标签:
http://www.cnblogs.com/alex3714/articles/5227251.html
Socket语法及相关
socket概念
A network socket is an endpoint of a connection across a computer network. Today, most communication between computers is based on the Internet Protocol; therefore most network sockets are Internet sockets. More precisely, a socket is a handle (abstract reference) that a local program can pass to the networking application programming interface (API) to use the connection, for example "send this data on this socket". Sockets are internally often simply integers, which identify which connection to use.
For example, to send "Hello, world!" via TCP to port 80 of the host with address 1.2.3.4, one might get a socket, connect it to the remote host, send the string, then close the socket:
A socket API is an application programming interface (API), usually provided by the operating system, that allows application programs to control and use network sockets. Internet socket APIs are usually based on the Berkeley sockets standard. In the Berkeley sockets standard, sockets are a form of file descriptor (a file handle), due to the Unix philosophy that "everything is a file", and the analogies between sockets and files: you can read, write, open, and close both. In practice the differences mean the analogy is strained, and one instead use different interfaces (send and receive) on a socket. In inter-process communication, each end will generally have its own socket, but these may use different APIs: they are abstracted by the network protocol.
A socket address is the combination of an IP address and a port number, much like one end of a telephone connection is the combination of a phone number and a particular extension. Sockets need not have an address (for example for only sending data), but if a program binds a socket to an address, the socket can be used to receive data sent to that address. Based on this address, internet sockets deliver incoming data packets to the appropriate application process or thread.
Socket Families(地址簇)
socket.AF_UNIX unix本机进程间通信
socket.AF_INET IPV4
socket.AF_INET6 IPV6
These constants represent the address (and protocol) families, used for the first argument to socket(). If the AF_UNIX constant is not defined then this protocol is unsupported. More constants may be available depending on the system.
Socket Types
socket.SOCK_STREAM #for tcp
socket.SOCK_DGRAM #for udp
socket.SOCK_RAW #原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。
socket.SOCK_RDM #是一种可靠的UDP形式,即保证交付数据报但不保证顺序。SOCK_RAM用来提供对原始协议的低级访问,在需要执行某些特殊操作时使用,如发送ICMP报文。SOCK_RAM通常仅限于高级用户或管理员运行的程序使用。
socket.SOCK_SEQPACKET #废弃了
These constants represent the socket types, used for the second argument to socket(). More constants may be available depending on the system. (Only SOCK_STREAM and SOCK_DGRAM appear to be generally useful.)
Socket 方法
socket.socket(family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None)
Create a new socket using the given address family, socket type and protocol number. The address family should be AF_INET (the default), AF_INET6, AF_UNIX, AF_CAN or AF_RDS. The socket type should beSOCK_STREAM (the default), SOCK_DGRAM, SOCK_RAW or perhaps one of the other SOCK_ constants. The protocol number is usually zero and may be omitted or in the case where the address family is AF_CAN the protocol should be one of CAN_RAW or CAN_BCM. If fileno is specified, the other arguments are ignored, causing the socket with the specified file descriptor to return. Unlike socket.fromfd(), fileno will return the same socket and not a duplicate. This may help close a detached socket using socket.close().
socket.socketpair([family[, type[, proto]]])
Build a pair of connected socket objects using the given address family, socket type, and protocol number. Address family, socket type, and protocol number are as for the socket() function above. The default family is AF_UNIX if defined on the platform; otherwise, the default is AF_INET.
socket.create_connection(address[, timeout[, source_address]])
Connect to a TCP service listening on the Internet address (a 2-tuple (host, port)), and return the socket object. This is a higher-level function than socket.connect(): if host is a non-numeric hostname, it will try to resolve it for both AF_INET and AF_INET6, and then try to connect to all possible addresses in turn until a connection succeeds. This makes it easy to write clients that are compatible to both IPv4 and IPv6.
Passing the optional timeout parameter will set the timeout on the socket instance before attempting to connect. If no timeout is supplied, the global default timeout setting returned by getdefaulttimeout() is used.
If supplied, source_address must be a 2-tuple (host, port) for the socket to bind to as its source address before connecting. If host or port are ‘’ or 0 respectively the OS default behavior will be used.
socket.getaddrinfo(host, port, family=0, type=0, proto=0, flags=0) #获取要连接的对端主机地址
sk.bind(address)
s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。
sk.listen(backlog)
开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
backlog等于5,表示内核已经接到了连接请求,但服务器还没有调用accept进行处理的连接个数最大为5
这个值不能无限大,因为要在内核中维护连接队列
sk.setblocking(bool)
是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
sk.accept()
接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。
接收TCP 客户的连接(阻塞式)等待连接的到来
sk.connect(address)
连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.connect_ex(address)
同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061
sk.close()
关闭套接字
sk.recv(bufsize[,flag])
接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.recvfrom(bufsize[.flag])
与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.send(string[,flag])
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。即:可能未将指定内容全部发送。
sk.sendall(string[,flag])
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
内部通过递归调用send,将所有内容发送出去。
sk.sendto(string[,flag],address)
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
sk.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 client 连接最多等待5s )
sk.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
sk.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
sk.fileno()
套接字的文件描述符
socket.sendfile(file, offset=0, count=None)
发送文件 ,但目前多数情况下并无什么卵用。
SocketServer
The socketserver module simplifies the task of writing network servers.
There are four basic concrete server classes:
class socketserver.TCPServer(server_address, RequestHandlerClass, bind_and_activate=True)This uses the Internet TCP protocol, which provides for continuous streams of data between the client and server. If bind_and_activate is true, the constructor automatically attempts to invoke server_bind() andserver_activate(). The other parameters are passed to the BaseServer base class.
class socketserver.UDPServer(server_address, RequestHandlerClass, bind_and_activate=True)This uses datagrams, which are discrete packets of information that may arrive out of order or be lost while in transit. The parameters are the same as for TCPServer.
class socketserver.UnixStreamServer(server_address, RequestHandlerClass, bind_and_activate=True)class socketserver.UnixDatagramServer(server_address, RequestHandlerClass,bind_and_activate=True)These more infrequently used classes are similar to the TCP and UDP classes, but use Unix domain sockets; they’re not available on non-Unix platforms. The parameters are the same as for TCPServer.
These four classes process requests synchronously; each request must be completed before the next request can be started. This isn’t suitable if each request takes a long time to complete, because it requires a lot of computation, or because it returns a lot of data which the client is slow to process. The solution is to create a separate process or thread to handle each request; the ForkingMixIn and ThreadingMixIn mix-in classes can be used to support asynchronous behaviour.
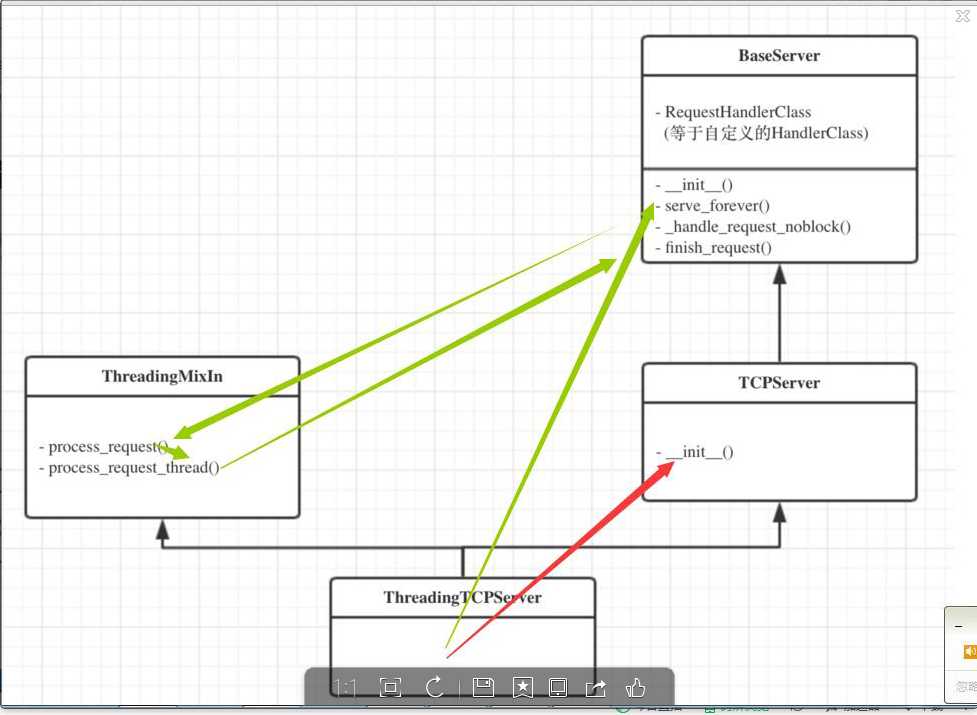
There are five classes in an inheritance diagram, four of which represent synchronous servers of four types:
+------------+
| BaseServer |
+------------+
|
v
+-----------+ +------------------+
| TCPServer |------->| UnixStreamServer |
+-----------+ +------------------+
|
v
+-----------+ +--------------------+
| UDPServer |------->| UnixDatagramServer |
+-----------+ +--------------------+
Note that UnixDatagramServer derives from UDPServer, not from UnixStreamServer — the only difference between an IP and a Unix stream server is the address family, which is simply repeated in both Unix server classes.
class socketserver.ForkingMixInclass socketserver.ThreadingMixInForking and threading versions of each type of server can be created using these mix-in classes. For instance, ThreadingUDPServer is created as follows:
class ThreadingUDPServer(ThreadingMixIn, UDPServer):
pass
The mix-in class comes first, since it overrides a method defined in UDPServer. Setting the various attributes also changes the behavior of the underlying server mechanism.
class socketserver.ForkingTCPServerclass socketserver.ForkingUDPServerclass socketserver.ThreadingTCPServerclass socketserver.ThreadingUDPServerThese classes are pre-defined using the mix-in classes.
Request Handler Objects
class socketserver.BaseRequestHandler
This is the superclass of all request handler objects. It defines the interface, given below. A concrete request handler subclass must define a new handle() method, and can override any of the other methods. A new instance of the subclass is created for each request.
setup()Called before the handle() method to perform any initialization actions required. The default implementation does nothing.
handle()This function must do all the work required to service a request. The default implementation does nothing. Several instance attributes are available to it; the request is available as self.request; the client address as self.client_address; and the server instance as self.server, in case it needs access to per-server information.
The type of self.request is different for datagram or stream services. For stream services,self.request is a socket object; for datagram services, self.request is a pair of string and socket.
finish()Called after the handle() method to perform any clean-up actions required. The default implementation does nothing. If setup() raises an exception, this function will not be called.
socketserver.TCPServer Example
server side
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
"""
The request handler class for our server.
It is instantiated once per connection to the server, and must
override the handle() method to implement communication to the
client.
"""
def handle(self):
# self.request is the TCP socket connected to the client
self.data = self.request.recv(1024).strip()
print("{} wrote:".format(self.client_address[0]))
print(self.data)
# just send back the same data, but upper-cased
self.request.sendall(self.data.upper())
if __name__ == "__main__":
HOST, PORT = "localhost", 9999
# Create the server, binding to localhost on port 9999
server = socketserver.TCPServer((HOST, PORT), MyTCPHandler)
# Activate the server; this will keep running until you
# interrupt the program with Ctrl-C
server.serve_forever()
client side
import socket
import sys
HOST, PORT = "localhost", 9999
data = " ".join(sys.argv[1:])
# Create a socket (SOCK_STREAM means a TCP socket)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
# Connect to server and send data
sock.connect((HOST, PORT))
sock.sendall(bytes(data + "\n", "utf-8"))
# Receive data from the server and shut down
received = str(sock.recv(1024), "utf-8")
finally:
sock.close()
print("Sent: {}".format(data))
print("Received: {}".format(received))
上面这个例子你会发现,依然不能实现多并发,哈哈,在server端做一下更改就可以了
把
server = socketserver.TCPServer((HOST, PORT), MyTCPHandler)改成
server = socketserver.ThreadingTCPServer((HOST, PORT), MyTCPHandler)
####################################################################################################################
异常处理
try:
xxxxx
except Exception as e:
xxxxxx
print(e)
else:
xxxxxx
finally:
xxxxx
Exception这个错误类是基类,大部分的错误信息都能抓到,但不是所有错误信息都能抓到,比如indention, syntax, keyboardinterrupt, etc.
自定义异常

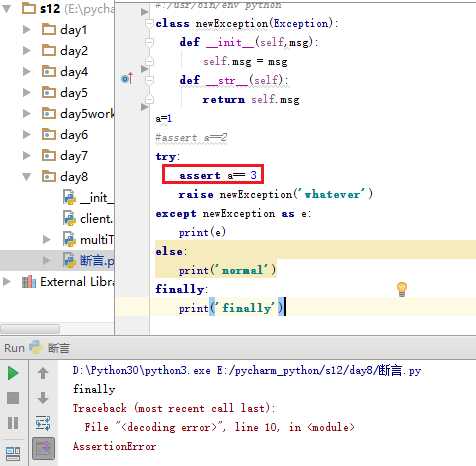
断言 assert --- > 条件判断, 不符合就跳出,无法往下执行。上面例子因为在try里面,所以无论如何都执行finally
##########################################################################################
进程与线程
什么是线程(thread)?
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions.
Suppose you‘re reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers.
If you have a roommate, and she‘s using the same technique, she can take the book while you‘re not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were.
Threads work in the same way. A CPU is giving you the illusion that it‘s doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU.
On a more technical level, an execution context (therefore a thread) consists of the values of the CPU‘s registers.
Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads.
Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
什么是进程(process)?
An executing instance of a program is called a process.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
进程与线程的区别?
1. Threads share the address space of the process that created it; processes have their own address space.
2. Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
3. Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
4. New threads are easily created; new processes require duplication of the parent process.
5. Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
6. Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
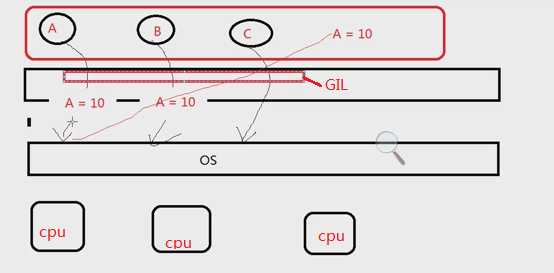
Python GIL(Global Interpreter Lock)
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
上面的核心意思就是,无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行,擦。。。,那这还叫什么多线程呀?莫如此早的下结结论,听我现场讲。
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
这篇文章透彻的剖析了GIL对python多线程的影响,强烈推荐看一下:http://www.dabeaz.com/python/UnderstandingGIL.pdf
###############################################################################
线程直接调用
#!/usr/bin/env python
import threading
import time
def hi(num):
print("numbers: %s"%num)
time.sleep(3)
ali = []
for i in range(10):
t = threading.Thread(target=hi,args=[i,]) #生成线程
t.start() #执行线程
print(t.getName())
ali.append(t)
for x in ali:
x.join() #相当于让这个线程执行完,等待线程执行完毕
print(‘the end.....‘)
还有线程继承式调用
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == ‘__main__‘:
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
join and Daemon m.setDaemon(True) #将主线程设置为Daemon线程,它退出时,其它子线程会同时退出,不管是否执行完任务

import time
import threading
def run(n):
print(‘[%s]------running----\n‘ % n)
time.sleep(2)
print(‘--done--‘)
def main():
for i in range(5):
t = threading.Thread(target=run,args=[i,])
#time.sleep(1)
t.start()
#t.join(1)
print(‘starting thread‘, t.getName())
m = threading.Thread(target=main,args=[])
m.setDaemon(True) #将主线程设置为Daemon线程,它退出时,其它子线程会同时退出,不管是否执行完任务
m.start()
#m.join(timeout=3)
print("---main thread done----")
线程锁(互斥锁Mutex)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况?
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print(‘--get num:‘,num )
time.sleep(1)
num -=1 #对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print(‘final num:‘, num )
正常来讲,这个num结果应该是0, 但在python 2.7上多运行几次,会发现,最后打印出来的num结果不总是0,为什么每次运行的结果不一样呢? 哈,很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
加锁版本:
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print(‘--get num:‘,num )
time.sleep(1)
lock.acquire() #修改数据前加锁
num -=1 #对此公共变量进行-1操作
lock.release() #修改后释放
num = 100 #设定一个共享变量
thread_list = []
lock = threading.Lock() #生成全局锁
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print(‘final num:‘, num )
线程锁和GIL区别: GIL保证同意时刻只有一个线程在运行,保证的是底层C代码线程API的同一时刻只有一个线程运行,线程锁保证python运行的内存空间数据的一致性,加了线程锁后对数据的操作只有这一个线程能修改,变成串行又不是并行了。
RLock(递归锁)
说白了就是在一个大锁中还要再包含子锁. 如果涉及到多个线程前后运行,都有获取和释放锁的行为,也就是说有好几把锁的情况,用RLock. 不容易出错,如果这时还用Lock,则可能系统搞混淆了。
其实都可以用RLock替代Lock
import threading,time
def run1():
print("grab the first part data")
lock.acquire()
global num
num +=1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2+=1
lock.release()
return num2
def run3():
lock.acquire() #要有三把锁啊
res = run1()
print(‘--------between run1 and run2-----‘)
res2 = run2()
lock.release()
print(res,res2)
if __name__ == ‘__main__‘:
num,num2 = 0,0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print(‘----all threads done---‘)
print(num,num2)
Semaphore(信号量)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading,time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s\n" %n)
semaphore.release()
if __name__ == ‘__main__‘:
num= 0
semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
while threading.active_count() != 1:
pass #print threading.active_count()
else:
print(‘----all threads done---‘)
print(num)
Events
An event is a simple synchronization object;
the event represents an internal flag, and threads
can wait for the flag to be set, or set or clear the flag themselves.
event = threading.Event()
# a client thread can wait for the flag to be set
event.wait()
# a server thread can set or reset it
event.set()
event.clear()
If the flag is set, the wait method doesn’t do anything.
If the flag is cleared, wait will block until it becomes set again.
Any number of threads may wait for the same event.
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则
import threading,time
import random
def light():
if not event.isSet():
event.set() #wait就不阻塞 #绿灯状态
count = 0
while True:
if count < 10:
print(‘\033[42;1m--green light on---\033[0m‘)
elif count <13:
print(‘\033[43;1m--yellow light on---\033[0m‘)
elif count <20:
if event.isSet():
event.clear()
print(‘\033[41;1m--red light on---\033[0m‘)
else:
count = 0
event.set() #打开绿灯
time.sleep(1)
count +=1
def car(n):
while 1:
time.sleep(1)
if event.isSet(): #绿灯
print("car [%s] is running.." % n)
else:
print("car [%s] is waiting for the red light.." %n)
event.wait()
if __name__ == ‘__main__‘:
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in range(3):
t = threading.Thread(target=car,args=(i,))
t.start()
#############################################################################
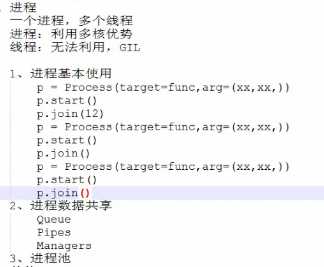
多进程multiprocessing
multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency, effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine. It runs on both Unix and Windows.
from multiprocessing import Process
import time
import os
def f(name):
time.sleep(2)
print(‘hello‘, name)
def info(title):
print(title)
print(‘parent process,‘,os.getppid())
print(‘current process id,‘,os.getpid())
if __name__ == ‘__main__‘:
p = Process(target=f, args=(‘bob‘,))
p.start()
p.join()
info(‘\033[32;1mmain process line\033[0m‘)
p1 = Process(target=info, args=(‘bob‘,))
p1.start()
p1.join()
进程间通讯
不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用以下方法:
Queues
使用方法跟threading里的queue差不多
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, ‘hello‘])
if __name__ == ‘__main__‘:
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, ‘hello‘]"
p.join()
Pipes
The Pipe() function returns a pair of connection objects connected by a pipe which by default is duplex (two-way). For example:
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, ‘hello‘])
conn.close()
if __name__ == ‘__main__‘:
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, ‘hello‘]"
p.join()
The two connection objects returned by Pipe() represent the two ends of the pipe. Each connection object has send() and recv() methods (among others). Note that data in a pipe may become corrupted if two processes (or threads) try to read from or write to the same end of the pipe at the same time. Of course there is no risk of corruption from processes using different ends of the pipe at the same time.
Managers
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array. For example,
from multiprocessing import Process, Manager
def f(d, l):
d[1] = ‘1‘
d[‘2‘] = 2
d[0.25] = None
l.append(1)
print(l)
if __name__ == ‘__main__‘:
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list = []
for i in range(10):
p = Process(target=f, args=(d, l))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
进程同步
Without using the lock output from the different processes is liable to get all mixed up.
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print(‘hello world‘, i)
finally:
l.release()
if __name__ == ‘__main__‘:
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
apply
apply_async
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print(‘-->exec done:‘,arg)
pool = Pool(5)
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
#pool.apply(func=Foo, args=(i,))
print(‘end‘)
pool.close()
pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
######################################################################################
标签:
原文地址:http://www.cnblogs.com/joey251744647/p/5295355.html