标签:
NodeJS 自 2009 年显露人间,到现在已经六个年头了,由于各种原因,中间派生出了个兄弟,叫做 iojs,最近兄弟继续合体,衍生出了 nodejs4.0 版本,这东西算是 nodejs new 1.0 版本,原班人马都统一到一个战线上。我没有太关注 nodejs 背后的开发,但一直是它的忠实使用者,通读了 v4.1.2 的 文档,感觉从开发者角度去看,也没啥大的变化,所以这两个兄弟分开这么久,主要是在底层内建模块上做改造,上层建筑尚未有大的变更,具体可以看 这篇文章。
如果你一直用着 nodejs,然而一直都在写最基本的小 demo,很少深入的去剖析 nodejs 的性能问题,甚至连如何 debug 代码、如何发现性能问题都不知从哪里下手,那么赶紧往下读吧!
命令行中调试 nodejs 代码,这是最基础的调试技能,如同我们在 Chrome 控制中调试 JS 代码一般,然而却用的很少,因为他太原始,显得比较麻烦。
回顾下,我们平时的调试方式:
console.log(),打印调试结果asserts 模块,对调试区域进行 debug这两种调试方式,都需要我们显式将各种 debug 信息嵌入到我们的业务逻辑代码中,而熟悉了命令行调试之后,我们可以更好地开启自己的调试之旅。NodeJS 给我们提供了 Debugger 模块,内建客户端,通过 TCP 将命令行的输入传送到内建模块以达到调试的目的。
在启动文件时,添加第二个参数 debug:
? $ node debug proxy2.js < Debugger listening on port 5858 debug> . ok break in proxy2.js:1 > 1 var http = require(‘http‘); 2 var net = require(‘net‘); 3 var url = require(‘url‘); debug>
调试代码的时候存在两个状态,一个是操作调试的位置,比如下一步,进入函数,跳出函数等,此时为 debug 模式;另一个是查看变量的值,比如进入循环中,想查看循环计数器 i 的值,此时为 repl(read-eval-per-line) 状态,在 debug 模式下输入 repl 即可进入 repl 状态:
debug> repl Press Ctrl + C to leave debug repl > http print something about http >
按下 Ctrl+C 可以从 repl 状态回到 debug 状态下,我们也不需要记忆 debug 状态下有多少调试命令,执行 help 即可:
debug> help Commands: run (r), cont (c), next (n), step (s), out (o), backtrace (bt), setBreakpoint (sb), clearBreakpoint (cb), watch, unwatch, watchers, repl, restart, kill, list, scripts, breakOnException, breakpoints, version
相关的命令不算很多:
| 命令 | 解释 |
|---|---|
| cont, c | 进入下一个断点 |
| next, n | 下一步 |
| step, s | 进入函数 |
| out, o | 跳出函数 |
| setBreakpoint(), sb() | 在当前行设置断点 |
| setBreakpoint(line), sb(line) | 在 line 行设置断点 |
上面几个是常用的,更多命令可以戳这里。
我们平时开发都使用 IDE 工具,实际上很多 IDE 工具已经集成了 NodeJS 的调试工具,比如 Eclipse、webStorm 等等,他们的原理依然是利用 Nodejs 的 Debugger 内建模块,在这个基础上进行了封装。
细心的同学会发现,当我们使用 debug 参数打开一个 node 文件时,会输出这样一行文案:
Debugger listening on port 5858
可以访问下 http://localhost:5858,会看到:
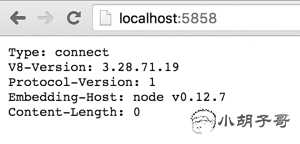
它告诉我们 nodejs 在打开文件的时候启动了内建调试功能,并且监听端口 5858 过来的调试命令。除了在命令行中直接调试之外,我们还可以通过另外两种方式去调试这个代码:
node debug <URI>, 通过 URI 连接调试,如 node debug localhost:5858node debug -p <pid> 通过 PID 链接调试如果我们使用 --debug 参数打开文件:
? $ node --debug proxy2.js
此时,nodejs 不会进入到命令行模式,而是直接执行代码,但是依然会开启内建调试功能,这就意味着我们具备了远程调试 NodeJS 代码的能力,使用 --debug 参数打开服务器的 nodejs 文件,然后通过:
? $ node debug <服务器IP>:<调试端口,默认5858>
可以在本地远程调试 nodejs 代码。不过这里需要区分下 --debug 和 --debug-brk,前者会执行完所有的代码,一般是在监听事件的时候使用,而后者,不会执行代码,需要等到外部调试接入后,进入代码区。语言表述不会那么生动,读者可以自行测试下。
默认端口号是 5858,如果这个端口被占用,程序会递增端口号,我们也可以指定端口:
? node node --debug-brk=8787 proxy2.js Debugger listening on port 8787
NodeJS 提供的内建调试十分强大,它告诉 V8,在执行代码的时候中断程度,等待开发者操控代码的执行进度。我们熟知的 node-inspector 也是用的这个原理。
? $ node-inspector --web-port 8080 --debug-port 5858
这里的 --web-port 是 Chrome Devtools 的调试页面地址端口,--debug-port 为 NodeJS 启动的内建 debug 端口,我们可以在 http://localhost:8080/debug?port=5858 打开页面,调试使用 --debug(-brk) 参数打开的程序。
更多设置可以查阅官方文档。
Eclipse 和 webstorm 的工具栏中都有一个叫做 Run 的选择栏,在这里可以配置该文件的执行方式,比如在 webstorm 中(Navigation>Run>Edit Configurations):
第一步,为程序添加一个启动程序
如果没有 Nodejs 的选项(如在 phpstorm 中),可以手动配置下。
第二步,配置执行项
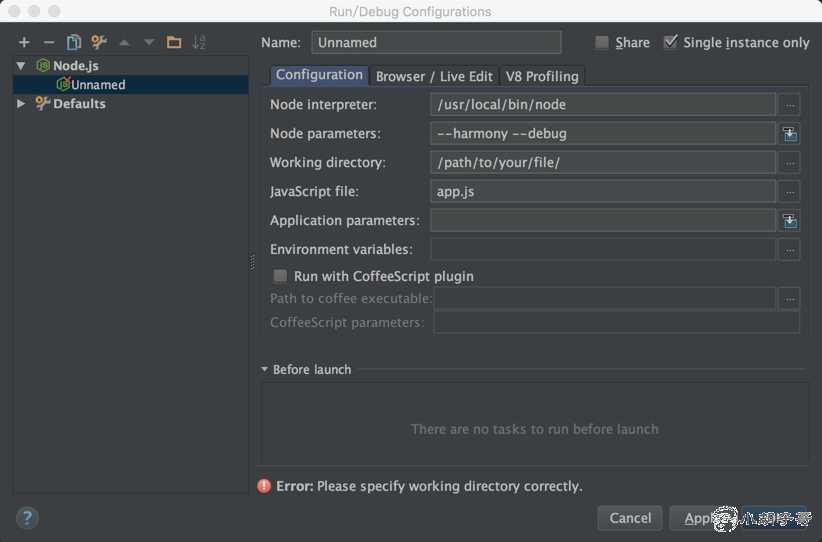
Node interpreter 是你 node 程序的位置Node parameters 是开启 nodejs 程序的选项,如果使用了 ES6 特性,需要开始 --harmony 模式,如果需要远程调试程序,可以使用 --debug 命令,我们采用控制台调试,显然是不需要添加 --debug 参数的。Working directory 是文件的目录Javascript file 是需要调试的文件第三步,断点,调试
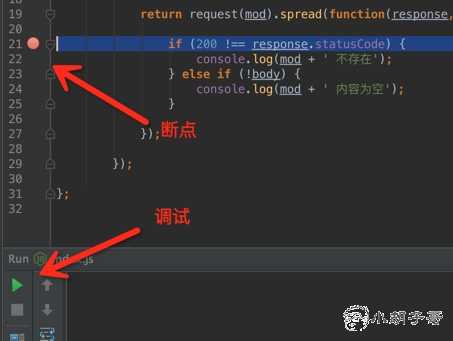
其他 IDE 工具的调试大同小异,其原理也是通过 TCP 连接到 Nodejs 开启的内建调试端口。
上面介绍了 NodeJS 调试需要掌握的几个基本技能,掌握起来还是很轻松的,但是要自己去尝试下。
Nodejs 相比 Java、PHP 这些老牌语言,其周边设施还是有所欠缺的,如性能分析和监控工具等,加上它的单线程运行特性,在大型应用中,很容易让系统的 CPU 或者内存达到瓶颈,从而导致程序崩溃。一旦发现程序警报 CPU 负载过高,或者内存飙高时,我们该如何深入排查 NodeJS 代码存在的问题呢?
首先来分析下问题,内存飙高存在哪些方面的因素呢:
CPU 负载过高预警可能因素:
这些问题是最让人头疼的,一个项目几十上百个文件,收到这些警报如果没有经验,根本无从下手排查。
最直接的手段就是分析 GC 日志,因为程序的一举一动都会反馈到 GC 上,而上述问题也会一一指向 GC,如:
这里需要稍微插一段,NodeJS 的内存管理和垃圾回收机制。
V8 的内存分为 New Space 和 Old Space,New Space 的大小默认为 8M,Old Space 的大小默认为 0.7G,64位系统这两个数值翻倍。
对象的生命周期是:首先进入 New Space,在这里,New Space 被平均分为两份,每次 GC 都会将一份中的活着的对象复制到另一份,所以它的空间使用率是 50%,这个算法叫做 Cheney 算法,这个操作叫做 Scavenge。过一段时间,如果 New Space 中的对象还活着,会被挪到 Old Space 中去,GC 会每隔一段时间遍历 Old Space 中死掉的对象,然后整理碎片(这里有两种模式 mark-sweep 和 mark-compact,不祥述)。上面提到的”死掉“,指的是对象已经没有被引用了,活着说被引用的次数为零了。
知道这些之后,我们就好分析问题了,如果缓存增加(比如使用对象缓存了很多用户信息),GC 是不知道这些缓存死了还是活着的,他们会不停地查看这个对象,以及这个对象中的子对象是否还存活,如果这个对象数特别大,那么 GC 遍历的时间也会特别长。当我们进行密集型计算的时候,会产生很多中间变量,这些变量往往在 New Space 中就死掉了,那么 GC 也会在这里多次地进行 New Space 区域的垃圾回收。
说了这么多,如何去分析 GC 的日志?
在启动程序的时候添加 --trace_gc 参数,V8 在进行垃圾回收的时候,会将垃圾回收的信息打印出来:
? $ node --trace_gc aa.js ... [94036] 68 ms: Scavenge 8.4 (42.5) -> 8.2 (43.5) MB, 2.4 ms [allocation failure]. [94036] 74 ms: Scavenge 8.9 (43.5) -> 8.9 (46.5) MB, 5.1 ms [allocation failure]. [94036] Increasing marking speed to 3 due to high promotion rate [94036] 85 ms: Scavenge 16.1 (46.5) -> 15.7 (47.5) MB, 3.8 ms (+ 5.0 ms in 106 steps since last GC) [allocation failure]. [94036] 95 ms: Scavenge 16.7 (47.5) -> 16.6 (54.5) MB, 7.2 ms (+ 1.3 ms in 14 steps since last GC) [allocation failure]. [94036] 111 ms: Mark-sweep 23.6 (54.5) -> 23.2 (54.5) MB, 6.2 ms (+ 15.3 ms in 222 steps since start of marking, biggest step 0.3 ms) [GC interrupt] [GC in old space requested]. ...
V8 提供了很多程序启动选项:
| 启动项 | 含义 |
|---|---|
| –max-stack-size | 设置栈大小 |
| –v8-options | 打印 V8 相关命令 |
| –trace-bailout | 查找不能被优化的函数,重写 |
| –trace-deopt | 查找不能优化的函数 |
这些启动项都可以让我们查看 V8 在执行时的各种 log 日志,对于排查隐晦问题比较有用。然而这堆日志并不太好看,我们可以将日志输出来之后交给专业的工具帮我们分析,相比很多人都用过 Chrome DevTools 的 JavaScript CPU Profile,它在这里:
通过 Profile 可以找到具体函数在整个程序中的执行时间和执行时间占比,从而分析到具体的代码问题,V8 也提供了 Profile 日志导出:
? $ node --prof test.js
执行命令之后,会在该目录下产生一个 *-v8.log 的日志文件,我们可以安装一个日志分析工具 tick:
? $ sudo npm install tick -g
? $ node-tick-processor *-v8.log
[Top down (heavy) profile]:
Note: callees occupying less than 0.1% are not shown.
inclusive self name
ticks total ticks total
426 36.7% 0 0.0% Function: ~<anonymous> node.js:27:10
426 36.7% 0 0.0% LazyCompile: ~startup node.js:30:19
410 35.3% 0 0.0% LazyCompile: ~Module.runMain module.js:499:26
409 35.2% 0 0.0% LazyCompile: Module._load module.js:273:24
407 35.1% 0 0.0% LazyCompile: ~Module.load module.js:345:33
406 35.0% 0 0.0% LazyCompile: ~Module._extensions..js module.js:476:37
405 34.9% 0 0.0% LazyCompile: ~Module._compile module.js:378:37
...
我们也可以使用 headdump 之类的工具将日志导出,然后放到 Chrome 的 Profile 中去分析。
本文主要从 NodeJS 程序的调试手段上,以及调试性能的入口上做了简要的介绍,希望对你有所启发,不到之处还请斧正!
标签:
原文地址:http://www.cnblogs.com/taoze/p/5224235.html