmo/p/5186693.html