标签:
GNU Wget 是一款免费开源的网络下载工具,它支持HTTP,HTTPS和FTP协议,功能强大而使用简单,通过它可以方便稳定地从互联网上下载大文件或是镜像拷贝整个网站。软件原本只是在Linux下跑,但现在也有windows版本了,使用起来大同小异,本文就谈谈在windows环境下wget的使用。
1 获取 wget for windows
https://eternallybored.org/misc/wget/
2 windows下运行wget
打开cmd进入下载下来的wget目录,输入命令行就可以运行wget了,语法为:
wget [option]... [ URL ]...
这里输入 wget -V 就可以看到版本信息了:
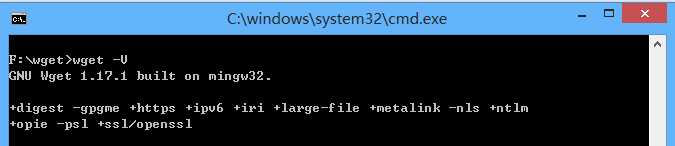
3 下载整个网站
wget -c -k -r -np -p http://www.yoursite.com/path
-c, --continue 断点下载
-k, --convert-links 将页面链接指向本地
-r, --recursive 指定目录递归下载
-np, --no-parent 不下载父目录
-p, --page-requisites 下载页面请求元素
例如,执行 "wget -c -k -r -np -p http://www.w3school.com.cn/json/",就可以下载整个w3cschool的json教程了,下载完成后cmd会有提示信息,在wget目录下即可找到刚刚下载下来的网站:
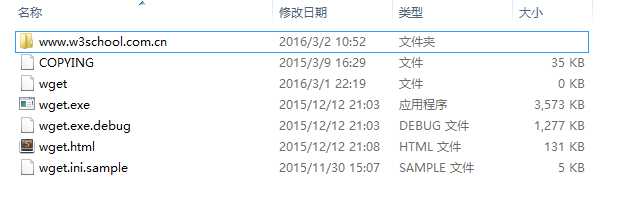
4 断点续传与重试
wget的强大之处在于,它能在本地带宽有限,或者网络不稳定的情况下保持稳定的下载,如果是由于某种原因导致下载任务断线,wget会不断地试图恢复下载,直到整个文件下载完毕,这种特性对于从有下载限制的站点下载文件非常有用。
实现断点续传的操作参数为 “-c” ,另外,如果需要限制重试次数,则要加上“-t”参数,例如限制重试次数上限为5次,则加上“-t 5”。
5 批量下载
这里要用到的操作参数是“-i”:
-i --input-file=FILE 下载本地或外部文件中的链接。
如果要下载的文件比较多,则可以新建一个文本文档如download.txt,把要下载的url一行行写进文档里,然后命令行执行“wget -i download.txt”即可。
6 wget各种选项分类列表
运行命令行”wget -help“ 可以显示wget的各种选项参数,这里整理出来便于查阅:
* 启动 -V, –version 显示wget的版本后退出 -h, –help 打印语法帮助 -b, –background 启动后转入后台执行 -e, –execute=COMMAND 执行`.wgetrc’格式的命令,wgetrc格式参见/etc/wgetrc或~/.wgetrc
* 记录和输入文件 -o, –output-file=FILE 把记录写到FILE文件中 -a, –append-output=FILE 把记录追加到FILE文件中 -d, –debug 打印调试输出 -q, –quiet 安静模式(没有输出) -v, –verbose 冗长模式(这是缺省设置) -nv, –non-verbose 关掉冗长模式,但不是安静模式 -i, –input-file=FILE 下载在FILE文件中出现的URLs -F, –force-html 把输入文件当作HTML格式文件对待 -B, –base=URL 将URL作为在-F -i参数指定的文件中出现的相对链接的前缀 –sslcertfile=FILE 可选客户端证书 –sslcertkey=KEYFILE 可选客户端证书的KEYFILE –egd-file=FILE 指定EGD socket的文件名
* 下载 –bind-address=ADDRESS 指定本地使用地址(主机名或IP,当本地有多个IP或名字时使用) -t, –tries=NUMBER 设定最大尝试链接次数(0 表示无限制). -O –output-document=FILE 把文档写到FILE文件中 -nc, –no-clobber 不要覆盖存在的文件或使用.#前缀 -c, –continue 接着下载没下载完的文件 –progress=TYPE 设定进程条标记 -N, –timestamping 不要重新下载文件除非比本地文件新 -S, –server-response 打印服务器的回应 –spider 不下载任何东西 -T, –timeout=SECONDS 设定响应超时的秒数 -w, –wait=SECONDS 两次尝试之间间隔SECONDS秒 –waitretry=SECONDS 在重新链接之间等待1…SECONDS秒 –random-wait 在下载之间等待0…2*WAIT秒 -Y, –proxy=on/off 打开或关闭代理 -Q, –quota=NUMBER 设置下载的容量限制 –limit-rate=RATE 限定下载输率
* 目录 -nd –no-directories 不创建目录 -x, –force-directories 强制创建目录 -nH, –no-host-directories 不创建主机目录 -P, –directory-prefix=PREFIX 将文件保存到目录 PREFIX/… –cut-dirs=NUMBER 忽略 NUMBER层远程目录
* HTTP 选项 –http-user=USER 设定HTTP用户名为 USER. –http-passwd=PASS 设定http密码为 PASS. -C, –cache=on/off 允许/不允许服务器端的数据缓存 (一般情况下允许). -E, –html-extension 将所有text/html文档以.html扩展名保存 –ignore-length 忽略 `Content-Length’头域 –header=STRING 在headers中插入字符串 STRING –proxy-user=USER 设定代理的用户名为 USER –proxy-passwd=PASS 设定代理的密码为 PASS –referer=URL 在HTTP请求中包含 `Referer: URL’头 -s, –save-headers 保存HTTP头到文件 -U, –user-agent=AGENT 设定代理的名称为 AGENT而不是 Wget/VERSION. –no-http-keep-alive 关闭 HTTP活动链接 (永远链接). –cookies=off 不使用 cookies. –load-cookies=FILE 在开始会话前从文件 FILE中加载cookie –save-cookies=FILE 在会话结束后将 cookies保存到 FILE文件中
* FTP 选项 -nr, –dont-remove-listing 不移走 `.listing’文件 -g, –glob=on/off 打开或关闭文件名的 globbing机制 –passive-ftp 使用被动传输模式 (缺省值). –active-ftp 使用主动传输模式 –retr-symlinks 在递归的时候,将链接指向文件(而不是目录)
* 递归下载 -r, –recursive 递归下载--慎用! -l, –level=NUMBER 最大递归深度 (inf 或 0 代表无穷). –delete-after 在现在完毕后局部删除文件 -k, –convert-links 转换非相对链接为相对链接 -K, –backup-converted 在转换文件X之前,将之备份为 X.orig -m, –mirror 等价于 -r -N -l inf -nr. -p, –page-requisites 下载显示HTML文件的所有图片
* 递归下载中的包含和不包含(accept/reject) -A, –accept=LIST 分号分隔的被接受扩展名的列表 -R, –reject=LIST 分号分隔的不被接受的扩展名的列表 -D, –domains=LIST 分号分隔的被接受域的列表 –exclude-domains=LIST 分号分隔的不被接受的域的列表 –follow-ftp 跟踪HTML文档中的FTP链接 –follow-tags=LIST 分号分隔的被跟踪的HTML标签的列表 -G, –ignore-tags=LIST 分号分隔的被忽略的HTML标签的列表 -H, –span-hosts 当递归时转到外部主机 -L, –relative 仅仅跟踪相对链接 -I, –include-directories=LIST 允许目录的列表 -X, –exclude-directories=LIST 不被包含目录的列表 -np, –no-parent 不要追溯到父目录 -S, –spider url 不下载只显示过程
参考博客:http://www.ha97.com/153.html
(本文出处——http://www.cnblogs.com/zeakhold/)
标签:
原文地址:http://www.cnblogs.com/zeakhold/p/5234361.html