标签:
Windows7下安装
1、执行easy_install Scrapy
1、库文件安装yum install libxslt-devel libxml2-devel
2、将系统自带python2.6的easy_install备份,使用python2.7.10升级后的easy_install
mv /usr/bin/easy_install /usr/bin/easy_install_2.6
ln -s /usr/local/python/2.7.10/bin/easy_install /usr/bin/easy_install
3、安装pyasn1
pip install pyasn1
4、下载libffi 编译安装
wget ftp://sourceware.org/pub/libffi/libffi-3.2.1.tar.gz
tar -zxvf libffi-3.2.1.tar.gz
cd libffi-3.2.1
./configure
make
make install
环境变量配置
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
LD_LIBRARY_PATH加入/usr/local/lib64
4、安装cryptography
pip install cryptography
5、安装Scrapy
easy_install Scrapy
6、备份python2.6的scrapy
mv /usr/bin/scrapy /usr/bin/scrapy2.6
7、使用python2.7.10的scrapy
ln -s /usr/local/python/2.7.10/bin/scrapy /usr/bin/scrapy
参考
http://www.cnblogs.com/rwxwsblog/p/4557123.html?utm_source=tuicool&utm_medium=referral
http://www.cnblogs.com/txw1958/archive/2012/07/12/scrapy_installation_introduce.html
介绍
所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的HTML数据。不过由于一个网站 的网页很多,而我们又不可能事先知道所有网页的URL地址,所以,如何保证我们抓取到了网站的所有HTML页面就是一个有待考究的问题了。
一般的方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新新页面后再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
上面介绍的只是爬虫的一些概念而非搜索引擎,实际上搜索引擎的话其系统是相当复杂的,爬虫只是搜索引擎的一个子系统而已。下面介绍开源的爬虫框架Scrapy。
Scrapy是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便,并且官网上说已经在实际生产中在使用了,不过现在还没有 Release 版本,可以直接使用他们的 Mercurial 仓库里抓取源码进行安装。
Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
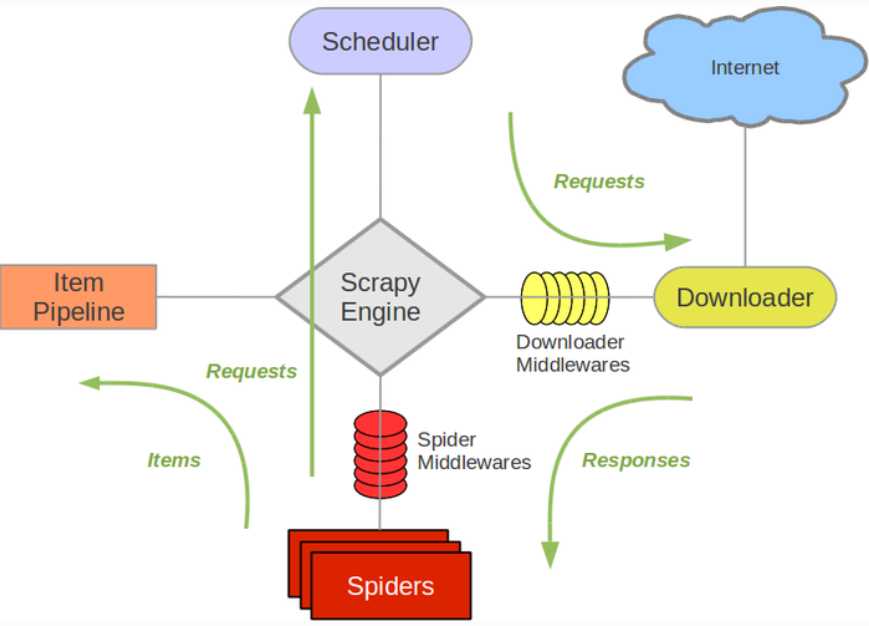
绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
1、Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
2、Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
3、Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
4、Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
蜘蛛的整个抓取流程(周期)是这样的:
5、Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
6、Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展 Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
7、Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功 能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
8、Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
参考
http://blog.sina.com.cn/s/blog_72995dcc0101kgty.html
http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/architecture.html
标签:
原文地址:http://www.cnblogs.com/shhnwangjian/p/5241061.html