标签:
这几天突发想到在ETL中Merge性能的问题。思路的出发点是Merge到目标表需要扫描的数据太多,而现实情况下,假设应该是只有一小部分会被更新,而且这部分数据也应该是比较新的数据,比方说对于想FactOrders这样一张表,一些越日期越久远的订单可能不可能被更新。那么整个思路就是减小每次需要从磁盘加载目标表到内存中跟stage表进行merge操作的数据量。只是我存在着两个疑问,这也是我问题要进行下面实验的原因。
前提条件是:目标表通过日期进行分区。
第一个疑问:在索引的作用下,SQL Server到底能不能聪明到只加载必要的分区,而不是整张表的数据?
第二个疑问:假设SQL Server自己不够聪明,那么我们通过引导SQL Server去加载必要分区即可,这下SQL Server知不知道该怎么做?
为此我要做三个实验:
第一个实验:Merge语句中目标表和源表的Join字段建立索引,看看SQL Server有没有缩小对目标表的数据集加载
第二个实验:用CTE封装目标表数据,并用Where语句缩小数据集,然后Merge语句把CTE作为目标表
第三个实验:这个应该是最有保证的做法,通过语句查找出涉及到的分区,再从目标表中把那些分区切换到另外的一张临时建立的表中,然后对这张临时建立的表进行和stage表的merge操作,再把数据切换回目标表。这个做法做有保证,但是也是最复杂的。首先生成临时建立的表的表结构必须和目标表一致,这就需要写一个过程专门要干这事。
先建好分区函数、Scheme、目标表和stage表
CREATE PARTITION FUNCTION myRangePF1 (DATETIME) AS RANGE LEFT FOR VALUES (‘2015-01-01‘, ‘2015-02-01‘, ‘2015-03-01‘, ‘2015-04-01‘, ‘2015-05-01‘, ‘2015-06-01‘, ‘2015-07-01‘, ‘2015-08-01‘, ‘2015-09-01‘, ‘2015-10-01‘, ‘2015-11-01‘, ‘2015-12-01‘, ‘2016-01-01‘); GO CREATE PARTITION SCHEME myRangePS1 AS PARTITION myRangePF1 TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY],[PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY],[PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY]); GO CREATE TABLE dbo.Merge_Perf_test_target ( col1 INT, col2 DATETIME, col3 VARCHAR(1000), col4 FLOAT ) ON myRangePS1(col2) WITH(DATA_COMPRESSION=PAGE) GO INSERT dbo.Merge_Perf_test_target SELECT [ID], DATEADD(SECOND,ABS(CHECKSUM(NEWID()))%(DATEDIFF(SECOND,‘2015-01-01‘,‘2016-01-01‘)-1),‘2015-01-01‘), REPLICATE(‘A‘,(CHECKSUM(NEWID())%500)+1), 1.*ABS(CHECKSUM(NEWID()))/ABS(CHECKSUM(NEWID())) FROM [dbo].[Numbers] --SELECT * FROM sys.partitions WHERE [object_id] = object_id(‘Merge_Perf_test_target‘) AND index_id in (0,1) --SELECT * FROM sys.indexes WHERE [object_id] = object_id(‘Merge_Perf_test_target‘) AND index_id in (0,1) --SELECT * FROM sys.data_spaces WHERE data_space_id = 65601 --SET STATISTICS IO ON --GO --SELECT COUNT(*) --FROM dbo.Merge_Perf_test_target --WHERE (col2 > = ‘2015-04-01‘ AND col2 < ‘2015-05-01‘) OR -- (col2 > = ‘2015-10-01‘ AND col2 < ‘2015-11-01‘) --GO CREATE TABLE dbo.Merge_Perf_test_src ( col1 INT, col2 DATETIME, col3 VARCHAR(1000), col4 FLOAT ) GO --TRUNCATE TABLE dbo.Merge_Perf_test_src INSERT dbo.Merge_Perf_test_src SELECT col1, DATEADD(SECOND,ABS(CHECKSUM(NEWID()))%(DATEDIFF(SECOND,‘2015-03-01‘,‘2015-04-01‘)-1),‘2015-01-01‘), REPLICATE(‘A‘,(CHECKSUM(NEWID())%500)+1), 1.*ABS(CHECKSUM(NEWID()))/ABS(CHECKSUM(NEWID())) FROM dbo.Merge_Perf_test_target WHERE (col2 > = ‘2015-04-01‘ AND col2 < ‘2015-05-01‘); INSERT dbo.Merge_Perf_test_src SELECT col1, DATEADD(SECOND,ABS(CHECKSUM(NEWID()))%(DATEDIFF(SECOND,‘2015-10-01‘,‘2015-11-01‘)-1),‘2015-10-01‘), REPLICATE(‘A‘,(CHECKSUM(NEWID())%500)+1), 1.*ABS(CHECKSUM(NEWID()))/ABS(CHECKSUM(NEWID())) FROM dbo.Merge_Perf_test_target WHERE (col2 > = ‘2015-10-01‘ AND col2 < ‘2015-11-01‘); GO
实验一:
创建索引然后运行merge
CREATE INDEX IX_Merge_Perf_test_target_col1 ON dbo.Merge_Perf_test_target(col1) CREATE INDEX IX_Merge_Perf_test_src_col1 ON dbo.Merge_Perf_test_src(col1) --SELECT * FROM Merge_Perf_test_src MERGE Merge_Perf_test_target AS tgt USING dbo.Merge_Perf_test_src AS src ON tgt.col1 = src.col1 WHEN MATCHED THEN UPDATE SET tgt.col2 = src.col2, tgt.col3 = src.col3, tgt.col4 = src.col4;
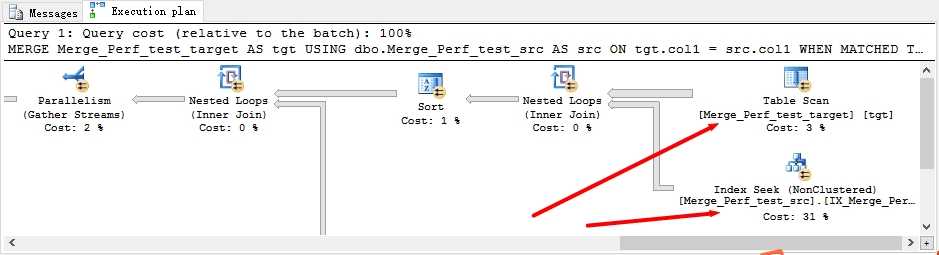
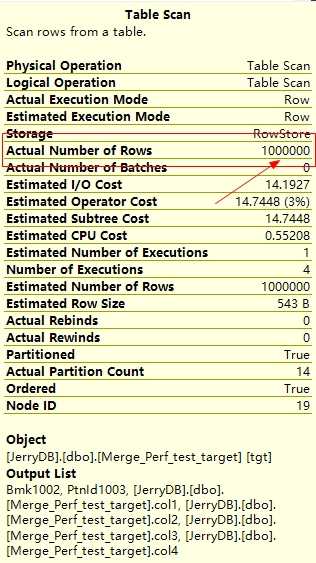
通过图形执行计划可以看到实际行数是一百万,也就是目标表整张表的行数。第一个假设失败。SQL Server自己不会聪明到减小数据范围的缩小。

实验二:
删掉前面建立的索引
drop index IX_Merge_Perf_test_target_col1 on Merge_Perf_test_target drop index IX_Merge_Perf_test_src_col1 on Merge_Perf_test_src
这一步设计是需要动态SQL来协助完成的。通过下面的SQL输出的结果来拼凑出Where条件语句,也就是以分区列作为删选条件缩小数据集。
SELECT col.name, ty.name as type, prt_fn.type_desc, prt_fn.boundary_value_on_right, curr.value as start_value, nxt.value as next_start_value FROM sys.index_columns ix_col INNER JOIN sys.columns col ON col.object_id = ix_col.object_id AND ix_col.column_id = col.column_id INNER JOIN sys.types ty ON ty.system_type_id = col.system_type_id INNER JOIN sys.indexes ix ON ix.object_id = ix_col.object_id AND ix.index_id = ix_col.index_id INNER JOIN sys.partitions prt ON prt.object_id = ix.object_id AND prt.index_id = ix.index_id INNER JOIN sys.data_spaces ds ON ds.data_space_id = ix.data_space_id INNER JOIN sys.partition_schemes prt_sch ON ds.data_space_id = prt_sch.data_space_id INNER JOIN sys.partition_functions prt_fn ON prt_sch.function_id = prt_fn.function_id INNER JOIN (sys.partition_range_values curr LEFT JOIN sys.partition_range_values nxt ON curr.function_id = nxt.function_id AND curr.boundary_id = nxt.boundary_id - 1) ON prt_sch.function_id = curr.function_id AND prt.partition_number-1 = curr.boundary_id WHERE ix_col.partition_ordinal = 1 AND prt.partition_number IN (SELECT $PARTITION.myRangePF1(col2) prt_no FROM dbo.Merge_Perf_test_src) and prt.object_id = object_id(‘Merge_Perf_test_target‘)
上面的语句输出下面的结果
上面输出的结果为了拼凑出像(col2 >= ‘2015-01-01 00:00:00.000‘ AND col2 < ‘2015-02-01 00:00:00.000‘) OR (col2 >= ‘2015-10-01 00:00:00.000‘ AND col2 < ‘2015-11-01 00:00:00.000‘))这样的Where语句。那type输出字段再这里的作用就是为了却分是整型字段还是时间字段,因为时间字段需要添加两个单括号。而type_desc在这里是为了区分到底是范围还是值,值得肯定是要拼凑出值列表字符串给IN字句,范围就是像上面那样用大小括号。boundary_value_on_right是决定等于号到底最后放在大于号还是小于号上。这里不实现这个逻辑。只说明设计做法。
通过CTE加入Where条件,运行后再观察
WITH T AS (SELECT * FROM dbo.Merge_Perf_test_target WHERE (col2 >= ‘2015-01-01 00:00:00.000‘ AND col2 < ‘2015-02-01 00:00:00.000‘) OR (col2 >= ‘2015-10-01 00:00:00.000‘ AND col2 < ‘2015-11-01 00:00:00.000‘)) MERGE Merge_Perf_test_target AS tgt USING dbo.Merge_Perf_test_src AS src ON tgt.col1 = src.col1 WHEN MATCHED THEN UPDATE SET tgt.col2 = src.col2, tgt.col3 = src.col3, tgt.col4 = src.col4;
图形执行计划可以看到使用了range scan,起码从的Seek Predicates可以看出
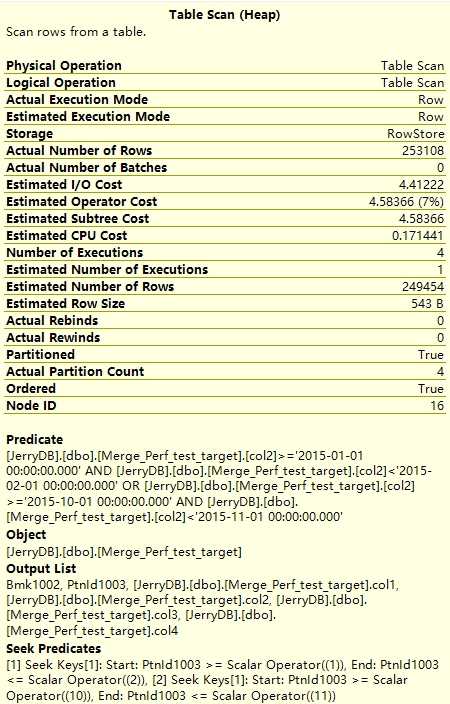

相比实验一减少了一半的时间
实验三:
这个设计的核心是找出涉及到的分区号,然后用SWITCH PARTITION切换到另外一个临时建立的表,再MERGE,再SWITCH PARTITION回去。按道理来讲和实验二比应该区别不大。这里也是需要用到动态语句协助。把下面输出的分区号码拼成一条字符串放到SWITCH PARTITION()中。
SELECT distinct $PARTITION.myRangePF1(col2) prt_no FROM dbo.Merge_Perf_test_src
这里最重要的一步是要运行时动态建立起一张和目标表架构相同的表,包括压缩级别和分区方法。实现其实不难,只是需要写代码查找各张系统视图或者系统表。这里略过。
ALTER TABLE dbo.Merge_Perf_test_target SWITCH PARTITION 2 TO dbo.Merge_Perf_test_target_tmp PARTITION 2 ALTER TABLE dbo.Merge_Perf_test_target SWITCH PARTITION 11 TO dbo.Merge_Perf_test_target_tmp PARTITION 11
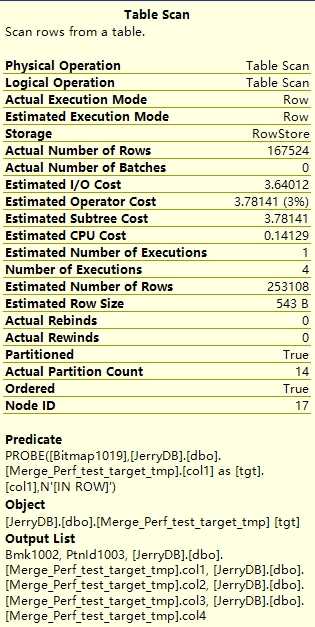
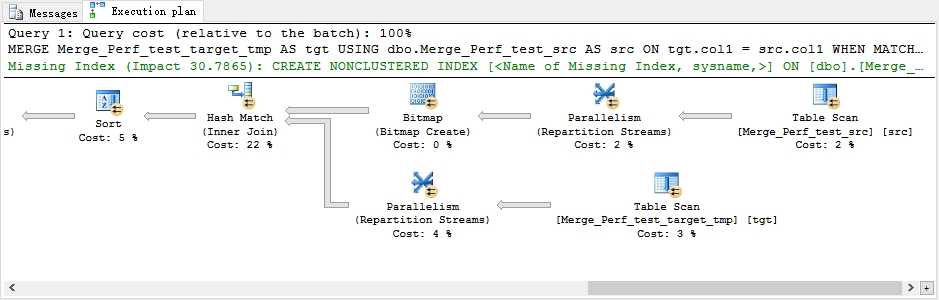

从上面看到,时间上其实和第二种方法也只是快了5秒,但是实际上IO上是一样的。但是第二种方法比第三种方法有一点可以说可能是优点的同时也是缺点,就是第二种方法有时会遇到锁阻塞的问题。因为一旦改动数据范围大就意味着SQL Server可能多目标表加表级别锁,这样所有在同一时间点对目标表的访问都会被阻塞住。但是并不意味着这点就是好的。因为数据被移除目标表,意味着虽然没有阻塞,但是没有数据其实从另一个层面来讲是错的,这个时候就好像数据被删除了一样,甚至比阻塞还严重。
SQL Server ->> 尝试优化ETL中优化Merge性能
标签:
原文地址:http://www.cnblogs.com/jenrrychen/p/4830120.html