标签:
课程主页:http://cs231n.stanford.edu/
?
Introduction to neural networks



-Training Neural Network

_____________________________________________________________________________________________________________________________________________________________________________
-Activation Functions

为什么要把线性转换为非线性?
引用ufldl:


*sigmoid neuron
?

(引自:http://blog.csdn.net/han_xiaoyang/article/details/50447834):
0中心化,这是一个比较闹心的事情,因为每一层的输出都要作为下一层的输入,而未0中心化会直接影响梯度下降,我们这么举个例子吧,如果输出的结果均值不为0,举个极端的例子,全部为正的话(例如
*tanh

Tanh函数的图像如上图所示。它会将输入值压缩至-1到1之间,当然,它同样也有sigmoid函数里说到的第一个缺点,在很大或者很小的输入值下,神经元很容易饱和。但是它缓解了第二个缺点,它的输出是0中心化的。所以在实际应用中,tanh激励函数还是比sigmoid要用的多一些的。
*ReLU

ReLU是修正线性单元(The Rectified Linear Unit)的简称,近些年使用的非常多,图像如上图所示。它对于输入x计算![]() f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。?
f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。?
它有它对应的优势,也有缺点:
 ?
?流经ReLU单元,那权重的更新结果可能是,在此之后任何的数据点都没有办法再激活它了。一旦这种情况发生,那本应经这个ReLU回传的梯度,将永远变为0。当然,这和参数设置有关系,所以我们要特别小心,再举个实际的例子哈,如果学习速率被设的太高,结果你会发现,训练的过程中可能有高达40%的ReLU单元都挂掉了。所以我们要小心设定初始的学习率等参数,在一定程度上控制这个问题。
上面不是提到ReLU单元的弱点了嘛,所以孜孜不倦的ML researcher们,就尝试修复这个问题咯,他们做了这么一件事,在x<0的部分,leaky ReLU不再让y的取值为0了,而是也设定为一个坡度很小(比如斜率0.01)的直线。f(x)因此是一个分段函数,x<0时,![]() f(x)=αx(α是一个很小的常数),x>0时,
f(x)=αx(α是一个很小的常数),x>0时,![]() f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。
f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。

也有一些其他的激励函数,它们并不是对![]() WTX+b做非线性映射
WTX+b做非线性映射![]() f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算
f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算![]() max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把
max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把![]() w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。
w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。

以上就是我们总结的常用的神经元和激励函数类型。顺便说一句,即使从计算和训练的角度看来是可行的,实际应用中,其实我们很少会把多种激励函数混在一起使用。
那我们咋选用神经元/激励函数呢?一般说来,用的最多的依旧是ReLU,但是我们确实得小心设定学习率,同时在训练过程中,还得时不时看看神经元此时的状态(是否还『活着』)。当然,如果你非常担心神经元训练过程中挂掉,你可以试试Leaky ReLU和Maxout。额,少用sigmoid老古董吧,有兴趣倒是可以试试tanh,不过话说回来,通常状况下,它的效果不如ReLU/Maxout。
_____________________________________________________________________________________________________________________________________________________________________________
-Data Preprocessing
*Preprocess the data


?
*Weight Initialization

learning nothing
随机生成初始W值:

?
导致反向传递时,由于需要计算对w的偏导,由于x的值太小,所以乘到最前面的层时,结果几乎为0.


但是,如果用relu作为激活函数时,


*batch normalisation
以下引自知乎:
 关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.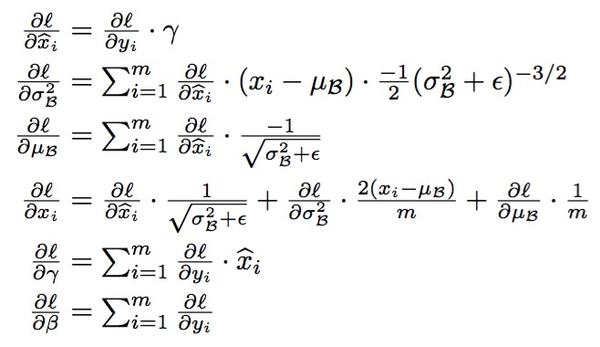
链接:https://www.zhihu.com/question/38102762/answer/85238569
来源:知乎?

_____________________________________________________________________________________________________________________________________________________________________________
check:




_________________________________________________________________________________
Hyperparameter Optimization










标签:
原文地址:http://www.cnblogs.com/XBWer/p/5342869.html