标签:
第5-7章感觉是这一本书中比较奇怪的章节,可能是作者考虑到读者人群水平的差异,故意由浅入深地讲如何在屏幕上显示字符和使用mov,jmp指令等等,但是这样讲的东西有点重复,而且看了第六,第七章以后,感觉第5章的做法真是太笨了。
★PART1:显卡与显存
1. 显卡与显存
a. 显卡控制显示器的最小单位是像素,一个像素对应着屏幕的一个点,屏幕上通常有数十万乃至更多的像素。而控制这些像素就要用到显存自己内置的一个东西,这个东西叫做显存(Video RAM,VRAM) 。显存和其他半导体存储器一样,也是按字节访问的储存元件,如果要显示黑白影像,那么只要控制显存的每一个比特位是0和1就足够了。
b. 如果要显示更多的颜色,就要用更多的比特位来显示一种颜色外了,现在最流行的是真彩色,真彩色用24个比特,即三个字节来对应一个像素,而224=16777216,所以真彩色可以显示16777216种颜色,采用真彩色显示的模式叫做显卡的图形模式。
c. 而在文本模式下,字符的代码放在显存里,第一个代码对应着屏幕左上角的一个字符,第二个代码对应着屏幕左上角的第二个字符,后面的以此类推。显存里面的字符通过字符发生器和控制电路将字符显示出来,显卡在不同模式下对内容的解释是不一样的。
d. 为了加快读取和输出速度,显存是直接映射在处理器能处理的内存中的(而不需要和显卡的外围接口打交道),也就是内存空间,通常情况下常规内存是占用8086处理器的前640KB(也就是0x00000-0x9FFFF),BIOS-ROM占用最顶端的64KB((地址0xF0000-0xFFFFF),中间还有320KB的空间,其中0xB8000-0xBFFFF这段空间就是给显卡的,每一次显卡加电自检的时候,都会把自己初始化80*25的文本模式,屏幕上可以显示25行,每一行80个字符,一共2000个字符。计算机每次加电自检都会检查这个区域,如果这个区域无法访问,就说明显卡出现故障或者没有插入显卡,就会出现严重错误,计算机无法启动。
2. 显存内容与显示器的关系
a. 和访问主内存一样,访问显存也是需要逻辑地址(段地址:偏移地址),文本模式下的缓冲区不超过32KB(0xB8000-0xBFFFF),我们可以使用ES来指向显存所指的段
mov ax,0xb800 mov es,ax
但是不可以写成mov es, 0xb800 Intel的处理器不允许直接将一个立即数传入段寄存器,只能通过通用寄存器来中转。
b. ASCII(ASCII是7位代码,只用了一个字节的7个位,最高位通常是0),ASCII中有可显示代码,有一些是控制字符,具体由下表决定。
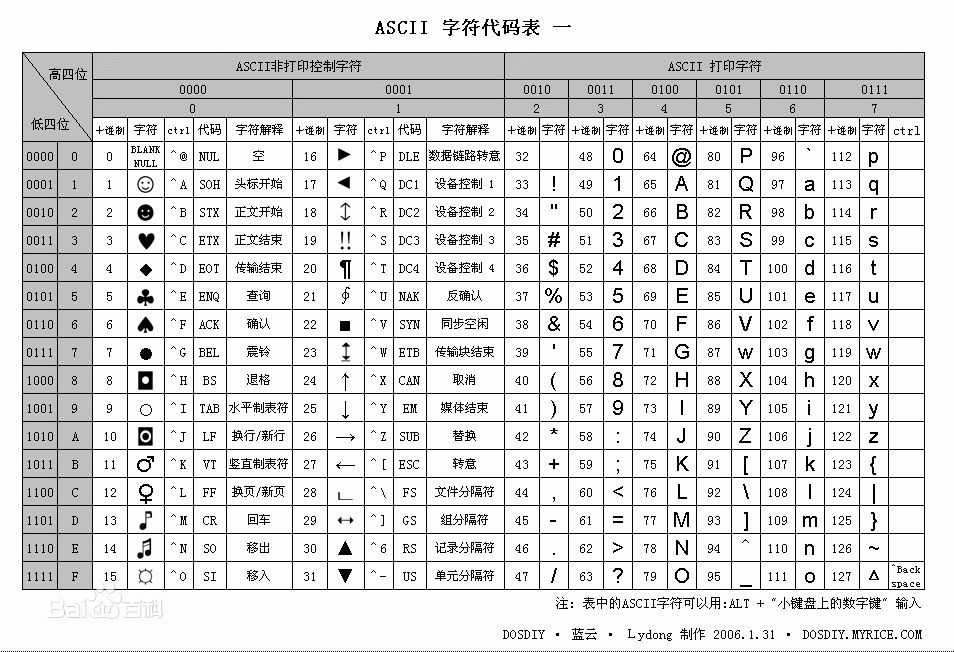
c. 屏幕上的每个字符对应着显存的两个连续的字节,前一个字符是ASCII码,后面是字符的显示属性,包括字符颜色(前景色)和底色(背景色) 。字符属性可看下表。
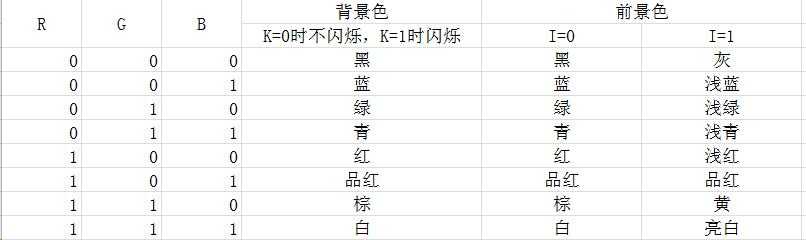
当屏幕上什么都没有的时候,显示的是空白字符(ASCII:32)
d. 可以通过下列代码显示字符
mov byte [es:0x00],‘L’
(’L’可以改成0x40,加了es的意思是采用es的段地址,而不是默认的DS,因为这里是将立即数传入内存,所以要指定是传入byte还是word。)
★PART2:8086环境下NASM汇编基础知识
1. 标号
a. 每条指令都有自己的汇编地址,NASM给每条指令都提供了可以标记的功能,每条指令前面都可以拥有标号,以代表和指示该指令的汇编地址。比如:
infi: jmp near infi
(冒号可以不要,标号也可以单独一行,标号可以由字母、数字、“_”、“$”、“#”、“@”、“~”、“.”、“?”组成,但必须以字母、“.”、“_”和“?”中的任意一个开头。
2. 数据声明和常数(伪指令)
a. 普通数据的声明DB,DW,DD,DQ,分别是可以声明字节,字,双字,四字的数据,这些都是伪指令(编译器提供的汇编指令,不是机器指令),数据声明的每一个数据都要用逗号隔开,而且大小不能超过声明的类型的大小。这些声明并且初始化的数据会占据汇编地址。
b. 可以用equ来声明一个常数,比如
app_lab_start equ 100
这样app_lab_start就是一个常数,他的值是100,可以把他当100来使用,并且他不占用任何地址,也不会在运行时占用任何内存位置。
3. 关于主引导扇区的编程
a. 主引导扇区是512个字节大小的,一个有效的主引导扇区,最后的两个字节必须是0x55,0xAA,定义这两个字节直接用dd或者dw就可以了(DB 0x55,0xAA,或者DW 0xAA55(Intel是低端字节序)),填充主引导扇区的剩余字节可以用times指令,另外NASM提供了两个标号让我们不用去手动去算究竟我们需要填充多少的字节。这两个标号分别是$(当前行标志)和$$(当前汇编段的汇编地址,如果当前没有定义节或者段,那么就默认地自成一个汇编段),填充字节可以用times命令。
比如所有的主引导扇区最后的代码可以这样写
times 510-($-$$) db 0 db 0x55,0xaa
4. 关于8086(16位处理器)内存寻址的问题
书上的内存寻址放在很后面讲,可能是作者觉得这个东西很抽象所以挪后了,可是我觉得没什么必要,我觉得搞计算机的首先逻辑思维是没问题的,肯定要先理解这些最基本的概念才可以。
a. 寄存器寻址
这是一个最简单的寻址方式,执行指令时,操作的数位域寄存器中,可以从寄存器中获得,比如
mov ax, cx add bx, 0xf000 ;目的操作数使一个寄存器 inc dx
b. 立即寻址
当指令的操作数是一个立即数,那就是立即寻址
add bx, 0f000 mov ax, label_a ;标号就是一个立即数
c. 内存寻址
首先要明白8086处理器访问内存时,采用的是段地址左移4位,然后加上偏移地址,来形成20位的物理地址的模式,段地址由是个段寄存器之一提供,偏移地址由指令来提供,这成为有效地址(Effective Address,EA),
内存寻址只能使用BX,BP,DI,SI这四个寄存器提供偏移地址,不能使用其他寄存器来进行内存寻址,比如:
mov byte [ax+2] 0x01
是非法的。
①直接寻址:
使用该寻址方式的操作数是一个偏移地址,并且给出了该偏移地址的具体数值,如:
mov ax, [0x5c0f] add word [0x0230],0x5000 xor byte [es:label_b],0x05
②基址寻址:
所谓基址寻址,就是在指令的地址部分使用基址寄存器BX或者BP来提供偏移地址。
mov [bx], dx add byte [bx],0x55
以上代码的基址存在bx上,使用bx的段寄存器默认是DS
mov ax, [bp]
bp默认的段寄存器是SS,也就是说用BP的基址寻址常用于访问栈,可以用BP来储存SP的方法来任意访问栈的内容。
基址寻址允许在基址寄存器的基础上再加一个偏移量,这个方法既适用于BX也适用于BP,比如
mov dx,[bp-2] ;在BP的偏移量再减2
③变址寻址
变址寻址和基址寻址其实差不多,只是他使用的是变址寄存器SI和DI,比如
mov [si],dx add ax,[di]
SI和DI都是由DS提供段地址
④基址变址寻址
就是在②的基础加上③,还可以再加立即数,书上有一个很原地反转字符串的例子。
mov bx,string mov si,0 mov di,25 order: mov ah,[bx+si] mov al,[bx+di] mov [bx+si],al mov [bx+do],ah dec di inc si cmp si,di jl order ;首位相遇或者超越,退出
5. 段间批量运输数据(movsb和movsw快速批量移动指令)
movsb和movsw都是批量运输指令,只是前者是每次移动一个字节,后者每次移动一个字,这两个指令原始串的段地址由DS指定,源地址的变址索引由SI指定;目的地址的段地址由ES指定,目的地址的变址索引由DI指定,传送的字节数或者字数由CX决定,还要指定是正向传送还是反向传送(用cld命令(正向)或者std(反向)来指定,事实上这两个指令改变的是标志寄存器DF的状态,0是正向,1是反向),正向传送每一次DI和SI都会自动加1或者2,反向传送则减1或者2(movsb则为1,movsw则为2),每次传送,CX的值都会减1,而CX每一次减1都相当于是一次算数逻辑运算(经过ALU,每一次ALU除了把结果运送到指定位置,还会可能改变标志寄存器),当CX等于0,则标志寄存器的ZF会变成1,如果计算结果不为0,则ZF=0。
单次movsb和movsw都只会执行一次,所以还需要配套一个rep前缀,保证指令的重复执行。(rep movsw的操作指令是0xF3 0xA5)
rep movsb
6. 循环指令loop(机器指令0xE2,后面跟一个字节的操作数)
loop指令一般和标号结合起来形成循环,loop指令的功能是重复执行一段相同的代码,处理器在执行他的时候会顺序做两件事情:
将寄存器CX得内容-1
如果CX的内容不为0,转移到执行的位置执行,否则顺序执行后面的指令,loop的操作数也是相对于表好处的偏移量,在编译阶段,编译器loop后面的操作数减去loop的汇编地址,再减去loop的指令长度(2个字节来得到) 。
7. 自增和自减指令(inc和dec)
和c和c++的自增操作一样,inc和dec相当于给操作数+1而已,但是他比add指令+1生成的机器码更短,速度更快。
inc ax inc byte [bx]
inc和dec的目标操作数可以是8位或者16位寄存器,也可以是字节或者是字内存单元。
8. 8086的相反数指令neg和拓展符号数指令
a. neg这条指令可以快速让一个数变成其相反数(改变符号位),目的操作数可以是8位或16位的寄存器或者内存单元
neg ax neg word[leabel_a]
b.如果想把一个有符号数从8位拓展到16位,可以用cbw(Convert Byte to Word,操作码98)或者cwd(Convert Word to Double-Word,操作码99),这两个指令都没有操作数,cbw功能室将寄存器AL中的有符号数拓展到整个AX,cwd的功能则是将寄存器AX中的有符号书拓展到DX:AX。比如AX的内容是1000110110001011,则执行cwd后,DX的内容是1111111111111111,AX内容不变
9. 标志位和条件转移指令
a. 奇偶标志位PF
根据经过ALU(算术逻辑部件)的结果,如果最低八位中,右偶数个1的比特,则PF=1;否则PF=0。
b. 方向指示位DF
执行cld指令,这个位0,执行std指令,这个位位1。
c. 零标志位ZF
根据经过ALU(算术逻辑部件)的结果,如果为0,则ZF=1,否则ZF=0。
d. 符号标记位SF
根据经过ALU(算术逻辑部件)的结果,根据数的类型(8位或者是16位),把最高位的结果赋给SF。
e. 进位标志CF
根据经过ALU(算术逻辑部件)的结果,如果有向最高位进位或者结尾的发生,则CF=1,否则CF=0。
f. 溢出标志OF
根据经过ALU(算术逻辑部件)的结果,OF位的功能是,假定你在进行有符号数运算,结果超过了目标数所容纳的范围,则OF=1,否则OF=0。
g. 辅助进位标志AF
根据经过ALU(算术逻辑部件)的结果,在进行字操作时,发生低字节向高字节进位或者借位时,AF=1,否则为0。
根据经过ALU(算术逻辑部件)的结果,在进行字节操作是,发生低4位向高4位进位或者借位时,AF=1,否则为0。
h. 中断标记位IF
当IF为0时,所有来自处理器INTR引脚来的中断信号都会被忽略掉,当其为1时,处理器可以接受和响应中断。IF可以由cli(Clear Interrupt flag)和sti(Set Interrupt flag)来设定。
i. 陷阱标记位TF
当TF被设置位1时,CPU进入单步模式,所谓单步模式就是CPU在每执行一步指令后都产生一个单步中断。主要用于程序的调试。8086/8088中没有专门用来置位和清零TF的命令,需要用其他办法。
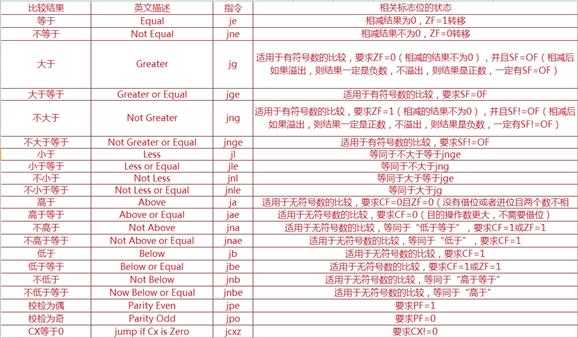
10. 条件转移指令族
条件转移指令一般要和cmp一起用或者出现在影响标志的指令后,这个指令族都是以j开头,这些指令很多意思都是相对的,比如jz是当ZF=1时,转移到相应地址,否则顺序执行;jnz是当ZF=0时,转移到相应地址,否则顺序执行。
cmp指令功能上和sub指令是一样的,但是cmp仅仅根据计算的结果来设置相应的标志位,而不保留计算结果,因此也不会改变两个操作数的原有内容,cmp指令将会影响到CD,OF,SF,ZF,AF和PF标志位。(比较是拿目的操作数和元操作数比,我们只关心目的操作数,比如cmpax,bx,我们只关心ax内容。)
11. 8086的程序栈
一个程序运行的时候需要把内容保存起来,这个时候我们就可以使用程序栈这个东西了,栈这个东西就是我们熟悉的头进头出的数据结构,和代码段,数据段一样,栈段也被定义成一个内存段,但是栈段(Stack Segment)是单独管理的,段寄存器是SS,偏移地址由SP决定,栈段操作由push和pop进行。
a. push指令
在8086处理器下,push的目的操作数可以是16位寄存器或者是内存单元(如果是内存单元,一定要注明是byte,因为8086后面的处理器是可以压入双字和四字的),比如
push ax push byte [label_a]
处理器在执行push时,首先将栈指针寄存器SP的内容减去操作数的字长(在16位处理器上是2),然后,把要压栈的数据存放找到逻辑地址SS:SP所指的内存位置,但是因为压栈过程中SP是减的,所以栈是从高地址往低地址推进的,所有在X86下运行的程序的程序栈都是一样的推进方式。
b. pop指令
和push指令类似,pop的目的操作数可以是16位寄存器或者是内存单元(如果是内存单元,一定要注明是byte,因为8086后面的处理器是可以压入双字和四字的),比如
pop ax pop byte [label_a]
处理器在执行pop指令时和push是类似的,只是SP的内容在pop中是加上2(16位处理器上),把栈中的内容放入目的操作数指定的位置。
一般情况下,应该把栈单独定义在一个64KB(16位处理器)的段,单独管理。
★PART3:5-7章一些练习例
1. 显示数位例程
jmp near start mytext: db ‘L‘,0x07,‘a‘,0x07,‘b‘,0x07,‘e‘,0x07,‘l‘,0x07,‘ ‘,0x07,‘o‘,0x07, ‘f‘,0x07,‘f‘,0x07,‘s‘,0x07,‘e‘,0x07,‘t‘,0x07,‘:‘,0x07 number: db 0,0,0,0,0 start: mov ax,0x7c0 mov ds,ax ;设定数据段 mov ax,0xb800 mov es,ax ;设定显示段 cld mov si,mytext ;源位置 mov di,0 ;目标位置 mov cx,(number-mytext)/2 rep movsw mov ax,number ;计算number的标号,等一下要用于除法 mov bx,ax mov cx,5 mov si,10 digit: xor dx,dx ;进行32位的除法 div si mov [bx],dl inc bx loop digit mov bx,number mov si,4 show: mov al,[bx+si] add al,0x30 mov ah,0x04 mov [es:di],ax add di,2 dec si jns show ;是si的内容为-1就退出,不是0 mov word [es:di],0x0744 ;显示D infi: jmp near infi times 510-($-$$) db 0 dw 0xAA55
2. 1-100的累加(1-1000的累加也就是在这个的基础上用adc指令而已,请戳)
jmp near start message db ‘1+2+3+...+100=‘ start: mov ax,0x7c0 ;设置数据段的段基地址 mov ds,ax mov ax,0xb800 ;设置附加段基址到显示缓冲区 mov es,ax ;以下显示字符串 mov si,message mov di,0 mov cx,start-message @g: mov al,[si] mov [es:di],al inc di mov byte [es:di],0x07 inc di inc si loop @g ;以下计算1到100的和 xor ax,ax mov cx,1 @f: add ax,cx inc cx cmp cx,100 jle @f ;以下计算累加和的每个数位 xor cx,cx ;设置堆栈段的段基地址 mov ss,cx mov sp,cx mov bx,10 xor cx,cx @d: inc cx xor dx,dx div bx or dl,0x30 push dx cmp ax,0 jne @d ;以下显示各个数位 @a: pop dx mov [es:di],dl inc di mov byte [es:di],0x07 inc di loop @a jmp near $ times 510-($-$$) db 0 db 0x55,0xaa
ASM:《X86汇编语言-从实模式到保护模式》5-7章相关知识
标签:
原文地址:http://www.cnblogs.com/Philip-Tell-Truth/p/5199625.html