标签:
刚做的时候根本就没有想到解题思路,刚好看到了别人的思路,自己写了一下。里面对unordered_map及vector二维数组的建立很灵活,另外区别了一下map,unordered_map,hash_map;但是没有弄清楚unordered_map,hash_map的区别。以后遇到了在细细研究。
//小明陪小红去看钻石,他们从一堆钻石中随机抽取两颗并比较她们的重量。这些钻石的重量各不相同。在他们们比较了一段时间后, //它们看中了两颗钻石g1和g2。现在请你根据之前比较的信息判断这两颗钻石的哪颗更重。 //给定两颗钻石的编号g1, g2,编号从1开始,同时给定关系数组vector, 其中元素为一些二元组,第一个元素为一次比较中较重的钻石的编号, //第二个元素为较轻的钻石的编号。最后给定之前的比较次数n。请返回这两颗钻石的关系,若g1更重返回1,g2更重返回 - 1,无法判断返回0。 //输入数据保证合法,不会有矛盾情况出现。 // // //测试样例: // //2, 3, [[1, 2], [2, 4], [1, 3], [4, 3]], 4 //返回: 1 //思路: //就是一个森林,关系存在就是以g2为根节点的树下面的节点中有g1, //或者以g1为根节点的树的下面的节点包含g2 //我们采取层序遍历的方式遍历以g1开头的整棵树,和以g2开头的整棵树. #include<iostream> #include<vector> #include<unordered_map> #include<queue> using namespace std; class Cmp { bool judge(int g1,int g2,unordered_map<int,vector<int>> ans) //判断是否有记录 { //查找g1是否比g2重 queue<int> q; unordered_map<int, bool> mark;//用于标记当前节点是否遍历过 q.push(g1); while (!q.empty()) { int cur = q.front(); q.pop(); mark[cur] = true; if (cur==g2) //钻石的重量各不相同,g1和g2不可能相同 { return true; } for (size_t i = 0; i < ans[cur].size(); i++) { if (!mark[ans[cur][i]]) //没有遍历过 // 2->4->3 q.push(ans[cur][i]); } } } public: int cmp(int g1,int g2,vector<vector<int>> records,int n) { unordered_map<int, vector<int>> ans; for (size_t i = 0; i < n; i++) //赋值 { ans[records[i][0]].push_back(records[i][1]); } if (judge(g1,g2,ans)) { return 1; } else { if (judge(g2, g1, ans)) { return -1; } else return 0; } } }; int main() { int g1 = 2, g2 = 3,n=4; vector<vector<int>> records; vector<int> a = { 1, 2 }, b = { 2, 4 }, c = { 1, 3 }, d = { 4, 3 }; records.push_back(a); records.push_back(b); records.push_back(c); records.push_back(d); Cmp chooseWeighter; chooseWeighter.cmp(g1,g2,records,n); return 0; }
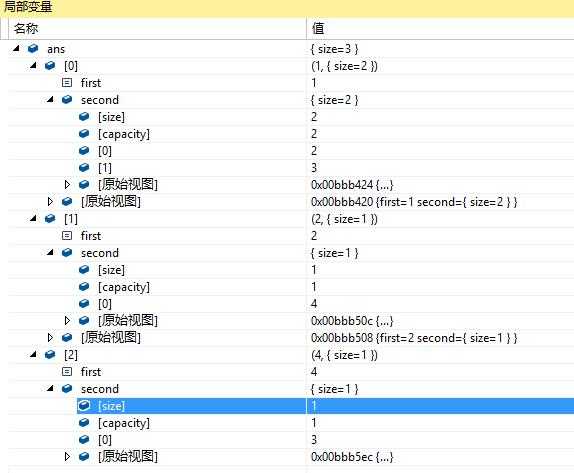
根据ans的内存情况,我们可以推断
unordered_map<int,vector<int>> ans的用法,特别是
ans[cur][i]的表示。
标签:
原文地址:http://www.cnblogs.com/ranjiewen/p/5328646.html