标签:
由于页面静态化技术可以实现对动态数据的缓存,但是有的时候还是需要去请求数据库。所以对数据库的优化也是不可缺少的。
设计:存储引擎,字段,范式
自身:索引,自身的缓存
架构:读写分离
?
存储引擎:
MyISAM和InnoDB之间的对比。当然需要知道MySQL除了这两种存储引擎还有其他的存储引擎(memory存储引擎)。
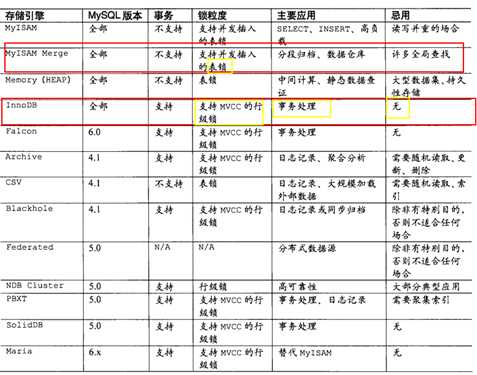
MySQL在5.5版本之后默认的存储引擎为InnoDB
在面试的过程中,只要说出MyISAM和InnoDB的区别即可
?
字段选择:
合适即好,能用tinyint就不要使用int

?
范式:三范式 主要是为了减少数据的一个冗余,基本上设计出来的表都是满足的。
?
注意:一般在开发的时候,设计之初,最先设计的就是表与表之间的关系,在后期的开发过程中是很少修改表结构的。(系统架构、经理)
?
在做MySQL自身优化的时候,既然要去优化,那就要先去发现问题?如何发现问题?
答:可以使用MySQL提供的一种慢查询日志功能来发现有问题的sql语句,然后对其进行优化。
答:MySQL提供的日志,可以用来记录超过某一个规定的时间界限的sql语句。
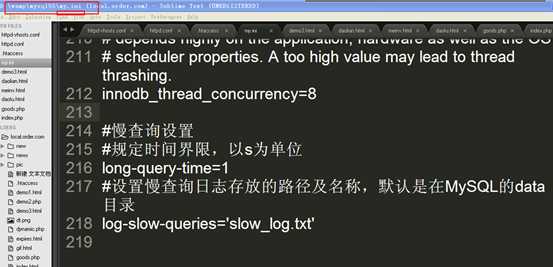
?
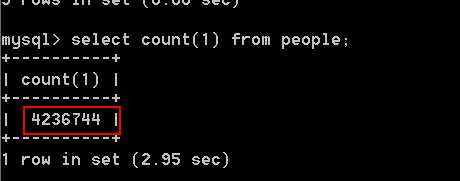
b) 在没有索引的字段上做一个查询
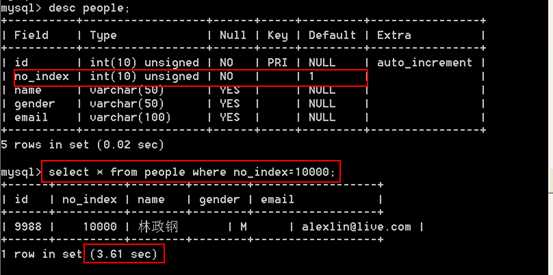
慢查询日志分析:
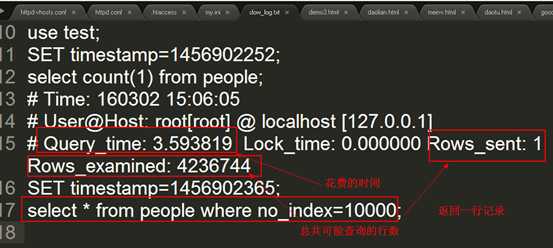
注意:在有索引的字段上做查询操作
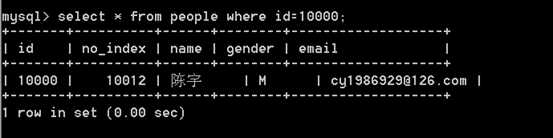
?
总结:通过对比发现使用索引之后,明显查询的速度会快很多,但是使用MySQL的慢查询日志功能记录的时间相对来说还是很粗糙(慢查询的记录时间级别只能是 1s 以上的)的。
这个时候如果需要记录时间为 1s 以下的时候,慢查询就无法发挥其作用,可以使用MySQL提供另外一个功能来完成,这个功能叫做 profile 。
?
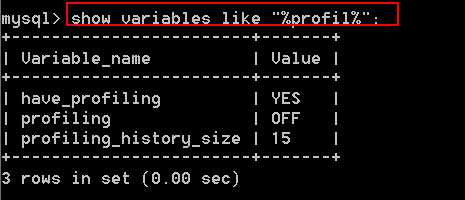
MySQL提供的一个可以记录更加精确时间的功能,能在1s 以下的sql语句都记录下来。
?
# show varibales like "%profil%"; 当有的时候无法记清的时候,可以使用这种模糊匹配查询。
# set profiling=1;
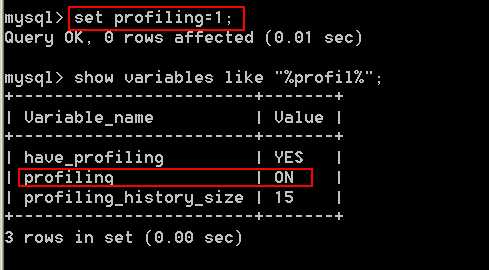
# show profiles; 可以查看profile工具记录的时间
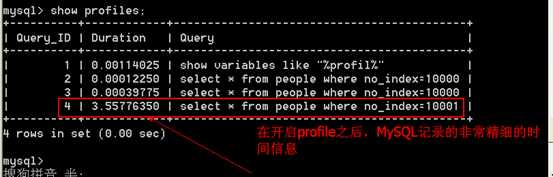
# show profile for query 4;
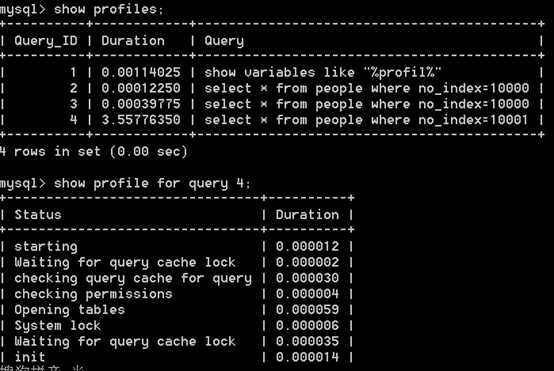
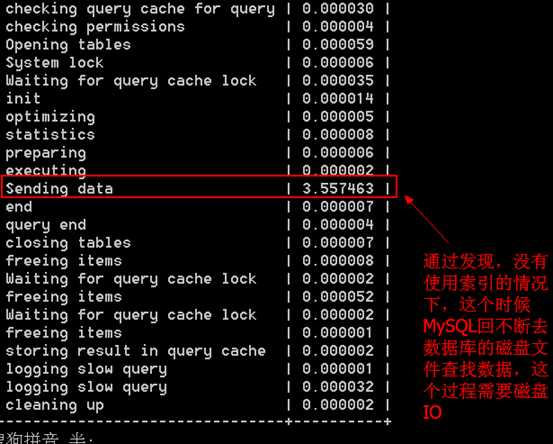
注意:为什么使用索引之后会那么快?
答:由于MySQL启动的时候一般也会将索引文件载入内存里面,即使没有,索引的载入也比去磁盘上对一条一条的查找要快。 然后索引本身是非常利于查找的一种结构,这个时候可以通过索引快速的去定位需要查询的数据,当查询到之后,然后在去磁盘上将数据取出来。
?
总结:通过使用上面的这些工具,可以粗略发现,在使用索引之后,效果有明显的提升,所以有必要对MySQL数据库进行索引方面的优化操作。
?
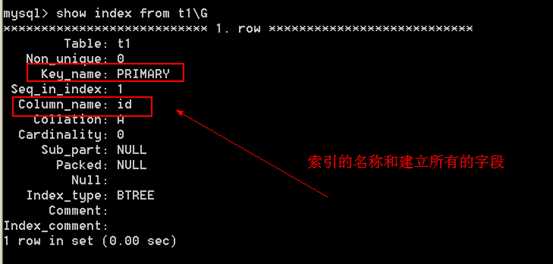
索引是一种排好序的,快速查找的数据结构。
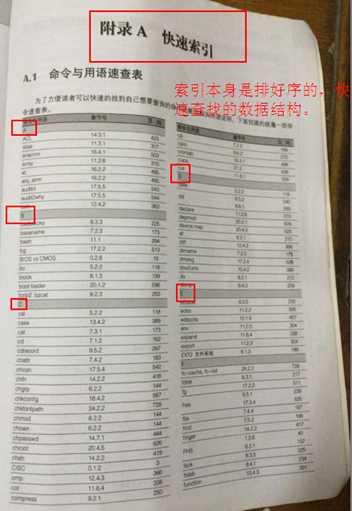
什么叫排好序?
例如上面的这个结构,可以发现,在D字母之后是不可能在出现A字母相关的信息的。
?


?

?

问题:为什么没有提供更新操作?
答:没必要专门设计一个更新,只需要先删,在建。
?
由于索引本身也是一种数据,也需要占据磁盘空间,所以索引也是有数据结构的,常见的数据结构分为两类:B-TREE结构 和 聚簇结构。
?
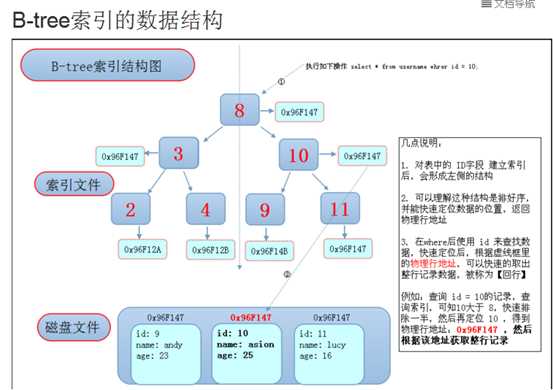
对于B-TREE结构的索引,索引节点里面保存的是物理行地址,当查询的时候需要做回行的操作。对于MyISAM存储引擎的所有索引时候的都是B-TREE结构。
结构图:
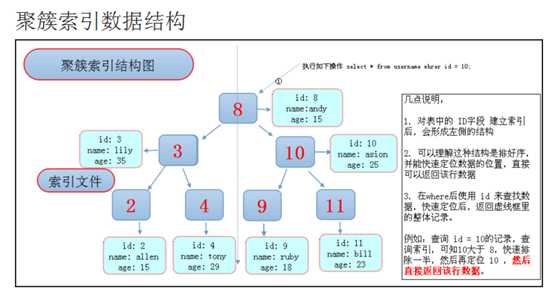
对于聚簇结构的索引,索引节点里面保存的是该行的记录,当查询的时候不需要做回行的操作。对于InnoDB存储引擎的所有索引时候的都是聚簇结构。
注意1:对于InnoDB的存储引擎来说,如果不存在主键索引,这个时候MySQL会自动的维持一个主键索引。
注意2:对于InnoDB的存储引擎来说,次级索引(唯一和普通索引)的索引节点里面保存的信息是对主键索引的一个引用。
注意3:对于InnoDB的存储引擎来说,如果是大批量的添加数据,这个时候会有很大的性能开销, 主要是在大批量插入数据的时候,主键索引也会重建,这个时候由于主键索引的索引节点里面保存的是该行的一个记录,所以要大批量的在内存中移动,开销非常大。
结构图:
?
阅读书籍
<<高性能MySQL>>
地址:
http://www.linuxidc.com/Linux/2014-10/108464.htm
?
问题1:
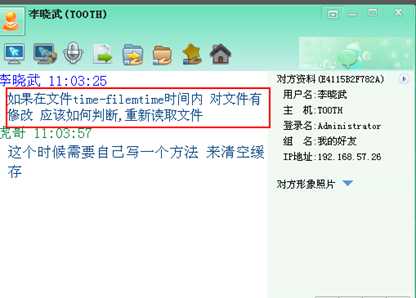
解决思路:
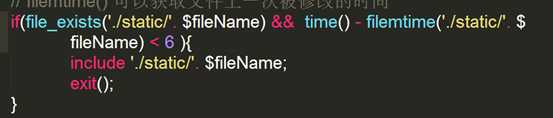
只要使得上面的两个条件中的一个或者两个都不成立即可。
那可以做一个刷新缓存的按钮,再要在缓存有效期内更改了,就清除生成的静态页。
标签:
原文地址:http://www.cnblogs.com/nyxd/p/5369846.html