标签:style blog http color 文件 数据 io 2014
前几天有一朋友要我帮做一个采集新闻信息的程序,抽了点时间写了个PHP版本的,随笔记录下。
说到采集,无非就是远程获取信息->提取所需内容->分类存储->读取->展示
也算是简单"小偷程序"的加强版吧
下面是对应核心代码(别拿去做坏事哦^_^)
所要采集的内容是某游戏网站上的公告,如下图:
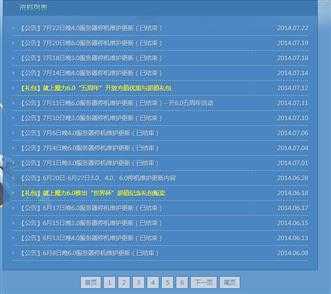
可先利用file_get_contents和简单正则获取基本页面信息

整理下基本信息,采集入库:
<?php include_once("conn.php"); if($_GET[‘id‘]<=8&&$_GET[‘id‘]){ $id=$_GET[‘id‘]; $conn=file_get_contents("http://www.93moli.com/news_list_4_$id.html");//获取页面内容 $pattern="/<li><a title=\"(.*)\" target=\"_blank\" href=\"(.*)\">/iUs";//正则 preg_match_all($pattern, $conn, $arr);//匹配内容到arr数组 //print_r($arr);die; foreach ($arr[1] as $key => $value) {//二维数组[2]对应id和[1]刚好一样,利用起key $url="http://www.93moli.com/".$arr[2][$key]; $sql="insert into list(title,url) value (‘$value‘, ‘$url‘)"; mysql_query($sql); //echo "<a href=‘content.php?url=http://www.93moli.com/$url‘>$value</a>"."<br/>"; } $id++; echo "正在采集URL数据列表$id...请稍后..."; echo "<script>window.location=‘list.php?id=$id‘</script>"; }else{ echo "采集数据结束。"; } ?>
conn.php是数据库连接文件
list.php是本页面
由于要采集的数据是分页显示的,且页面地址是规律递增,所以我用了js跳转代码,利用id传值控制采集的页数,也避免了for循环数目过大。
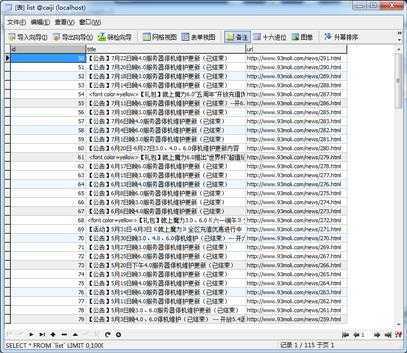
轻轻松松数据入库,下篇博客写关于具体url采集信息的过程。
基于PHP采集数据入库程序(一),布布扣,bubuko.com
标签:style blog http color 文件 数据 io 2014
原文地址:http://www.cnblogs.com/lichenwei/p/3872307.html