标签:style blog http java color 使用 strong 文件
使用Apache POI eventmodel实现一个Excel流式读取类,目标是100万,每行46列,文件大小152MB的Excel文件能在20s读取并处理完。一开始实现的程序需要260s,离目标差太远了,使用jvisualvm分析各方法执行时间,结果如下:
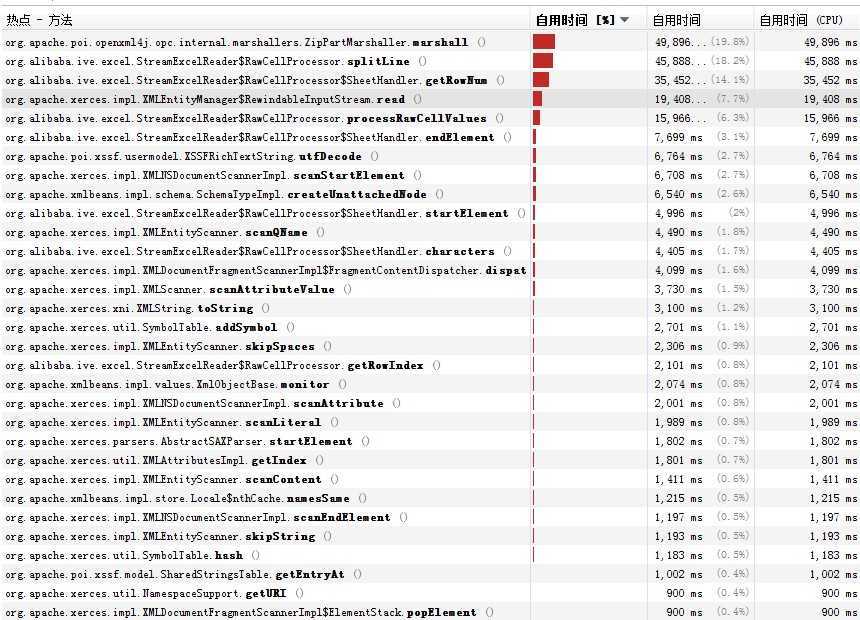
可以看到,程序中的splitLine和getRowNum方法消耗了大量时间。这两个方法都特别简单。splitLine方法将类似“123==hello”这样的字符串分解成{"123","hello"}数组,使用了String.split方法,getRowNum从Excel单元格地址字符串(比如“AB123456”)中获取行号“123456”,以下是原始实现方法:
private String getRowNum(String cellRef){ if(cellRef == null || cellRef == ""){ return "-1"; } String[] nums = cellRef.split("\\D+"); if(nums.length > 1){ return nums[1]; } return "-1; } private String[] splitLine(String line){ return line.split("=="); }
两个如此简单的方法却消耗了这么多时间,一时间不知如何优化。最后突然想到:split的性能是否最优呢?对于如此简单的字符串分割,使用indexOf + subString性能如何呢?于是,我做了如下的实验:
public static void main(String[] args) throws ParseException{ String str = "AB123456"; long start = System.currentTimeMillis(); for(int i = 0 ; i < 10 * 10000 ; i ++){ String[] lines = str.split("\\D+"); } long end = System.currentTimeMillis(); System.out.println("split time consumed:" + (end - start) / 1000.0 + "s"); start = System.currentTimeMillis(); int index = -1; for(int i = 0 ; i < 10 * 10000 ; i ++){ index = -1; for(int k = 0 ; k < str.length() ; k ++){ if(str.charAt(k) >= ‘0‘ && str.charAt(k) <= ‘9‘){ index = k; break; } } if(index > 0){ String[] lines = new String[]{str.substring(0, index),str.substring(index)}; } } end = System.currentTimeMillis(); System.out.println("indexof time consumed:" + (end - start) / 1000.0 + "s"); }
以下是输出结果:
split time consumed:0.104s
indexof time consumed:0.007s
虽然表面上看,split比index + subString要简单很多,但后者性能是前者的将近15倍。用这种方法改写前面的splitLine和getRowNum,代码如下:
private String getRowNum(String cellRef){ int index = -1; for(int k = 0 ; k < cellRef.length() ; k ++){ if(cellRef.charAt(k) >= ‘0‘ && cellRef.charAt(k) <= ‘9‘){ index = k; break; } } if(index >= 0){ String[] nums = new String[]{cellRef.substring(0, index),cellRef.substring(index)}; if(nums.length > 1){ return nums[1]; } } return "-1"; } private String[] splitLine(String line){ int index = line.indexOf("=="); if(index > 0){ return new String[]{line.substring(0, index),line.substring(index + 2)}; } return new String[0]; }
优化后再用jvisualvm测试各方法执行时间: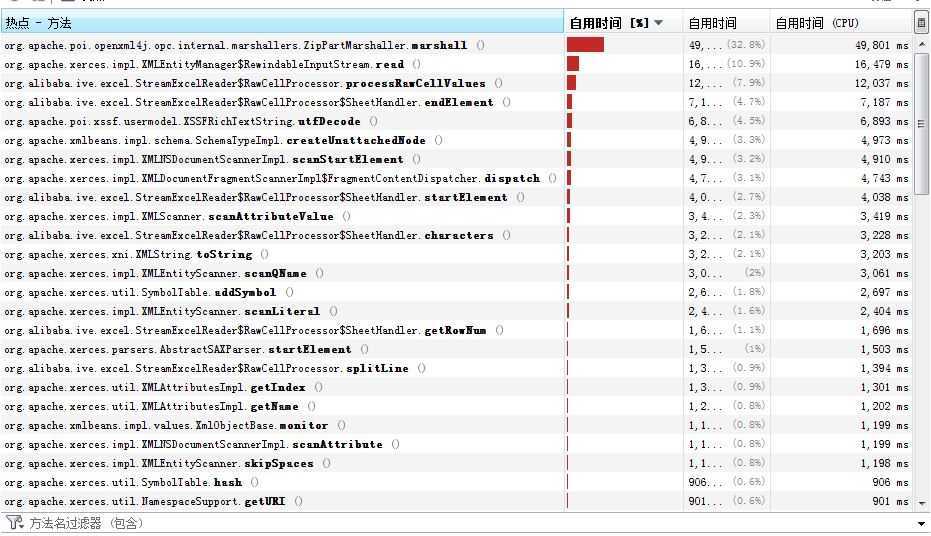
可以看到,我自己的数据处理方法已不是明显的性能瓶颈,而Apache POI的zip解压和文件读取占用了绝大部分时间。整体时间也从260s下降到了160s,已有了明显的提高。
想一想我过去写的代码经常图方便滥用String.split,这样是经不起大数据量考验的,学了这么长时间Java,竟从没想过这样的问题,不禁感叹自己还是菜鸟。虽然像Java或C#这种语言各种方法使用起来方便,但其库方法之下隐藏的性能开销,需要每一个使用者注意。
(全文完)
Apache POI Java读取100万行Excel性能优化:split vs indexOf+subString,谁性能好,布布扣,bubuko.com
Apache POI Java读取100万行Excel性能优化:split vs indexOf+subString,谁性能好
标签:style blog http java color 使用 strong 文件
原文地址:http://www.cnblogs.com/ahhuiyang/p/3871918.html