标签:
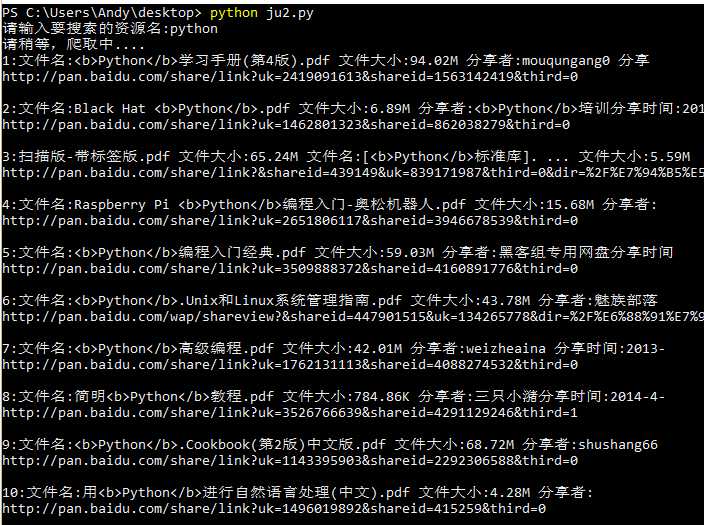
1 import urllib.request 2 import re 3 import random 4 5 def get_source(key): 6 7 print(‘请稍等,爬取中....‘) 8 headers = [{‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36‘},{‘User-Agent‘:"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0"},{‘User-Agent‘: ‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 10.0; WOW64; Trident/7.0)‘}] 9 10 header = random.choice(headers) # 随机选取一个header 11 12 keyword = key.encode(‘utf-8‘) 13 keyword = urllib.request.quote(keyword) # 对关键词进行编码 14 15 # 这里是关键,称随机搜索一个资源名,然后对其结果网址进行分析 16 url = "http://www.wangpansou.cn/s.php?wp=0&ty=gn&op=gn&q="+keyword+"&q="+keyword 17 req = urllib.request.Request(url, headers=header) 18 19 html = urllib.request.urlopen(req) 20 21 # 编码类型 22 head_type = html.headers[‘Content-Type‘].split(‘=‘)[-1] 23 24 25 status = html.getcode() # 获取状态码,只有访问成功了才继续。 26 if status == 200: 27 html = html.read() 28 html = html.decode(head_type) # 根据网站编码时行解码 29 30 # 正则匹配 31 pattern = re.compile(‘<a href="(.+)"><div class="cse-search-result_paging_num " tabindex="\d{1,3}">\d{1,3}</div></a>‘) 32 content = pattern.findall(html) 33 34 url_list = [] 35 url_head = ‘http://www.wangpansou.cn/‘ 36 for i in content: 37 i = url_head +i # 因为正匹配出来的只有一部分,所以把前面的一部分加上,开成完整的链接 38 if not i in url_list: # 去掉重复的,网页确实有两分,所以去重. 39 url_list.append(i) # 得到所有 有搜索结果的页面网址列表 40 41 count = 1 # 计数用 42 for each_url in url_list: 43 header = random.choice(headers) # 针对每个链接都随机选择一个‘头‘,防止被服务器封掉 44 request1 = urllib.request.Request(each_url, headers=header) 45 html2 = urllib.request.urlopen(request1) 46 47 status = html2.getcode() # 获取状态码 48 if status == 200: 49 html2 = html2.read() 50 html2 = html2.decode(head_type) 51 pattern1 = re.compile(‘<a class=".+" href="(.+)" rel.+‘) 52 content1 = pattern1.findall(html2) 53 54 55 pattern2 = re.compile(‘<div id=".+" class="cse-search-result_content_item_mid">\s+(.+)‘) 56 content2 = pattern2.findall(html2) 57 58 59 for i in range(0,len(content2)): 60 print(str(count) + ‘:‘ + content2[i] + ‘\n‘ + content1[i]) 61 print() 62 count += 1 63 64 print(‘共搜索到%d个资源,已经全部爬取完毕!‘ % count) 65 66 if __name__ == ‘__main__‘: 67 get_source(input(‘请输入要搜索的资源名:‘))
"""
说明:
a.本搜索实际是通过通过网盘搜这个网站进行的二次搜索,如果找资源也可以直接到网盘搜进行一页一页的搜索
本脚本唯一的优点是一次性将所有结果全部爬下来,不用一页一页的翻找。
b.代码相当丑,但这也是对学习过程的记录,先实现功能,再考虑代码。
"""
标签:
原文地址:http://www.cnblogs.com/Andy963/p/5304603.html