标签:
对于6.12提到的加深网络深度带来的问题,(gradient diffuse 局部最优等)可以使用stack autoencoder的方法来避免
stack autoencoder是哟中逐层贪婪(Greedy layer-wise training)的训练方法,逐层贪婪的主要思路是每次只训练网络中的一层,即首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,把已经训练好的前 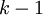 层固定,然后增加第
层固定,然后增加第  层(也就是将已经训练好的前 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
层(也就是将已经训练好的前 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
逐层贪婪的训练方法取得成功要归功于以下几方面:
1)数据获取:虽然获取有标签数据的代价是昂贵的,但获取大量的无标签数据是容易的。自学习方法(self-taught learning)的潜力在于它能通过使用大量的无标签数据来学习到更好的模型。该方法使用无标签数据来学习得到所有层(不包括用于预测标签的最终分类层)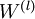 的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
2)更优的局部极值:当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上。然后我们可以从这些位置出发进一步微调权重。从经验上来说,以这些位置为起点开始梯度下降更有可能收敛到比较好的局部极值点,这是因为无标签数据已经提供了大量输入数据中包含的模式的先验信息。
stack autoencoder 就是一种逐层贪婪的训练算法。
6.13 Neurons Networks Stack Auto Encoder
标签:
原文地址:http://www.cnblogs.com/ooon/p/5367100.html