标签:
本文略微有些长,花了好几晚时间编辑修改,若在措辞排版上有问题,请谅解。本文共分为四篇,下面是主要内容,也是软件开发基本流程。
|
阶段 |
描述 |
|
需求分析 |
主要描述实现本程序的目的及对需求进行分析,即为什么要花时间来编写,需要哪些功能等; |
|
方案设计 |
根据现有的需求,设计出一个可行的方案(即使可能还存在某些问题),用户需要输入什么,程序需要处理什么,数据库、功能、界面的设计等; |
|
编程实现 |
通过.NET编程实现图标批量下载的功能,重点分析其中遇到的问题及解决的方法。 |
|
成果展示 |
展示分享实现的工具及成果,小结经验。 |
在平时的程序开发中,为了快速搭建较为美观的用户界面,经常要下载一些图标作为按钮、控件等的外观,甚至需要自己动手制作一些特定的图标或图片。自己动力,不得不说需要一定的技术和审美功底;下载,又得到网上到处找,找到一套适合主题、色彩、尺寸、美观大方的图标还真是一件不容易的事。
幸好,网上有很多专门下载图标的网站,常用的有:
这些网站各有各的优点,共同点是都包含大量图标,我个人比较喜欢在EasyIcon上去搜索,下载,也很喜欢它的网址。它有优点有:
(1)支持中英文搜索。EasyIcon支持中文和英文的搜索,当然,它的原始图标名称还是英文,只不过在搜索前,利用百度翻译API将中文翻译成英文,再进行搜索。
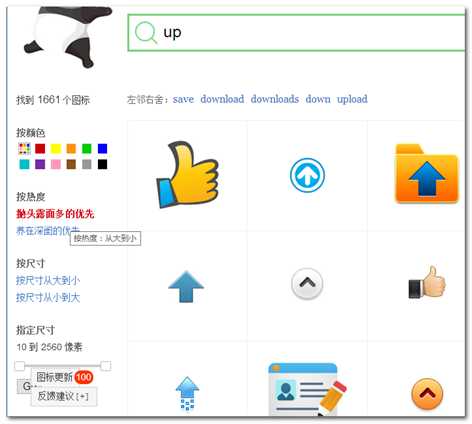
(2)用户体验好。很多网址在进行浏览时,都是需要点击"下一页"之类的按钮,而它支持键盘快捷键,而且体验效果还不错;它的界面、文字啊也比较活泼,比如按热度排序,它优雅的称其为"抛头露面的优先"。

(3)保持更新。作为写代码的,我们最害怕开源的东西不再更新了,EasyIcon图标更新频率还算将就。
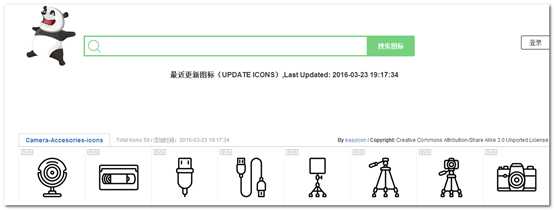
(4)打包下载,有时,我们下载的图标不只一个,可以使用它的打包下载功能。(但此功能有一定的限制,如每一次打包下载有数量限制,且下载尺寸、格式等不便设置,这也是为什么要重新写一个批量下载工具的原因。)

所以,总结下来,我们需要一个程序,实现批量下载不同格式、尺寸的图标到本地,以便于搜索和利用。
1.浏览器下载图标
设计方案并不是直接就想出来,还是要根据实际来一点一点地分析、确定。我们用浏览器来下载一个图标试一试。
目标:http://www.easyicon.net/iconsearch/iconset:fatcowhosting-icons/
在这个网址里,包含2000个(40页)不同尺寸和格式和图标。fatcowhosting-icons就是这些图标集合的分类名称。

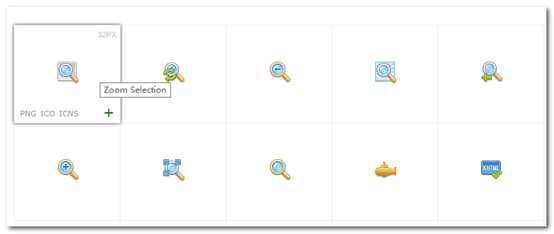
单击第一个图标,进入其他详细页面:http://www.easyicon.net/530832-Zoom_Selection_icon.html,这里我们可以看到很多参数信息。
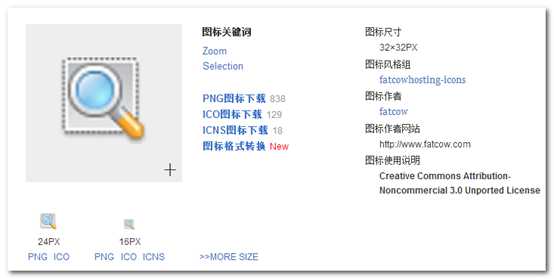
点击PNG图标下载,我们下载这个图标。(这一次的下载,就是以后代码中最内层循环的一段代码。)我们看到了真实的下载地址:http://download.easyicon.net/png/530832/32/
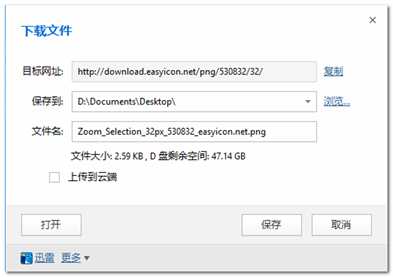
只要我们有这个下载网址,无论在哪个浏览器或自定义程序,都可以进行下载。
2.分析下载地址
来看每一页的地址:
http://www.easyicon.net/iconsearch/iconset:fatcowhosting-icons/1/
fatcowhosting-icons表示图标集合名称,1表示页数
那我们来分析一下这个地址:http://download.easyicon.net/png/530832/32/
这个下载地址可分解为:固定部分+格式+图标编号+尺寸
再来看一下,下载需要的参数:下载地址+文件保存路径+文件名称
综合分析可以看出,图标的格式、尺寸、文件保存路径可以由用户指定,现在关键是缺少图标编号和文件名称。
假如我们已经知道了图标编号,并将下载网址输入到浏览器的地址栏中提交,浏览器可自动识别出下载的文件名称,这是为何?说明用户向服务器提交这个地址后,服务器返回了一些消息,其中就包括文件名称,所以,通过某种编程方式(后面会提到,暂不用着急去查询),可以获取到文件名称。
好了,现在唯一缺少的主是图标编号了。通过观察网站的其他图标,可以发现这些编号都是连接的,比如530832是Zoom_Selection_icon的编号,而530831是Zoom_Refresh的编号;再看图标fatcowhosting-icons集合的每一页都是50个(最后一页除外),我们是不可以根据每一个图标和最后一个图标的编号来获取这个图标集合的所有编号?答案是肯定的。
那我们怎么来获取第一个和最后一个的编号?如果我们又通过某种技术手段获取到这两上编号了……等等,如果能获取这两个编号了,为什么不获取直接获取所有编号呢?是的,通过网页抓取的某种方法应该可以获取所有编号。
3.画一个简单的流程图
下面是使用亿图图示专家V7.9绘制流程图:
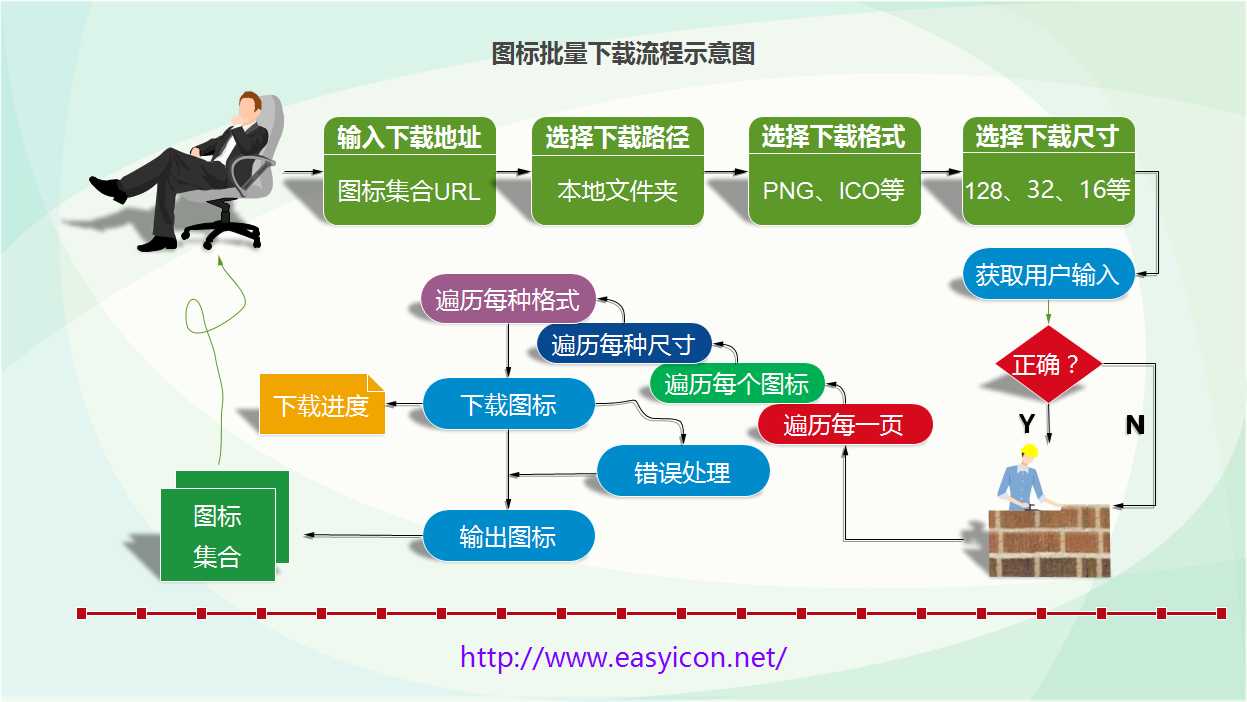
4.写一个简单的接口
分析了这么久,写一个简单的接口来理一下我们的思路。(C#)
private string[] FileType; //文件格式
private int[] FileSize; //文件大小
private string FilePath; //文件保存路径
private int TotalPages; //图标总页数
//获取图标总页数
private int GetTotalPages(string iconsURL) { }
//获取当前页的编号
private string[] GetIDs(string pageURL){}
private bool DownICO(string[] fileType, int[] fileSize, int totalPages)
{
//一层:遍历每一页
for (int i = 0; i < totalPages; i++)
{
//获取当前页所有编号
string[] strIDs = GetIDs("PagesURL");
//两层:遍历每一个编号
for (int j = 0; j < strIDs.Length; j++)
{
//三层:遍历每一种尺寸
for (int k = 0; k < fileSize.Length; k++)
{
//四层:遍历每一种格式
for (int m = 0; m < filePath.Length; m++)
{
//生成下载链接
string downURL = "http://download.easyicon.net/格式/编号/尺寸/";
Down(this.FilePath, downURL);
//其他操作……
}
}//4
}//3
}//2
}//1
//下载每一个图标
private bool Down(string filePath,string downURL){}
5.关键问题
下面是代码中使用的关键问题的解决方案:
(1)如果一切参数都能找到,用哪个类或方法来下载?System.Net.WebClient的DownloadFile方法。
(2)怎样获取图标总页数?根据观察网页,每一页都有"个图标,翻X页可看完",X即为总页数,通过抓取网页字符串即可;
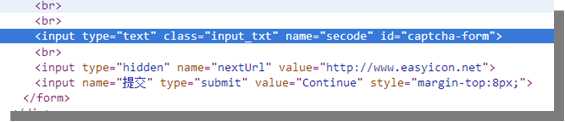
(3)怎样获取每一页所有图标的编号?当然还是通过网页抓取。如下图,通过审查元素,可以看到每一个图标的编号和名称。
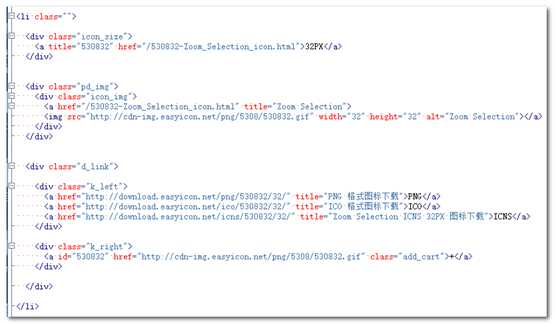
(4)怎样获取下载图标的名称?有两种方式,一是网页内容抓取;二是通过根据服务返回的信息来提取。
编程比较简单,下面是网页操作的两个比较核心的函数(第一次抓取网页,不知道这样好不好)
第一个函数,是通过网页地址来获取网页代码的。
/// <summary>
/// 根据URL获取网页代码
/// </summary>
/// <param name="strURL">URL地址</param>
/// <returns>网页代码字符串</returns>
public static string GetHtmlString(string strURL)
{
Uri uri = new Uri(strURL);
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(uri);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
string strHtml = "";
if (stream != null)
{
StreamReader sr = new StreamReader(stream);
strHtml = sr.ReadToEnd();
sr.Close();
stream.Close();
response.Close();
}
return strHtml;
}
第二个函数主要是根据向服务器提交图标的下载链接,获取返回的headers信息,这些信息里就包含了图标的名称。
/// <summary>
/// 根据URL获取headers信息
/// </summary>
/// <param name="URL">URL地址</param>
/// <returns>headers信息列表</returns>
public static Dictionary<string, string> GetHeaders(string URL)
{
Dictionary<string, string> headerList = new Dictionary<string, string>();
WebRequest webRequestObject =HttpWebRequest.Create(URL);
WebResponse responseObject =webRequestObject.GetResponse();
foreach (string headerKey in responseObject.Headers)
{
headerList.Add(headerKey, responseObject.Headers[headerKey]);
}
responseObject.Close();
return headerList;
}
问题一:验证码问题
编程其实并不是那么一蹴而就,或多或少会遇到一些之前没有想到的问题
其中遇到最大的问题是验证问题。如果大量下载图标(第一次达166个图标)时,向服务器提交下载地址时,它会弹出验证窗口,下面是用webBrowser控件得到的结果。
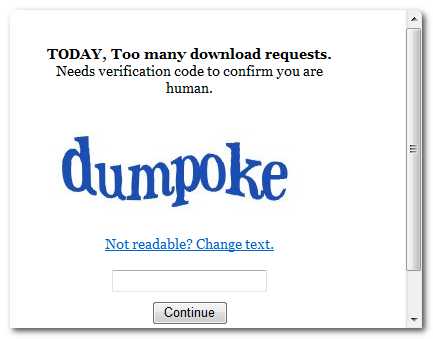
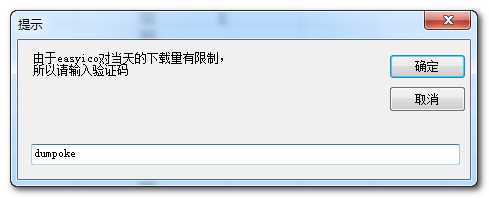
这是另外一个网页http://www.easyicon.net/api/captcha/captcha.php返回的结果
解决:一开始的解决思路是去抓包,获取提交链接和内容,就像其他程序让用户打码一样;后来我就得反正是要打码,还不如让用户直接看到这个页面(当然,这样的界面显示很粗糙,实际上应该去获取这个图标,并将这个图标显示在用户面前),于是用了webBrowser控件;接下来,需要一个输入,然后提交:输入采用了VB中的InputBox,这样更方便,不需要去暂停线程,提交就是用HtmlElement的GetAttribute来获取提交按钮,用InvokeMember方法来执行。
问题二:程序假死问题
下载量过多,程序界面肯定会假死,用户体验十分不好。需要新建线程,但要注意新线程与主线程之间的控件信息交互问题。
解决:下面是用委托来实现向ListBoxAdv添加下载返回的消息的函数。
delegate void SetValueCallback(ListBoxAdv lstA,string log);
private void SetPropertyValue(ListBoxAdv lstA,string log)
{
if (lstA.InvokeRequired)
{
SetValueCallback d = new SetValueCallback(SetPropertyValue);
lstA.Invoke(d, new object[] { lstA,log });
}
else
{
lstA.Items.Add(log);
lstA.SetSelected(lstA.Items.Count-1,true);
lstA.SelectedIndex=lstA.Items.Count - 1;
}
}
调用:
SetPropertyValue(lstAdv, "消息……”);
问题三:下载失败问题
并不是所有图标都能正常下载,即使多次反复下载,它容易出现,下载结果只有25字节大小的图标(重复下载也无效),可能是因为网速的原因。
解决:遍历所有25字节的图标,删除后重新下载(当然也需要耗时)。
主界面
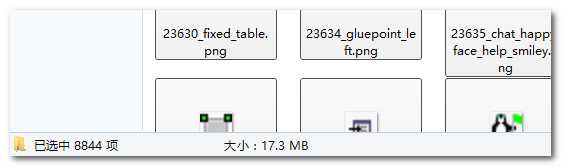
下载的图标
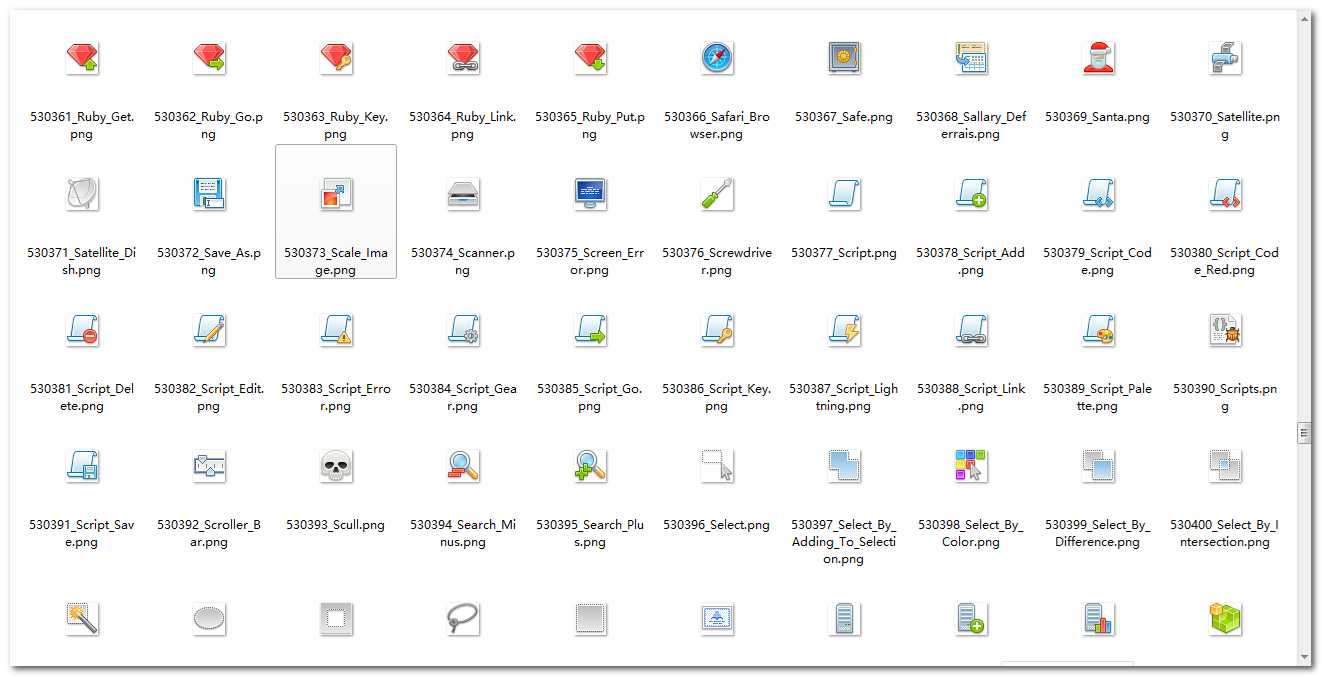
我测试下载了png 32的图标,约8000多个,本地和云盘都有,文件以编号+名称命名,通过编号,我可以再从官网下载到其他需要的图标,通过名称可以搜索到需要的图标。
源码下载:http://files.cnblogs.com/files/liweis/EasyDown.rar
展望
1.服务器是怎样检测本机连续下载图标的数量的?是根据IP还是其他,如果搞清它的机制,是否可以通过某种代码操作跳过它的检测,而不再使用验证码呢?
2.怎样查询到图标集合的名称,可以通过某种SQL代码查询到吗?如果可以,整个easyicons就不是问题了!
标签:
原文地址:http://www.cnblogs.com/liweis/p/5344528.html