标签:
访问修饰符:
关于多态,人的世界中,我们常常在不同的环境中表现为不同的角色,并且遵守不同的规则。例如在学校我们是学生,回到家里是儿女,而在车上又是乘客,同一个人在不同的情况下,代表了不同的身份,在家里你可以撒娇但是在学校你不可以,在学校你可以打球但在车上你不可以。所以这种身份的不同,带来的是规则的差异。在面向对象中,我们该如何表达这种复杂的人类社会学呢?
interface IPerson { string Name { get; set; } Int32 Age { get; set; } void DoWork(); } class PersonAtHome : IPerson { } class PersonAtSchool : IPerson { } class PersonOnBus : IPerson { }
显然,我们让不同角色的Person继承同一个接口:IPerson。然后将不同的实现交给不同角色的人自行负责,不同的是PersonAtHome在实现时可能是CanBeSpoil(),而PersonOnBus可能是BuyTicket()。不同的角色实现不同的规则,也就是接口协定。在使用上的规则是这个样子:
IPerson aPerson = new PersonAtHome();
aPerson.DoWork();
另一个角色又是这个样子:
IPerson bPerson = new PersonOnBus();
bPerson.DoWork();
由此带来的好处是显而易见的,我们以IPerson代表了不同角色的人,在不同的情况下实现了不同的操作,而把决定权交给系统自行处理。这就是多态的魅力,其乐无穷中,带来的是面向对象中最为重要的特性体验。记住,很重要的一点是,DoWork在不同的实现类中体现为同一命名,不同的只是实现的内部逻辑。
这和我们的规则多么一致呀!
当然,有必要补充的是对象中的多态主要包括以下两种情况:
— 接口实现多态,就像上例所示。
— 抽象类实现多态,就是以抽象类来实现。
对象创建始末:
了解.NET的内存管理机制,首先应该从内存分配开始,也就是对象的创建环节。对象的创建,是个复杂的过程,主要包括内存分配和初始化两个环节
1. 内存分配
关于内存的分配,首先应该了解分配在哪里的问题。CLR管理内存的区域,主要有三块,分别为:
关于实例创建有多个IL指令解析,主要包括:
1.1 堆栈的内存分配机制
对于值类型来说,一般创建在线程的堆栈上。但并非所有的值类型都创建在线程的堆栈上,例如作为类的字段时,值类型作为实例成员的一部分也被创建在托管堆上;装箱发生时,值类型字段也会拷贝在托管堆上。
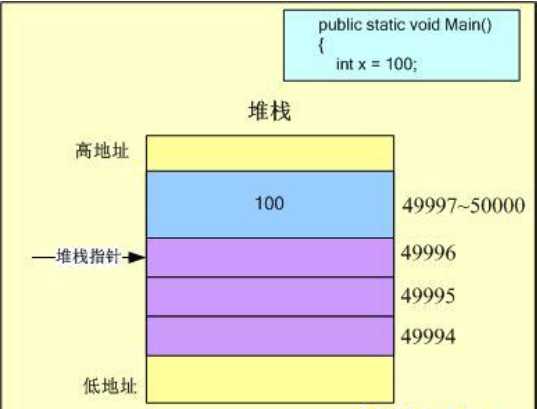
对于分配在堆栈上的局部变量来说,操作系统维护着一个堆栈指针来指向下一个自由空间的地址,并且堆栈的内存地址是由高位到低位向下填充。以下例而言:
public static void Main() { int x = 100; char c = ‘A‘; }
假设线程栈的初始化地址为50000,因此堆栈指针首先指向50000地址空间。代码由入口函数Main开始执行,首先进入作用域的是整型局部变量x,它将在栈上分配4Byte的内存空间,因此堆栈指针向下移动4个字节,则值100将保存在49997~50000单位,而堆栈指针表示的下一个自由空间地址为
49996,如图所示:
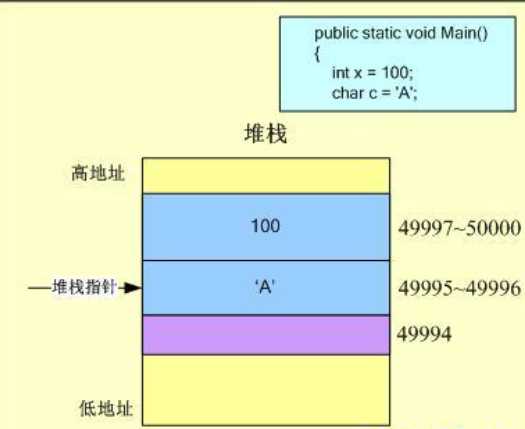
接着进入下一行代码,将为字符型变量c分配2Byte的内存空间,堆栈指针向下移动2个字节至49994单位,值’A’会保存在49995~49996单位,地址的分配如图:
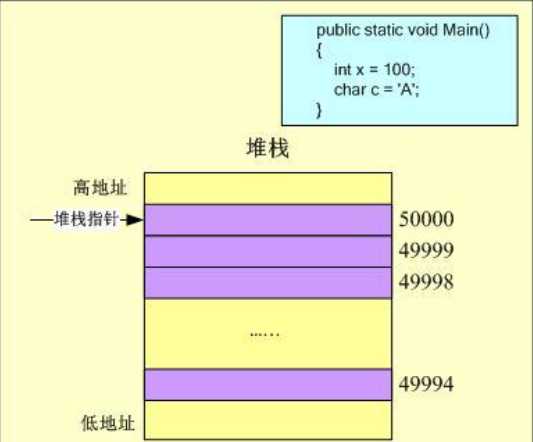
最后,执行到Main方法的右括号,方法体执行结束,变量x和c的作用域也随之结束,需要删除变量x和c在堆栈内存中的值,其释放过程和分配过程刚好相反:首先删除c的内存,堆栈指针向上递增2个字节,然后删除x的内存,堆栈指针继续向上递增4个字节,程序执行结束,此时的内存状况为:
其他较复杂的分配过程,可能在作用域和分配大小上有所不同,但是基本过程大同小异。栈上的内存分配,效率较高,但是内存容量不大,同时变量的生存周期随着方法的结束而消亡。
1.2 托管堆的内存分配机制
托管堆又根据存储信息的不同划分为多个区域,其中最重要的是垃圾回收堆(GC Heap)和加载堆(Loader Heap),GC Heap用于存储对象实例,受GC管理;Loader Heap又分为High-Frequency Heap、Low-Frequency Heap和Stub Heap,不同的堆上又存储不同的信息。Loader Heap最重要的信息就是元数据相关的信息,也就是Type对象,每个Type在Loader Heap上体现为一个Method Table(方法表),而Method Table中则记录了存储的元数据信息,例如基类型、静态字段、实现的接口、所有的方法等等。Loader Heap不受GC控制,其生命周期为从创建到AppDomain卸载。
在进入实际的内存分配分析之前,有必要对几个基本概念做以交代,以便更好的在接下来的分析中展开讨论。
实例说明:
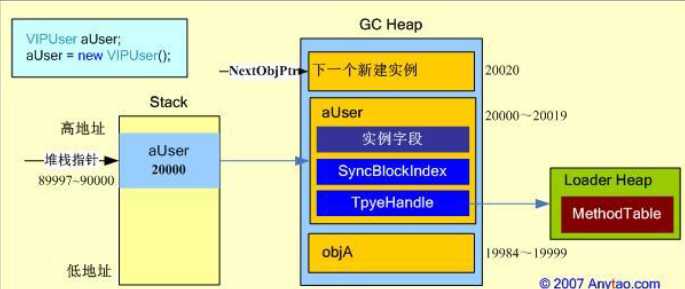
public class UserInfo { private Int32 age = -1; private char level = ‘A‘; } public class User { private Int32 id;
private UserInfo user; } public class VIPUser : User { public bool isVip; public bool IsVipUser() { return isVip; } public static void Main() { VIPUser aUser; aUser = new VIPUser(); aUser.isVip = true; Console.WriteLine(aUser.IsVipUser()); } }
对象创建并初始化之后,内存的布局,可以表示为:
1.3 必要的补充
这一思考其实是一个问题的两个方面:对于值类型嵌套引用类型的情况,引用类型变量作为值类型的成员变量,在堆栈上保存该成员的引用,而实际的引用类型仍然保存在GC堆上;对于引用类型嵌套值类型的情况,则该值类型字段将作为引用类型实例的一部分保存在GC堆上。
静态字段也保存在方法表中,位于方法表的槽数组后,其生命周期为从创建到AppDomain卸载。因此一个类型无论创建多少个对象,其静态字段在内存中也只有一份。静态字段只能由静态构造函数进行初始化,静态构造函数确保在类型任何对象创建前,或者在任何静态字段或方法被引用前执行。
面向对象的三大特征之一: 继承
首先,认识一张比较简单的动物分类图(图1-1),以便引入我们对继承概念的介绍。
从图1-1中,我们可以获得的信息包括:
将这种现实世界的对象抽象化,就形成了面向对象世界的继承机制。因此,关于继承,我们可以定义为:
继承,就是面向对象中类与类之间的一种关系。继承的类称为子类、派生类,而被继承类称为父类、基类或超类。通过继承,使得子类具有父类的属性和方法,同时子类也可以通过加入新的属性和方法或者修改父类的属性和方法建立新的类层次。
继承机制体现了面向对象技术中的复用性、扩展性和安全性。
在.NET中,继承按照其实现方式的不同,一般分类如下。
值得关注的是继承的可见性问题,.NET通过访问权限来实现不同的控制规则,这些访问修饰符主要包括:public、protected、internal和private。
进一步认识继承的本质:
通过上面的讲述与分析,我们基本上对.NET在编译期的实现原理有了大致的了解,但是还有以下的问题,可能会引起疑惑,那就是:
Bird bird2 = new Chicken();
这种情况下,bird2.ShowType应该返回什么值呢?而bird2.type又该是什么值呢?
有两个原则,是.NET专门用于解决这一问题的。
— 关注对象原则:调用子类还是父类的方法,取决于创建的对象是子类对象还是父类对象,而不是它的引用类型。
例如Bird bird2 = new Chicken()时,我们关注的是其创建对象为Chicken类型,因此子类将继承父类的字段和方法,或者覆写父类的虚方法,而不用关注bird2的引用类型是否为Bird。引用类型的区别决定了不同的对象在方法表中不同的访问权限。
注意: 根据关注对象原则,下面的两种情况又该如何区别呢?
Bird bird2 = new Chicken();
Chicken chicken = new Chicken();
根据上文的分析,bird2对象和chicken对象在内存布局上是一样的,差别就在于其引用指针的类型不同:bird2为Bird类型指针,而chicken为Chicken类型指针。以方法调用为例,不同的类型指针在虚拟方法表中有不同的附加信息作为标志来区别其访问的地址区域,称为offset。不同类型的指针只能在其特定地址区域内执行,子类覆盖父类时会保证其访问地址区域的一致性,从而解决了不同的类型访问具有不同的访问权限问题。
— 执行就近原则:对于同名字段或者方法,编译器是按照其顺序查找来引用的,也就是首先访问离它创建最近的字段或者方法,例如上例中的bird2,是Bird类型,因此会首先访问Bird_type(注意编译器是不会重新命名的,在此是为区分起见),如果type类型设为public,则在此将返回“Bird”值。这也就是为什么在对象创建时必须将字段按顺序排列,而父类要先于子类编译的原因了。
实现继承与接口继承
继承之毒瘤主要体现在:
面向对象的基本原则: 多聚合,少继承。 低耦合,高内聚。
标签:
原文地址:http://www.cnblogs.com/happyjoy/p/5355978.html