标签:
首先创建在Android工程中创建一个Assets文件夹 app/src/main/assets
在这里添加一个名为 data.xml的文件,然后编辑这个文件,加入如下XML格式内容
<?xml version="1.0" encoding="utf-8"?> <apps> <app> <id>1</id> <name>Google Maps</name> <version>1.0</version> </app> <app> <id>2</id> <name>Chrome</name> <version>2.1</version> </app> <app> <id>3</id> <name>Google play</name> <version>2.3</version> </app> </apps>
==============获取XML中内容================
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); try { //获取XML文件的输入流 InputStream fis = getResources().getAssets().open("data.xml"); InputStreamReader isr = new InputStreamReader(fis, "UTF-8"); StringBuffer stringBuffer = new StringBuffer(); int mark = -1; while ((mark = isr.read()) != -1) { stringBuffer.append((char) mark); } String data = stringBuffer.toString(); //把整个文件内容以String方式传入 //parseXMLWithPull(data); //parseXMLWithSAX(data); } catch (IOException e) { e.printStackTrace(); } }
==============Pull解析方式=================
获取解析工具XmlPullParser:
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser xmlPullParser = factory.newPullParser();
传入XML字符流:
xmlPullParser.setInput(new StringReader(xmlData));
根据节点特征进行处理:
switch ( xmlPullParser.getEventType() )

private void parseXMLWithPull(String xmlData) { try { XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); XmlPullParser xmlPullParser = factory.newPullParser(); xmlPullParser.setInput(new StringReader(xmlData)); int eventType = xmlPullParser.getEventType(); String id = ""; String name = ""; String version = ""; while (eventType != xmlPullParser.END_DOCUMENT) { String nodeName = xmlPullParser.getName(); switch (eventType) { //开始解析某个节点 case XmlPullParser.START_TAG: { if ("id".equals(nodeName)) { id = xmlPullParser.nextText(); } else if ("name".equals(nodeName)) { name = xmlPullParser.nextText(); } else if ("version".equals(nodeName)) { version = xmlPullParser.nextText(); } } break; //完成解析某个节点 case XmlPullParser.END_TAG: { if ("app".equals(nodeName)) { Log.d("woider", "id is " + id); Log.d("woider", "name is " + name); Log.d("woider", "version is " + version); } } break; } eventType = xmlPullParser.next(); } } catch (Exception e) { e.printStackTrace(); } }
==============SAX解析方式=================
使用SAX解析通常需要创建一个类继承DefaultHandler,并重写父类的五个方法
startDocument():开始XML解析的时候调用
startElement():开始解析某个结点的时候调用
characters():获取节点中内容的时候调用
endElement():完成解析某个节点的时候调用
endDocument():完成整个XML解析的时候调用
public class ContentHandler extends DefaultHandler { private String nodeName; private StringBuilder id; private StringBuilder name; private StringBuilder version; @Override public void startDocument() throws SAXException { id = new StringBuilder(); name = new StringBuilder(); version = new StringBuilder(); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //记住当前结点名 nodeName = localName; } @Override public void characters(char[] ch, int start, int length) throws SAXException { //进行格式规范化 String str = new String(ch, start, length).trim(); //根据当前节点名添加内容 if ("id".equals(nodeName)) { id.append(str); } else if ("name".equals(nodeName)) { name.append(str); } else if ("version".equals(nodeName)) { version.append(str); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { if ("app".equals(localName)) { Log.d("woider", "id is " + id); Log.d("woider", "name is " + name); Log.d("woider", "version is " + version); //清空StringBuilder id.setLength(0); name.setLength(0); version.setLength(0); } } @Override public void endDocument() throws SAXException { } }
获取解析工具XMLReader:
SAXParserFactory factory = SAXParserFactory.newInstance();
XMLReader xmlReader = factory.newSAXParser().getXMLReader();
传入规则到解析工具:
ContentHandler handler = new ContentHandler();
xmlReader.setContentHandler(handler);
开始执行解析:
xmlReader.parse(new InputSource(new StringReader(xmlData)));
private void parseXMLWithSAX(String xmlData) { try { SAXParserFactory factory = SAXParserFactory.newInstance(); XMLReader xmlReader = factory.newSAXParser().getXMLReader(); ContentHandler handler = new ContentHandler(); //将ContentHandler的实例设置到XMLReader中 xmlReader.setContentHandler(handler); //开始执行解析 xmlReader.parse(new InputSource(new StringReader(xmlData))); } catch (Exception e) { e.printStackTrace(); } }
方法二(直接针对InputStream解析)
获取解析工具SAXParser:
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
获取规则和输入流:
handler = new ParserHandler();
InputStream inputStream = getResources().getAssets().open("data.xml");
同时传入开始解析:
parser.parse(inputStream, handler);
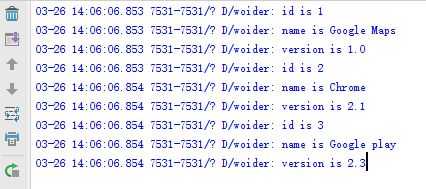
最后打印 LogCat 中的日志,data.xml的解析就完成了
除了 Pull 解析和 SAX 解析之外,还有一种 DOM 解析也非常重要。
另外还有一些XML解析工具,比如 JDOM 和 DOM4J,它们简化了解析的步骤,提高了解析的效率。
标签:
原文地址:http://www.cnblogs.com/woider/p/5322762.html
