标签:
最近遇到一个需求,就是要从一个英语句子分析的页面中,根据你输入的英语从句,点击开始分析按钮,这个页面就会将分析的结果解析出来,如
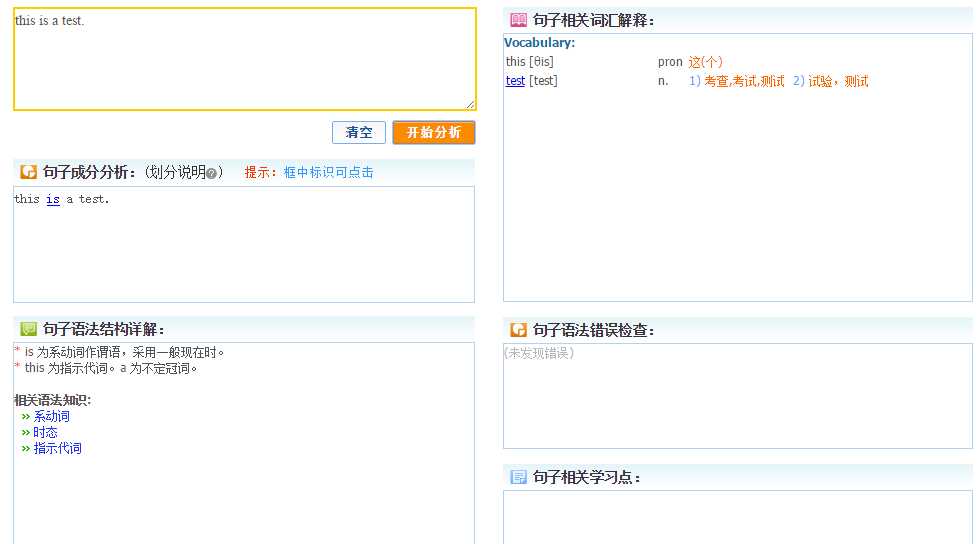
然后我们就是需要从这个页面中把这些解析好的数据(包括句子语法结构详解,句子相关词汇解释等)取出来,这时候我就想到之前学过node.js,这时候就来弄下node.js的小小的爬虫。
首先,电脑要先安装node.js,至于怎么安装,请google,或者找相关教程来看。
然后就需要了解下node,现在我先加载http模块,然后设置url的值,url就是你要爬的那个网页的地址啦
然后通过http.get获得数据,现在我应该把代码粘贴上来啦。
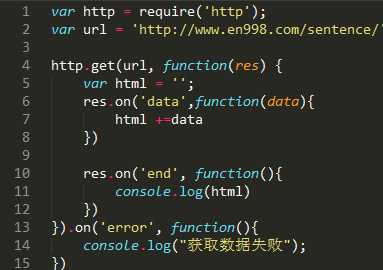
然后我是保存为crawler_english.js文件的,然后就在命令行中运行了,敲node crawler_english.js,无拼写什么意外的话,就把全部页面都打印出来啦。
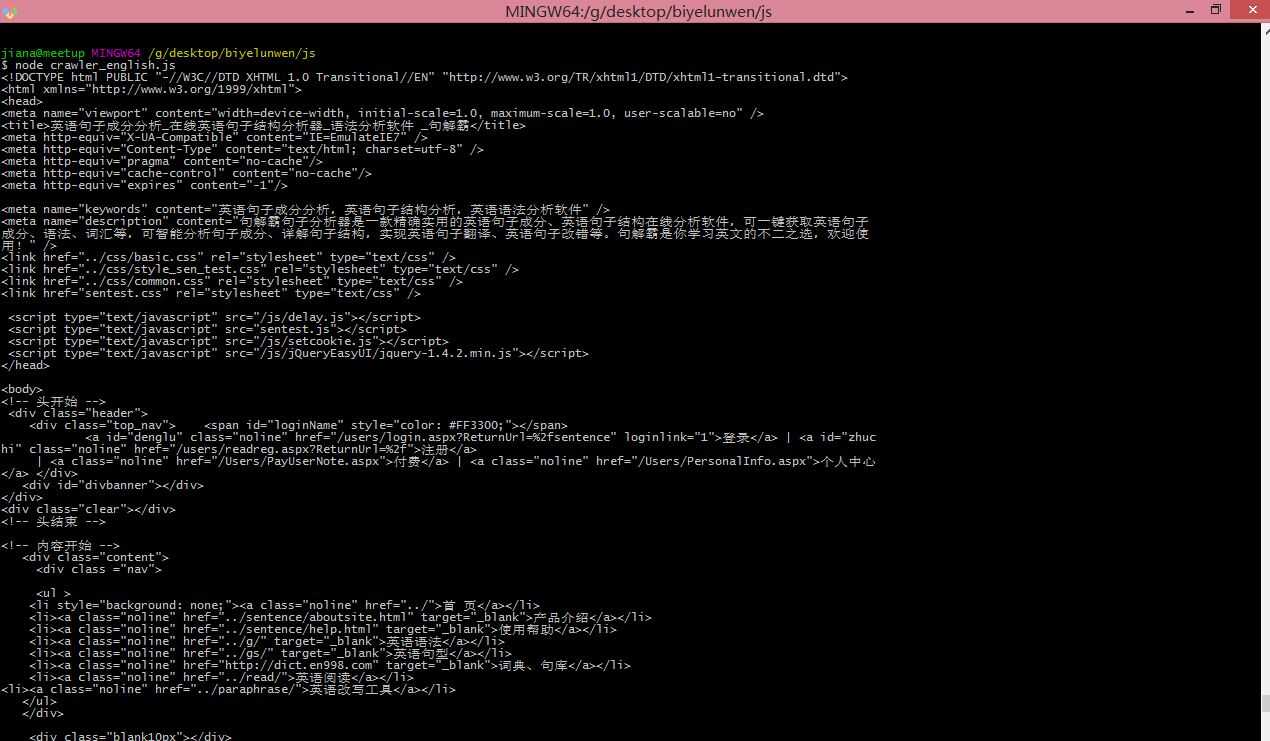
铛铛铛铛,获取数据之后就要开始解析了。
据说解析dom结构用cheerio这个模块比较好,我就npm install cheerio了这个模块
然后 var cheerio = require(‘cheerio‘);将这个模块加载进来。
首先我要获取的是句子成分分析、句子语法结构详解、句子相关词汇解释、句子语法错误检查和句子相关学习点下的内容,这时候我就要找下他们的id,之后进行解析,解析过程就不说了。

标签:
原文地址:http://www.cnblogs.com/meetup/p/5270994.html