标签:
最近在使用集团内部的TimeTunnel时,想到了中间件的订阅调度策略,可能用到一致性Hash技术,所以查阅了网上其相关的博客与资料,顺便说说自己的一些粗浅理解。
1. 应用场景
如果从十几年前的文章标题”Consistent Hashing and Random Trees“中,可以看出一致性Hash算法的最初提出,是为了解决Web服务页面访问的Cache热点问题而引入的。其实一致性Hash算法已经广泛地应用在现在的web服务中,例如:
a. 外层CDN架构里的Nginx代理服务: 全球各地的用户外部访问打到后端的哪台缓存服务节点上进行请求?
b. 中间层用到的些消息中间件时: 同一个Topic的消息通常会被划分成多个Partition存在多个节点上,同时又被下游多个消费者Consumer所订阅消费,那同一个Topic的多个Partition节点如何分配给多个Consumer去消费?
c. 内层的Redis缓存服务器: 多个的缓存数据节点如何被分摊调度服务给所有不同数据的请求?
个人总结:通常在有状态的集群服务里,在满足具有Partition与Replication特征的同时,就必须得面对着多对多的分配调度策略问题;而在解决分配调度策略问题时,就可能会需要用到一致性Hash算法。
2. 动态分配调度策略特点
当面对外部用户访问时, 数据热点需求是在实时变化的; 当而面对内部服务器运营时,集群机器节点的坏掉与扩容也是随时存在的。所以直觉上我们希望调度策略具有较强的弹性,在面对任何的变化时:
a. 数据分布的单调性
当发生数据节点变动时,对于相同的数据始终映射到相同的缓冲节点中或者新增加的缓冲节点中,这样可以避免缓冲节点的数据被击穿。
b. 数据分布的稳定性
当出现节点坏掉或热点访问而需要动态扩容时,尽量减少数据的移动,在最坏情况下有可能出现所有缓存节点被击穿而溯源。
c. 数据分布的均衡性
尽量保证所有被访问节点中的缓存数据均匀分布,被充分利用,这样保证资源最大利用率。
3. 传统Hash映射缺点
在传统数据映射关系中,会用通用的式子:hashKey(Data) % DataNodeCount。从式子可以看出数据映射结果是强依赖于缓存数据总的节点个数的,当数据节点总数发生变化时,所有Data映射的结果分布可能会发生全局的变动,难以满足上述的数据分布的单调性和稳定性的特征,例如:hash(object)%12,当添加或删除服务器时,公式就会变成hash(object) % 11 或者hash(object) % 13,几乎所有的对象都会受影响。
4. 一致性Hash算法
我们希望一种算法能够解决由于少量数据节点的更新,避免出现数据节点全局”震荡“的现象。
4.1 原理
其实在实际应用场景里面,对于一个给定的Key,通常我们不用去直接关心它映射到哪些数据机器上,由于数据节点可能动态变化的;但是我们可以限制每台机器服务的Key值范围,这样可以保证:当服务机器数放生变化时,只会影响一个局部Key值区间的数据分布,而不至于影响全局数据。
一致性Hash算法其大致思路是:将数据分布与机器节点分布尽量按同一种Hash函数映射到指定的数值区间上。这样我们可以把待访问的数据分布与数据机器的分布,两者易变的因子之间通过”稳定的Hash范围值区间“这个中介来进行解耦,降低相互依赖关系,当它们按各自的维度变化时。
4.2 映射关系
a. 数据节点映射关系
public void add(T node) { circle.put(hashFunction.hash(node.toString()), node); }
b. 数据映射关系
public T get(Object key) { if (circle.isEmpty()) { return null; } int hash = hashFunction.hash(key); if (!circle.containsKey(hash)) { SortedMap<Integer, T> tailMap = circle.tailMap(hash); hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey(); } return circle.get(hash); }
类似通过就近原则,数据通过Hash始终找离它最近Hash值的数据服务器节点。例如,我们把所有数据节点划分为固定的12等分,假设你顺时针最近的数字的服务器挂掉了,就继续顺时针找下一个服务器。当有一台服务器挂掉的时候只有大约1/12的对象受到影响;当需要扩容添加服务器时,受到影响的对象也只有添加服务器逆时针到最近的服务器之间的对象受到影响。
c. 虚拟节点
通过上面的映射关系仅仅只能满足数据分布的单调与稳定性特征。由于Hash值是不均衡的,没法保证所有数据节点均衡散落在Hash的所有区间范围内,没法满足数据分布的均衡性特征。
我们把每个物理的数据节点服务器replica成多份通过相同的Hash映射到Hash各个区间范围,尽量保证所有数据节点服务器相互参插散落在各个Hash区间格子上。各个数据节点服务器上的数据分布标差与 replica的个数盗用关系图如下: 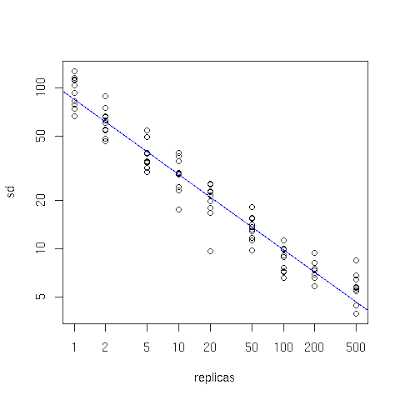
数据节点的映射关系变成如下:
public void add(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.put(hashFunction.hash(node.toString() + i), node); } }
5. 源码
参考www.tom-e-white.com源码如下:
import java.util.Collection; import java.util.SortedMap; import java.util.TreeMap; public class ConsistentHash<T> { private final HashFunction hashFunction; private final int numberOfReplicas; private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>(); public ConsistentHash(HashFunction hashFunction, int numberOfReplicas, Collection<T> nodes) { this.hashFunction = hashFunction; this.numberOfReplicas = numberOfReplicas; for (T node : nodes) { add(node); } } public void add(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.put(hashFunction.hash(node.toString() + i), node); } } public void remove(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.remove(hashFunction.hash(node.toString() + i)); } } public T get(Object key) { if (circle.isEmpty()) { return null; } int hash = hashFunction.hash(key); if (!circle.containsKey(hash)) { SortedMap<Integer, T> tailMap = circle.tailMap(hash); hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey(); } return circle.get(hash); } }
参考:
1. http://blog.csdn.net/cywosp/article/details/23397179
2. https://www.akamai.com/es/es/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf
3. http://www.tom-e-white.com//2007/11/consistent-hashing.html
4. http://www.martinbroadhurst.com/Consistent-Hash-Ring.html
标签:
原文地址:http://www.cnblogs.com/gisorange/p/5233412.html