标签:
第一次爬去https://segmentfault.com/t/python?type=newest&page=1
首先定义爬去的字段:
class CnblogsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
listUrl = scrapy.Field()
编写爬虫:
#coding:utf-8
#! /usr/bin/python
‘‘‘
Author fiz
Date:2016-03-30
‘‘‘
#coding:utf8
from scrapy.selector import HtmlXPathSelector
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor as sle
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.http import FormRequest, Request
from scrapy.selector import Selector
from Scrapy_demo.items import *
from scrapy import log
from scrapy.utils.response import get_base_url
class SgfSpider(CrawlSpider):
name = ‘sgf‘
allowed_domains = [‘segmentfault.com‘]
start_urls = [‘https://segmentfault.com/t/python?type=newest&page=1‘,]
#此处注意?要转义
rules = [ Rule(sle(allow=(‘/t/python\?type=newest&page=\d{1,}‘),), follow=True,callback=‘parse_item1‘) ]
def parse_item1(self, response):
sel = Selector(response)
items = []
base_url = get_base_url(response)
postTitle = sel.css(‘div.tab-content‘).css("section")#全部的问题数量每一页
postCon = sel.css(‘div.postCon div.c_b_p_desc‘)
# #标题、url和描述的结构是一个松散的结构,后期可以改进
for index in range(len(postTitle)):
item = CnblogsItem()
#问题名称
item[‘title‘] = postTitle[index].css("a").xpath(‘text()‘).extract()[0]
# item[‘link‘] = ‘https://segmentfault.com‘+postTitle[index].css(‘a‘).xpath(‘@href‘).extract()[0]#提问人的主页链接
#问题页面链接
item[‘link‘] = ‘https://segmentfault.com‘+postTitle[index].css("h2.title").css(‘a‘).xpath(‘@href‘).extract()[0]
#当前爬去的页面
item[‘listUrl‘] = base_url
item[‘desc‘] = postTitle[index].css("div.answers ").xpath("text()").extract()[0]
#print base_url + "********\n"
items.append(item)
return items
编写PIPlines
#coding:utf-8
#! /usr/bin/python
‘‘‘
Author fiz
Date:2016-03-31
‘‘‘
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline( object ):
def __init__( self ):
connection = pymongo.MongoClient()
db = connection[settings[ ‘MONGODB_DB‘ ]]
self .collection = db[settings[ ‘MONGODB_COLLECTION‘ ]]
def process_item( self , item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem( "Missing {0}!" . format (data))
if valid:
self .collection.insert( dict (item))
log.msg( "Question added to MongoDB database!" ,
level = log.DEBUG, spider = spider)
return item
结果爬去了3456条数据源码在https://github.com/FizLBQ/SpiderPython/tree/Scrapy_demo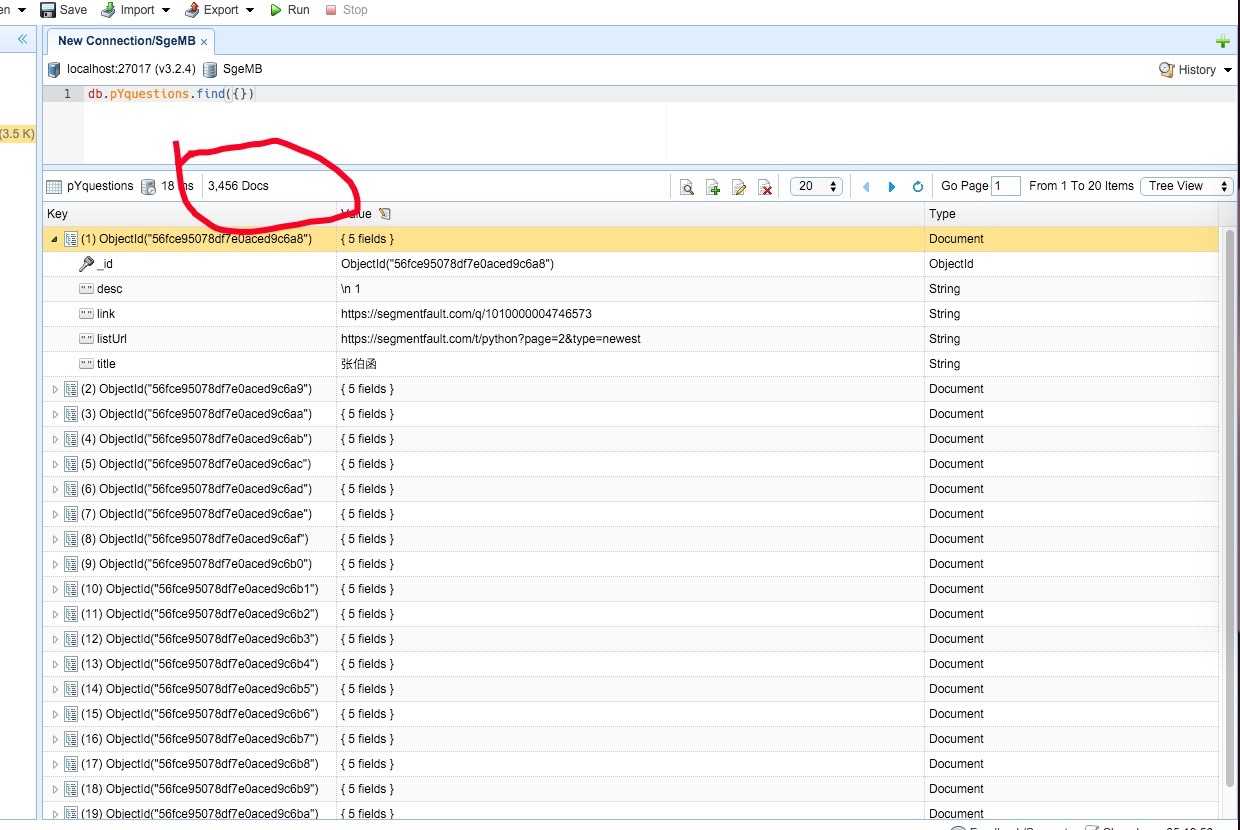
标签:
原文地址:http://www.cnblogs.com/linbinqiang/p/5341920.html