标签:
注意:在使用模糊查询的时候,当% 在第一个字母的位置的时候,这个时候索引是无法被使用的。但是% 在其他的位置的时候,索引是可以被使用的。
?
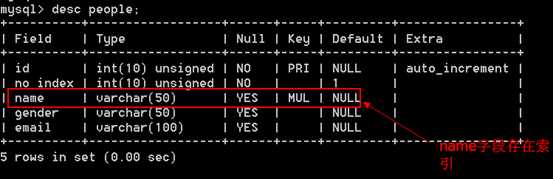
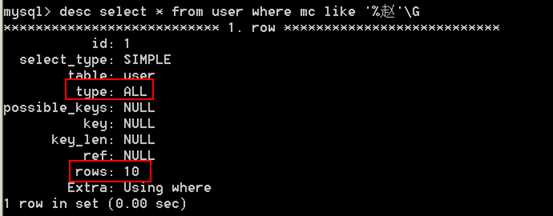
# select * from tableName where name like "%zhangsan"; ?可以使用到索引啊? 不可以。
分析:因为是不确定查询,在表中任何一行记录都有可能满足查询条件。
?
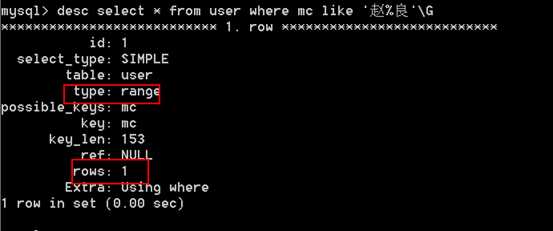
#select * from tableName where name like "zh%"; 可以使用吗? 可以
#select * from tableName where name like "zh%三"; 可以使用吗? 可以
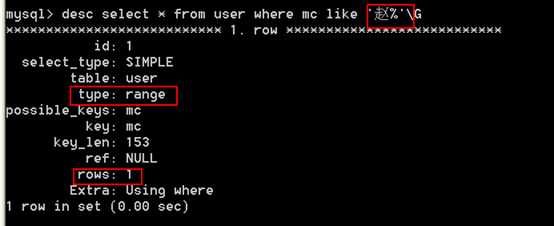
# select * from tableName where name like "z%san"; ? 可以使用吗?可以,首先可以快速定位z字母开头的部分。读z字母这段范围之内只能逐行比较。
?
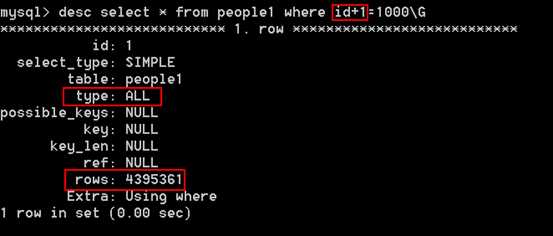
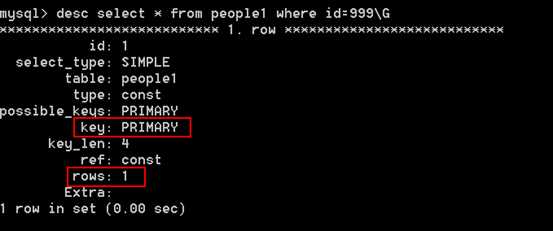
# select * from tableName where id+1 = 1000;
# select * from tableName where id = 999; 等价。
?
?
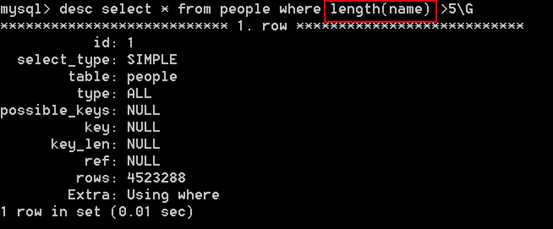
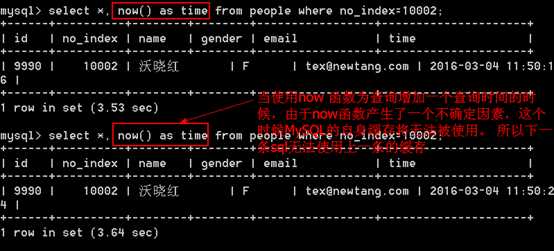
有的时候,会在查询字段上面使用函数。使用函数的时候也是无法使用所有的,一般的解决方案是将查询后的结果交给php程序(字符串 和 数组)来实现处理。不要把函数的处理放在MySQL里面完成。
?
答:
?
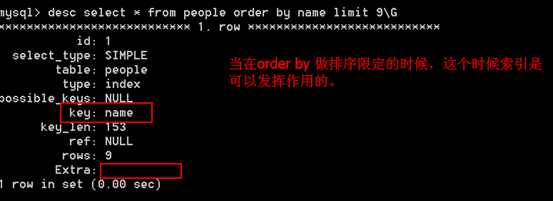
执行order by 不加限定,全表扫描,filesort含义 注意:问题?
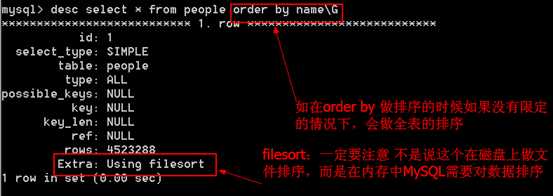
?
答:
?
解释:MySQL的客户端在发送sql语句到MySQL服务器端之后,会先去检查一下权限,之后去查询该条sql语句的缓存信息是否存在,如果存在,则直接返回;如果不存在,MySQL服务器需要去分析该sql语句,做词法语法分析,然后编译,生产执行树,去磁盘上获取数据,获取数据后,缓存到自身的一个缓存容器里面,然后在返回数据。
?
使用:
# show variables like "%cache%";
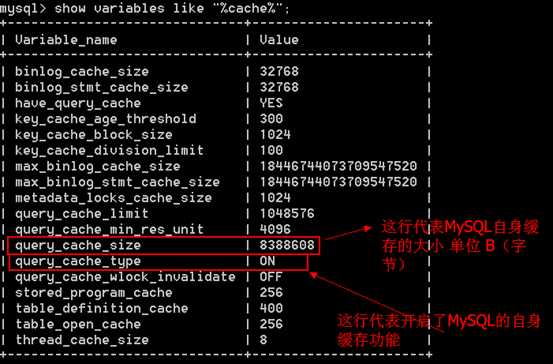
更改MySQL缓存的大小(32M),注意 单位是 B(字节)
# set global query_cache_size = 1024*1024*32;
注意:第一个是要加关键字 global 第二个是大小的单位为 B(字节) 第三具体给多少合适,取决于自身操作系统的内存大小。

测试对比:
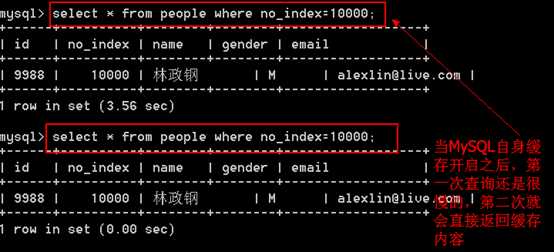
?
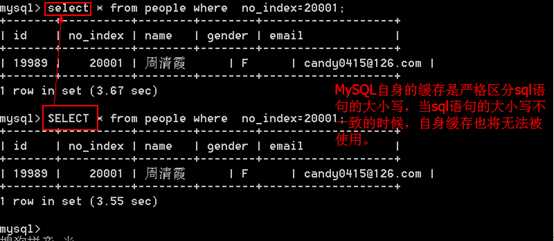
注意:MySQL自身的缓存需要注意两点:
分析:
?
?
?
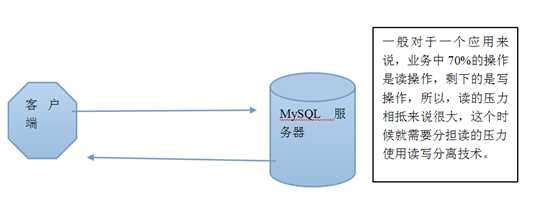
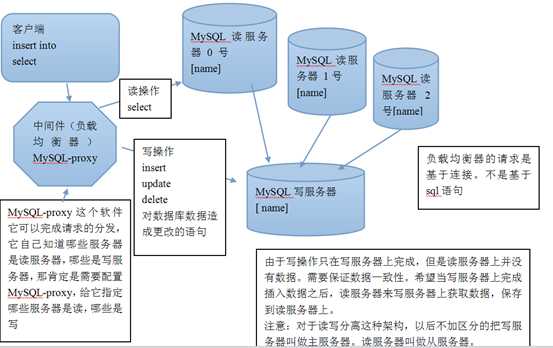
由于一个网站业务中 70%的业务基本都是读操作,剩下的都是写操作。所以这个时候对读的压力过大,需要使用一定的方式来减少压力,这个时候可以使用读写分离这种架构来实现压力的分担。
怎么查询是读为主?
# show status like "%Com_%";


通过上面的分析一段时间,就可以大致计算出网站的读写情况
?
# show status ; 可以查看MySQL的一个状态信息。

?
?
?
读写分离概图:
mysql-proxy这个工具可以实现对sql语句的分析,判断sql语句是读操作(select关键字) 还是 写操作(insert、update、delete)。最后去连接不同的服务器实现业务的完成。
当完成读的时候,MySQL-proxy会从对台读服务器按照一定策略去选择一台(轮询、加权、ip_hash)完成读操作
当完成写的时候,直接去连接写的服务器
?
问题:
由于数据只在主服务器上实现写操作,但是从服务器上是没有完成写操作的,这个时候数据就会不一致。
需要解决一致性的问题?
答:可以使用MySQL的一个bin日志来完成数据的一致性问题。
?
使用步骤:
主服务器配置:
?
从服务器配置:
?
总结:主从复制是完成读写分离的一个基础。(稍微有点延时)
?
对于MyISAM的存储引擎来说,如果查询的字段信息正好在索引文件里面出现,这个时候不需要做回行的操作,直接可以从索引文件里面返回的现象就叫做索引覆盖。(索引正好覆盖了查询的字段)
?
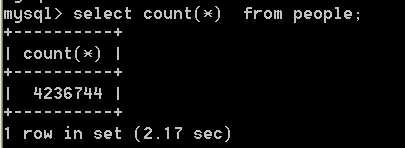
应用:在大数据(百万数据)下的一个翻页效果
技术点:翻页是如何做的?
答:select * from tableName limit offset,page;
好比现在是N页,每页显示page条
offset = (N-1) * page
?
实际使用:
分页操作
当很大页码的时候
?
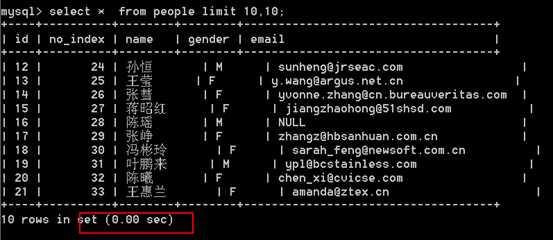
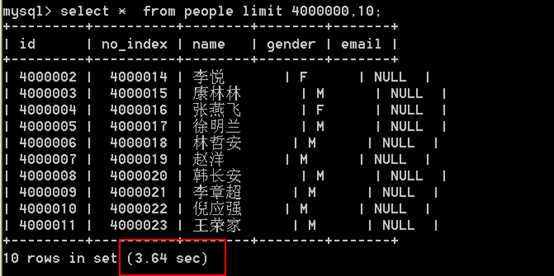
通过上面的对比发现,MySQL在使用limit分页的时候,在页码足够大的情况下,效率是很低的,为什么?
答:主要原因是,MySQL在使用limit做查询的时候,如下sql:
select * from tableName limit offset,page;
执行过程:
先取出 offset+page 条记录, 然后在丢弃 offset 条记录 ,返回 page 条记录。
所以有必要对这种情况做优化操作:
?
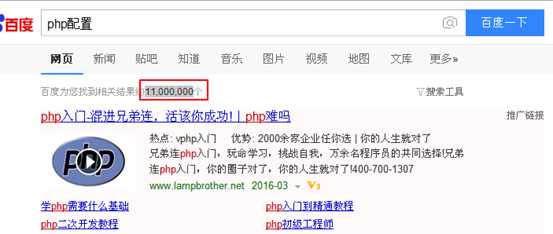
百度限制用户行为:

?
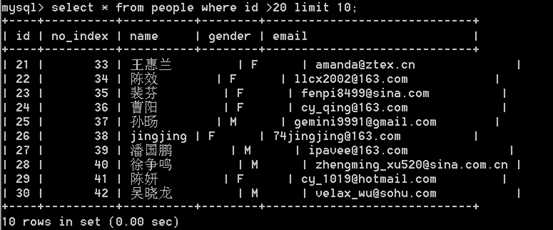
当分页页码变大的情况下:
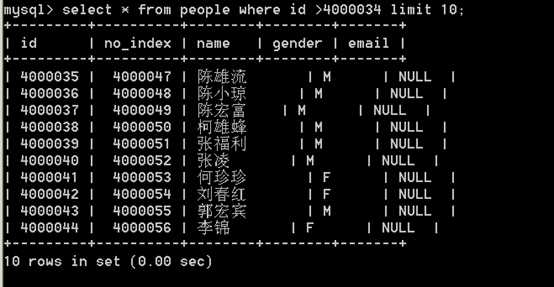
通过使用 where id > Number limit 10; 这样由于可以使用上id的主键索引,所以可以快速的定位,达到一个大数据的分页的效果。
?
?
问题:
a. select * from tableName where id > Number limit page;
b. select * from tableName limit Number, page;
?
当上面的这两条sql语句执行后,结果在什么时候完全一致,什么时候不一致?
答:当数据没有被物理行删除的时候。这个时候数据是一致的,但是有物理行删除的时候,数据是不一致的。
如何解决上面的问题?
答:既然是物理行删除造成的,那就不做物理行的删除,只做逻辑删除(设置一个is_delete 字段 0 代表没有删除 1 代表已经删除)。
使用逻辑删除之后,数据会一致,只要在数据显示的,在显示层面(HTML)让is_delete=1 不显示出来即可。if( is_delete == 1) echo ‘该条信息已被删除!‘ 例如:常见的百度贴吧,网易新闻端。
?
3. 实现物理行删除,不限制用户行为
答:这个时候可以使用 索引覆盖 + 延时关联技巧 来实现。
分析:
程序代码实现:
在php层面实现????????
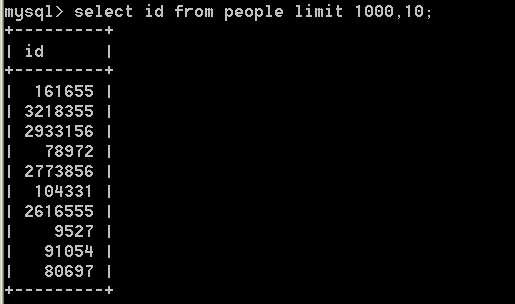
?
foreach($data as $k=>$v){
$sql = select * from tableName where id = $v;
$res = mysql_query($sql);
$row = mysql_fetch_assoc($res);
$result[]= $row;
}
$result //分页数据
?
在MySQL层面联表处理:
使用联表来完成大数据的分页操作
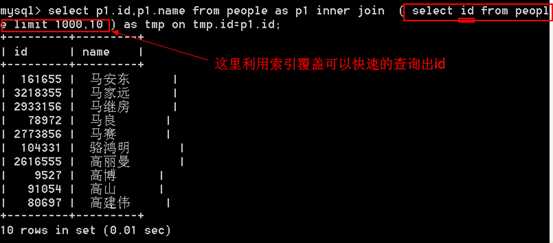
?
解释

标签:
原文地址:http://www.cnblogs.com/nyxd/p/5369974.html