标签:
一、NLPIR是什么?
NLPIR(汉语分词系统)由中科大张华平博士团队开发,主要功能包括:中文分词,词性标注,命名实体识别,用户词典功能,详情见官网:http://ictclas.nlpir.org/。
二、java环境下的使用:
主要参考了如下资料:http://www.360doc.com/content/14/0926/15/19424404_412519063.shtml
下面是个人的使用方法,仅供参考
1、下载NLPIR工具包,链接如下:http://ictclas.nlpir.org/newsdownloads?DocId=389
工具包中主要包含了以下内容:(待补充)
2、NLPIR是在c、c++环境下的,所以在java环境下,得下载其提供的java接口, 所以我又下载了 windows 下64位的JNI 压缩包(根据自己机器环境下载):http://ictclas.nlpir.org/newsdownloads?DocId=353
所以现在有两个文件包:NLPIR工具包,JNI接口包。
3、现在可以开始构建自己的项目了:
(1)创建一个java 项目,最后形成的目录如下图:
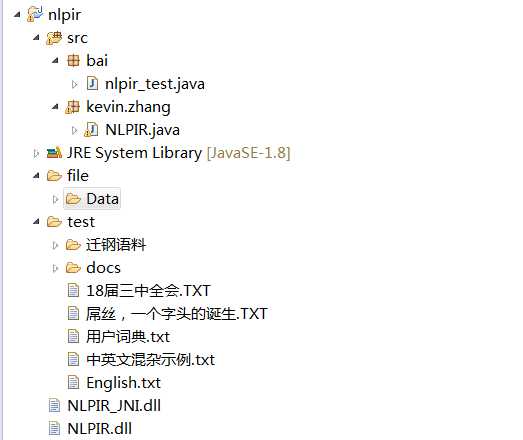
其中:bai包中的是自己写的测试程序
Kevin.zhang是64位JNI压缩包中的内容,拷贝到自己创建的java项目中
file:为自己创建的目录,Data文件是来自NLPIR工具包
test:来自NLPIR工具包
NLPIR.dll 来自NLPIR工具包lib 目录中
NLPIR_JNI.dll来自JNI接口包
4、编写分词程序
代码如下:
package bai; import kevin.zhang.NLPIR; public class nlpir_test { public static void main(String args[]) { try { test(); } catch(Exception e) { e.printStackTrace(); } } static void test()throws Exception { // TODO Auto-generated method stub //这里就是("./file/")不用修改 NLPIR nlpir=new NLPIR(); if(!NLPIR.NLPIR_Init("./file/".getBytes("UTF-8"),1)) { System.out.println("NLPIR初始化失败"); return ; } //句子分词测试 String temp="每天的日报都记得要发送, 以配合经理掌握项目的进度情况"; byte[] resBytes=nlpir.NLPIR_ParagraphProcess(temp.getBytes("UTF-8"),0); System.out.println("分词结果: "+new String(resBytes,"UTF-8")); //文件分词测试 String utf8File = "E:/wbjddata/user_product_similarity/product_vector_pro.txt"; String utf8FileResult = "E:/wbjddata/user_product_similarity/product_vector_pro_seg_result.txt"; nlpir.NLPIR_FileProcess(utf8File.getBytes(), utf8FileResult.getBytes(), 0); // 退出, 释放资源 NLPIR.NLPIR_Exit(); //nlpir.NLPIR_FileProcess,nlpir.NLPIR_ParagraphProcess中第二个参数0,表示只显示分词,不显示词性的标注 } }
标签:
原文地址:http://www.cnblogs.com/baiting/p/5224089.html