标签:
本篇将会详细地介绍Apache公司的JDBC帮助工具类DbUtils以及如何使用。在上一篇中我们已经通过将以前对dao层使用JDBC操作数据库的冗余代码进行了简易封装形成自己的简单工具类JdbcUtils,而在这过程中很多都是借鉴和参考了DbUtils的代码,因此通过上一篇的学习,会让我们在对DbUtils进行更快速简单的认识。
俗话说学习一个开源的工具最好的方法就是看其官方文档,是的,在Apache官网中对DbUtils进行了详细的介绍:http://commons.apache.org/proper/commons-dbutils/ 。(或者下载了DbUtils的jar中也有相应文档)
DbUtils是一些类组成的用于简化JDBC开发的库,解决我们以前根据“模板”代码写出的大部分的冗余部分,将我们的代码进行最大程度的简化,使我们只关心于查询和更新(包括添加、修改和删除)数据。就好像上一篇博客中我们重点写的query和update方法。
DbUtils能做些什么?虽然JDBC代码不难,但是根据我们以前所写的“模板”代码费时又费力,非常容易丢失链接并且难以追寻,而使用DbUtils基本不会发生资源泄露(比如链接的丢失)。当然和上一篇博文相同,DbUtils也提供了一个对结果集处理的接口ResultSetHandler,我们可以实现这个接口来对结果集进行处理,也可以使用DbUtils提供的实现类,例如BeanHandler或者BeanListHandler等等,有很多实用的结果集处理器类。如果有一些公司不使用hibernate的话一般会选用DbUtils。
DbUtils最主要的就两个,QueryRunner类和ResultSetHandler接口。
QueryRunner类这个类主要用于提供各种重载形式的batch方法、query方法和update 方法,其中update 方法包含添加、删除和修改。
QueryRunner并不算一个静态工具类,因此我们要使用必须先创建一个QueryRunner类的对象,而这就有两种构造器,分别是无参的和有参的,其中有参的构造器接收一个连接池对象DataSource。

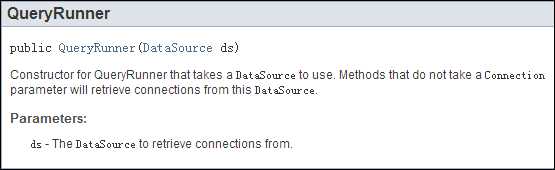
可以从手册中看到,如果在创建QueryRunner对象时给定了一个连接池对象,那么在一些不需要Connection对象为参数的方法被调用时会从连接池中自动获取连接,调用完后会将连接重新返回到连接池中;而对于无参的构造器来说,在调用方法时必须指定Connection对象,同时调用完方法后Connection对象的处理要自己负责。
下面就看看对于无参和有参的QueryRunner对象的各种重载形式的query方法和update方法:

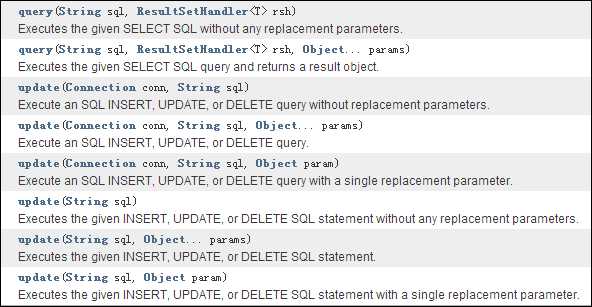
可以看到这些方法中主要就分为两种,一种是有Connection对象参数的,一种是无Connection对象参数的。上面已经说过了,无Connection对象参数的方法是从有参QueryRunner的连接池中获取链接,同时会自动将连接返还给连接池。而有Connection参数的方法由调用者负责关闭连接,这种方法看似麻烦,但是由多条SQL组成的事务进行整体执行却是必须的,因为我们不需要只执行一条SQL就还给连接池。
除了query方法和update方法,QueryRunner类还有一个batch方法,用于执行SQL批处理:

这个方法用于对某一条SQL执行多次,而我们提供给这个方法的参数中是一个二维数组,那么怎么用呢?
比如“insert into user(id,name,age) values(?,?,?)”这样的SQL语句,batch方法中的二维数组参数就可以是 [ [1,”Ding”,25],[2,”LRR”,24] ] 这样的形式,也就是批处理执行两次,而每次的参数都不同。
上面的介绍基本就是QueryRunner的全部,当然QueryRunner只是DbUtils的一部分,而另一部分在于QueryRunner中query方法参数中的ResultSetHandler接口,用于处理结果集,这一点上一篇博客已经讲述的很清楚了。而在DbUtils中为我们已经写好了更多的这个接口的实现类:
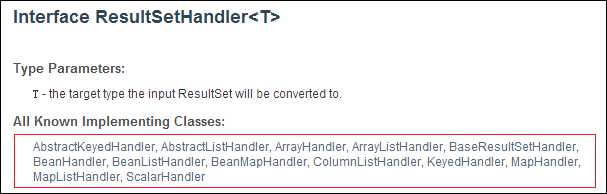
除了我们上一篇博客自己动手实现的BeanHandler和BeanListHandler之外,在DbUtils中可以使用便捷的结果集处理器还有
ArrayHandler:把结果集中的第一行数据封装进对象数组中。
ArrayListHandler:把结果集中的每一行数据封装进数组,再将这些数组存进List集合中。
ColumnListHandler:将结果集中的某一列所有的数据存进List集合中。
KeyedHandler:将结果集中的每一行数据封装进一个Map中,再把这些Map存到一个Map里,其Key为指定的Key。
MapHandler:将结果集中的第一行数据封装进Map里,Key为列名,value就是对应的值。
MapListHandler:将结果集中的每一行数据封装到Map中,再将这些Map存放进List中。
记得上一篇博客中我们在JDBC工具类JdbcUtils中重点创建的自定义的update方法和query方法吗(上一篇博客的第四点和第五点),那只是为了我们将冗余代码进行封装,而在本篇中我们可以在JdbcUtils中删了这里两个方法,而直接在dao层中使用DbUtils进行低层的增删改查。
例1:
那么在下面的代码中就对上一篇博客最后的UserDao中的增删改查进行重构:

1 public class UserDao {
2 // 添加用户
3 public void add(User user) throws SQLException {
4 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
5 String sql = "insert into user(id,name,age) values(?,?,?)";
6 Object[] params = { user.getId(), user.getName(), user.getAge() };
7 qr.update(sql, params);
8 }
9
10 // 删除用户
11 public void delete(int id) throws SQLException {
12 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
13 String sql = "delete from user where id=?";
14 Object params = id;
15 qr.update(sql, params);
16 }
17
18 // 修改用户
19 public void update(User user) throws SQLException {
20 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
21 String sql = "update user set name=?,age=? where id=?";
22 Object[] params = { user.getName(), user.getAge(), user.getId() };
23 qr.update(sql, params);
24 }
25
26 // 查找某个用户
27 public User find(int id) throws SQLException {
28 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
29 String sql = "select * from user where id=?";
30 Object params = id;
31 User user = qr.query(sql, new BeanHandler<>(User.class), params);
32 return user;
33 }
34
35 // 列出所有用户
36 public List<User> getAllUser() throws SQLException {
37 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
38 String sql = "select * from user";
39 List<User> list = qr.query(sql, new BeanListHandler<>(User.class));
40 return list;
41 }
42 }
可以看到使用QueryRunner就将我们的增删改查语句变得非常简单,同时我们在工具类JdbcUtils中也不用另外再写update方法和query方法,在JdbcUtils中主要是创建连接池。由于我们在创建QueryRunner对象时使用了DataSource作为参数,这样我们在使用无Connection对象的update方法和query方法都可以不用指定连接,同时这些方法会将我们的连接自动放回连接池,因此我们在JdbcUtils甚至都可以不用写释放资源的代码(当然具体情况具体分析)。
例2:
再补充一个使用DbUtils的批处理batch方法的demo:
public void batchInsertTest() throws SQLException {
QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
String sql = "insert into user(id,name,age) values(?,?,?)";
Object[][] params = new Object[5][3];
for(int i=0;i<params.length;i++) {
params[i] = new Object[]{i+1,"aa"+i,25+i};
}
qr.batch(sql, params);
}
结果如下:
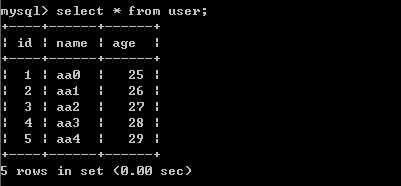
关于DbUtils中的QueryRunner类就差不多介绍完了,主要就是batch、query和update 方法。
而对于结果集处理器类,DbUtils给我们提供了很多针对ResultSetHandler接口的实现类,如果这些实现类都不能满足我们的需要,我们也可以实现ResultSetHandler接口来制作我们所需要功能的实现类。
例3:
下面使用DbUtils中的结果集处理器类之一的ArrayHandler类来简单演示下demo(以上面批处理batch方法调用后的数据库中数据为例):
1 public void arrayHandlerTest() throws SQLException {
2 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
3 String sql = "select * from user";
4 Object[] firstUser = qr.query(sql, new ArrayHandler());
5 for(Object o:firstUser) {
6 System.out.println(o);
7 }
8 }
ArrayHandler类只将结果集的第一行数据封装进一个对象数组中,在控制台观察:
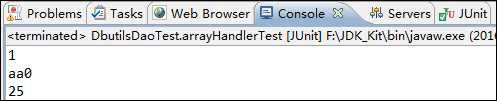
例4:
有时候我们需要计算一张表中的总记录数,例如在使用数据库进行分页的时候就需要知道有多少数据,那么将查询结果以结果集返回也可以使用ArrayHandler简单处理,因为数组的第一个元素就是查询结果,但下面的代码看似没有问题,却在运行时会抛出异常:
1 public void countTest() throws SQLException {
2 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
3 String sql = "select count(*) from user";
4 Object[] result = qr.query(sql, new ArrayHandler());
5 int count = (int) result[0];
6 System.out.println(count);
7 }
异常原因:

也就是说在MySQL中以count方法在JDBC中是以Long类型返回查询的数值,因此我们不能只用Integer类型。这点要注意,但是总记录数不大时可以将Long类型强制转换为Integer类型:
1 public void countTest() throws SQLException {
2 QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource());
3 String sql = "select count(*) from user";
4 Object[] result = qr.query(sql, new ArrayHandler());
5 int count = ((Long)result[0]).intValue();
6 System.out.println(count);
7 }
当然还有其他的很实用的结果集处理器类,这里就不一一介绍了。本篇对DbUtils的讲解就结束了,对于DbUtils的使用是很简单的,只要掌握了QueryRunner类和ResultSetHandler接口及其实现类,就能很好的掌握DbUtils。
标签:
原文地址:http://www.cnblogs.com/fjdingsd/p/5273374.html
