标签:
一.实验原理
1.进程的定义
进程是操作系统的概念,每当我们执行一个程序时,对于操作系统来讲就创建了一个进程,在这个过程中,伴随着资源的分配和释放。可以认为进程是一个程序的一次执行过程。
2.进程与程序的区别
程序时静态的,它是一些保存 在磁盘上得指令的有序集合,没有任何执行的概念。
二.实验步骤
1.在test.c中添加如下代码:
1 pid_t fpid; 2 printf("going to create a process.....\n"); 3 asm volatile( 4 "mov $0x2,%%eax\n\t" 5 "int $0x80\n\t" 6 "mov %%eax,%0\n\t" 7 :"=m"(fpid) 8 ); 9 printf("have created a process\n"); 10 if(fpid < 0) 11 { 12 printf("error in fork!\n"); 13 } 14 else if(fpid == 0) 15 { 16 printf("i am child,process id :%d.\n",getpid()); 17 } 18 else 19 { 20 printf("i am parent,process id :%d.\n",getpid()); 21 } 22 return 0;
2.重新编译运行,结果如下图所示:
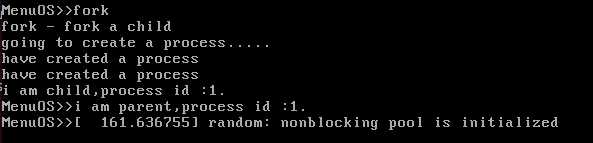
3.运行fork,结果如下图所示:
4.使用gdb调试运行系统,如下图所示:

5.在如下位置下断点,如下图所示:






6.调试运行程序,观察程序运行过程:




三.实验总结
实验作业题目的理解如下所示:
阅读理解task_struct数据结构http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235;
分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构;
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
1 *childregs = *current_pt_regs(); //复制内核堆栈 2 childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因! 3 4 p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 5 p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
do_fork完成了创建中的大部分工作,该函数调用copy_process()函数,然后让进程开始运行。copy_process()函数工作如下:
使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,验证您对Linux系统创建一个新进程的理解
copy_process()主要完成进程数据结构,各种资源的初始化特别关注新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
ret_from_fork;决定了新进程的第一条指令地址p->thread.ip = (unsigned long) ret_from_fork;决定了新进程的第一条指令地址*childregs = *current_pt_regs();该句将父进程的regs参数赋值到子进程的内核堆栈
本次实验主要是对fork系统调用的调试,难度并不是很大,但是需要啊记住的东西很多,希望自己能够全部理解,加油!(*^__^*)
标签:
原文地址:http://www.cnblogs.com/crowpurple/p/5350490.html