标签:
目录
Twisted
Redis
RabbitMQ
Twisted
事件驱动
事件驱动分为两个部分:第一,注册事件;第二,触发事件。
自定义事件启动框架,命名为:“弑君者”:
#!/usr/bin/env python # -*- coding:utf-8 -*- # event_drive.py event_list = [] def run(): for event in event_list: obj = event() obj.execute() class BaseHandler(object): """ 用户必须继承该类,从而规范所有类的方法(类似于接口的功能) """ def execute(self): raise Exception(‘you must overwrite execute‘) 最牛逼的事件驱动框架
程序员使用“弑君者框架”:
#!/usr/bin/env python # -*- coding:utf-8 -*- from source import event_drive class MyHandler(event_drive.BaseHandler): def execute(self): print ‘event-drive execute MyHandler‘ event_drive.event_list.append(MyHandler) event_drive.run()
Protocols描述了如何以异步的方式处理网络中的事件。HTTP、DNS以及IMAP是应用层协议中的例子。Protocols实现了IProtocol接口,它包含如下的方法:
makeConnection 在transport对象和服务器之间建立一条连接
connectionMade 连接建立起来后调用
dataReceived 接收数据时调用
connectionLost 关闭连接时调用Transports代表网络中两个通信结点之间的连接。Transports负责描述连接的细节,比如连接是面向流式的还是面向数据报的,流控以及可靠性。TCP、UDP和Unix套接字可作为transports的例子。它们被设计为“满足最小功能单元,同时具有最大程度的可复用性”,而且从协议实现中分离出来,这让许多协议可以采用相同类型的传输。Transports实现了ITransports接口,它包含如下的方法:
write 以非阻塞的方式按顺序依次将数据写到物理连接上
writeSequence 将一个字符串列表写到物理连接上
loseConnection 将所有挂起的数据写入,然后关闭连接
getPeer 取得连接中对端的地址信息
getHost 取得连接中本端的地址信息将transports从协议中分离出来也使得对这两个层次的测试变得更加简单。可以通过简单地写入一个字符串来模拟传输,用这种方式来检查。
EchoServer

代码:

1 #!/usr/bin/env python 2 # encoding: utf-8 3 4 from twisted.internet import protocol 5 from twisted.internet import reactor 6 7 class Echo(protocol.Protocol): 8 def dataReceived(self, data): #只要twisted一收到数据,就会调用此方法 9 self.transport.write(data) #将接受到的数据发返回给客户端 10 11 def main(): 12 factory = protocol.ServerFactory() #定义基础工厂类(定义一些公共的东西) 13 factory.protocol = Echo #相当于socketserver中的handle 14 15 reactor.listenTCP(8888,factory) #不允许写IP地址 16 reactor.run() 17 18 if __name__ == ‘__main__‘: 19 main()
EchoClien

代码:
1 #!/usr/bin/env python 2 # encoding: utf-8 3 4 from twisted.internet import reactor, protocol 5 6 # a client protocol 7 8 class EchoClient(protocol.Protocol): 9 """Once connected, send a message, then print the result.""" 10 11 def connectionMade(self): #链接一建立成功,就会自动调用此方法 12 self.transport.write("hello boy!") #向服务端发数据 13 14 def dataReceived(self, data): #收到数据调用从方法 15 "As soon as any data is received, write it back." 16 print("Server said:", data) 17 self.transport.loseConnection() #将所有挂起的数据写入,然后关闭连接 18 19 def connectionLost(self, reason):#关闭连接时调用 20 print("connection lost") 21 22 class EchoFactory(protocol.ClientFactory): 23 protocol = EchoClient #相当于handle 24 25 def clientConnectionFailed(self, connector, reason): #如果链接失败,自动调用此方法 26 print("Connection failed - goodbye!") 27 reactor.stop() 28 29 def clientConnectionLost(self, connector, reason): #链接过程中断开,自动调用次方法 30 print("Connection lost - goodbye!") 31 reactor.stop() 32 33 34 # this connects the protocol to a server running on port 8000 35 def main(): 36 f = EchoFactory() 37 reactor.connectTCP("127.0.0.1", 8888, f) 38 reactor.run() 39 40 # this only runs if the module was *not* imported 41 if __name__ == ‘__main__‘: 42 main()
Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。[1]
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
redis的官网地址,非常好记,是redis.io。(特意查了一下,域名后缀io属于国家域名,是british Indian Ocean territory,即英属印度洋领地)
目前,Vmware在资助着redis项目的开发和维护。
Redis安装和基本使用
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar xzf redis-3.0.6.tar.gz cd redis-3.0.6 make
启动服务端
在redis-3.0.6目录下
src/redis-server
启动客户端
在redis-3.0.6目录下 src/redis-cli redis> set foo bar OK redis> get foo "bar"
Python操作Redis
sudo pip install redis or sudo easy_install redis or 源码安装 详见:https://github.com/WoLpH/redis-py
API使用
redis-py 的API的使用可以分类为:
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis r = redis.Redis(host=redis服务器IP地址, port=6379) r.set(‘foo‘, ‘Bar‘) print (r.get(‘foo‘))
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host=redis服务器IP, port=6379) r = redis.Redis(connection_pool=pool) r.set(‘foo‘, ‘Bar‘) print (r.get(‘foo‘))
3、操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
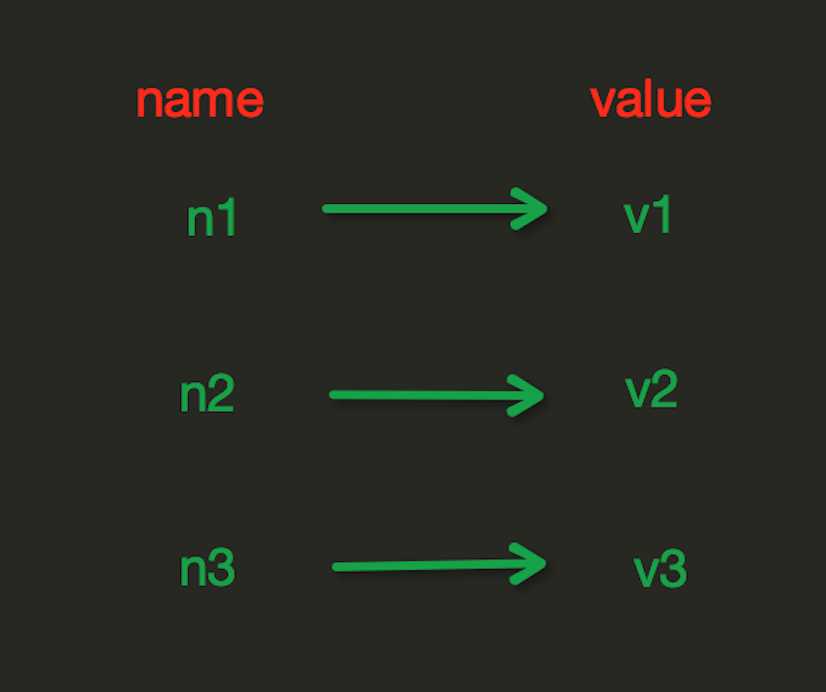
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,当前前set操作才执行
setnx(name, value):设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time):设置值
参数:
time,过期时间(数字秒 或 timedelta对象)
psetex(name, value,time_ms):设置值
参数:
time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs):批量设置值
如:
mset(k1=‘v1‘, k2=‘v2‘)
或
mget({‘k1‘:‘v1‘,‘k2‘:‘v2‘})
get(name):获取值
mget(keys, *args):批量获取
如:
mget(‘ylr‘,‘wupeiqi‘)
或
r.mget([‘ylr‘,‘wupeiqi‘])
getset(name, value):设置新值并获取原来的值
getrange(key, start, end):获取子序列(根据字节获取,非字符)
参数:
name,Redis 的 name
start,起始位置(字节)
end,结束位置(字节)
如: "李小明" ,0-3表示 "李"
setrange(name, offset, value):修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
参数:
offset,字符串的索引,字节(一个汉字三个字节)
value,要设置的值
setbit(name, offset, value):对name对应值的二进制表示的位进行操作
参数:
name,redis的name
offset,位的索引(将值变换成二进制后再进行索引)
value,值只能是 1 或 0
getbit(name, offset):获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None):获取name对应的值的二进制表示中 1 的个数
参数:
key,Redis的name
start,位起始位置
end,位结束位置
bitop(operation, dest, *keys):获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
dest, 新的Redis的name
*keys,要查找的Redis的name
strlen(name):返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1):自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name,Redis的name
amount,自增数(必须是整数)
注:同incrby
incrbyfloat(self, name, amount=1.0):自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name,Redis的name
amount,自增数(浮点型)
decr(self, name, amount=1):自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
参数:
name,Redis的name
amount,自减数(整数)
append(key, value):在redis name对应的值后面追加内容
参数:
key, redis的name
value, 要追加的字符串
Hash操作,redis中Hash在内存中的存储格式如下图: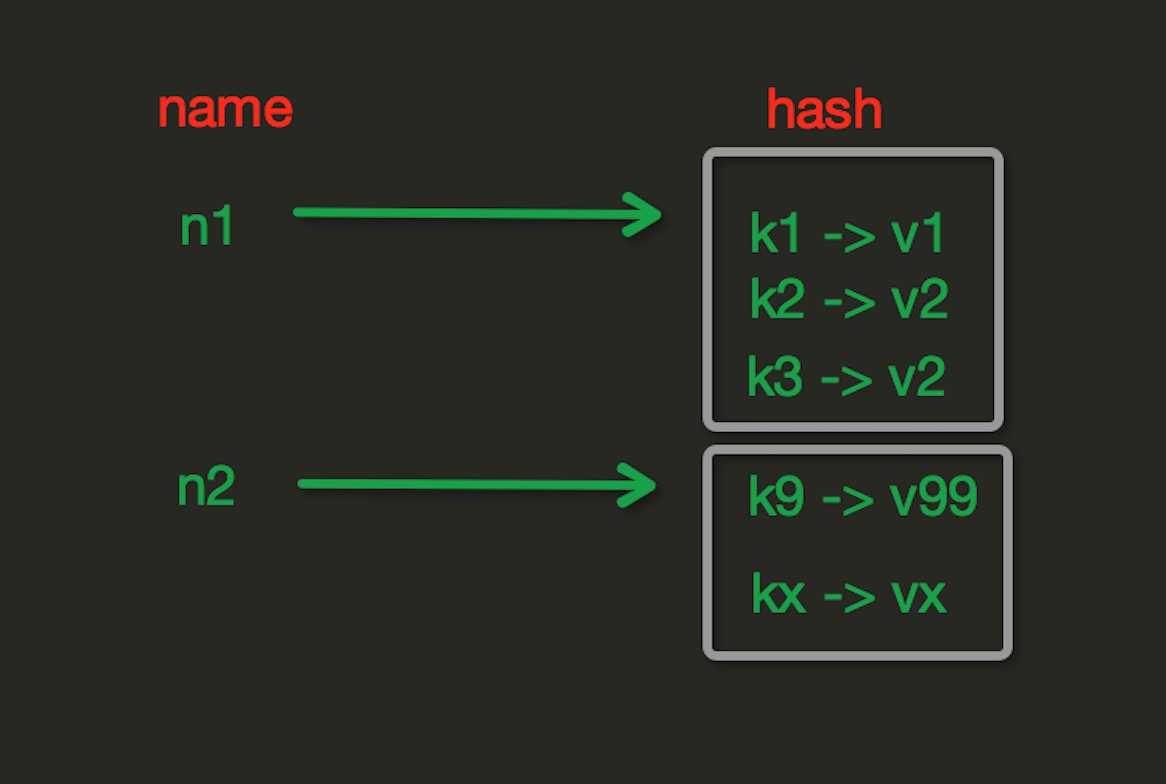
hset(name, key, value):name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
name,redis的name
key,name对应的hash中的key
value,name对应的hash中的value
注:
hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping):在name对应的hash中批量设置键值对
参数:
name,redis的name
mapping,字典,如:{‘k1‘:‘v1‘, ‘k2‘: ‘v2‘}
hget(name,key):在name对应的hash中获取根据key获取value
hmget(name, keys, *args):在name对应的hash中获取多个key的值
参数:
name,reids对应的name
keys,要获取key集合,如:[‘k1‘, ‘k2‘, ‘k3‘]
*args,要获取的key,如:k1,k2,k3
hgetall(name):获取name对应hash的所有键值
hlen(name):获取name对应的hash中键值对的个数
hkeys(name):获取name对应的hash中所有的key的值
hvals(name):获取name对应的hash中所有的value的值
hexists(name, key):检查name对应的hash是否存在当前传入的key
hdel(name,*keys):将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1):自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name,redis中的name
key, hash对应的key
amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0):自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name,redis中的name
key, hash对应的key
amount,自增数(浮点数)
自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None):增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
name,redis的name
cursor,游标(基于游标分批取获取数据)
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
hscan_iter(name, match=None, count=None):利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
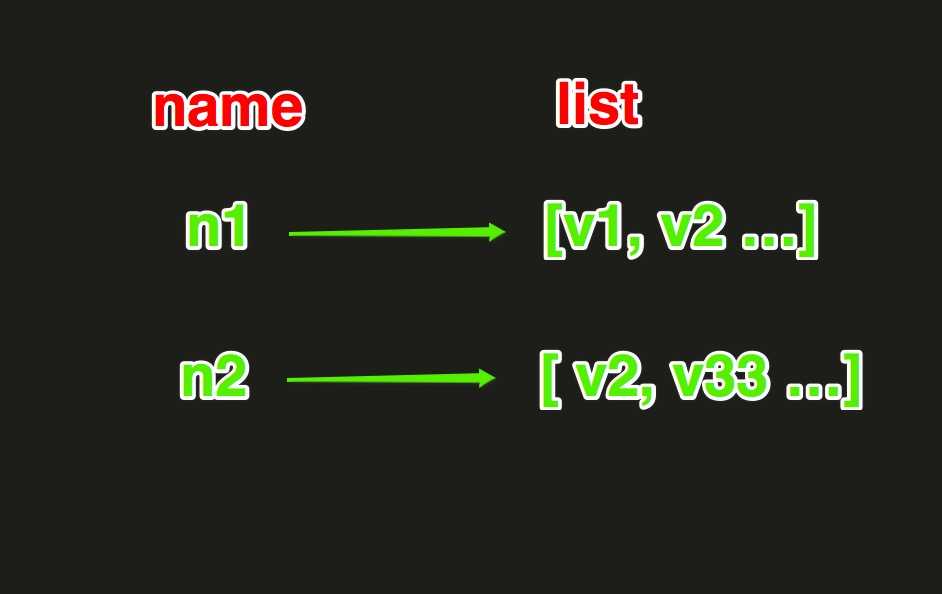
lpush(name,values):在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:
r.lpush(‘oo‘, 11,22,33)
保存顺序为: 33,22,11
扩展:
rpush(name, values) 表示从右向左操作
lpushx(name,value):在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
更多:
rpushx(name, value) 表示从右向左操作
llen(name):name对应的list元素的个数
linsert(name, where, refvalue, value)):在name对应的列表的某一个值前或后插入一个新值
参数:
name,redis的name
where,BEFORE或AFTER
refvalue,标杆值,即:在它前后插入数据
value,要插入的数据
r.lset(name, index, value):对name对应的list中的某一个索引位置重新赋值
参数:
name,redis的name
index,list的索引位置
value,要设置的值
r.lrem(name, value, num):在name对应的list中删除指定的值
参数:
name,redis的name
value,要删除的值
num, num=0,删除列表中所有的指定值;
num=2,从前到后,删除2个;
num=-2,从后向前,删除2个
lpop(name):在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:
rpop(name) 表示从右向左操作
lindex(name, index):在name对应的列表中根据索引获取列表元素
lrange(name, start, end):在name对应的列表分片获取数据
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置
ltrim(name, start, end):在name对应的列表中移除没有在start-end索引之间的值
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置
rpoplpush(src, dst):从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
src,要取数据的列表的name
dst,要添加数据的列表的name
blpop(keys, timeout):将多个列表排列,按照从左到右去pop对应列表的元素
参数:
keys,redis的name的集合
timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
更多:
r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0):从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name): """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ list_count = r.llen(name) for index in xrange(list_count): yield r.lindex(name, index) # 使用 for item in list_iter(‘pp‘): print item
Set操作,Set集合就是不允许重复的列表
sadd(name,values):name对应的集合中添加元素
scard(name):获取name对应的集合中元素个数
sdiff(keys, *args):在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args):获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args):# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args):获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value):检查value是否是name对应的集合的成员
smembers(name):获取name对应的集合的所有成员
smove(src, dst, value):将某个成员从一个集合中移动到另外一个集合
spop(name):从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers):从name对应的集合中随机获取 numbers 个元素
srem(name, values):在name对应的集合中删除某些值
sunion(keys, *args):获取多一个name对应的集合的并集
sunionstore(dest,keys, *args):获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs):在name对应的有序集合中添加元素
zcard(name):获取name对应的有序集合元素的数量
zcount(name, min, max):获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount):自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float):按照索引范围获取name对应的有序集合的元素
参数:
name,redis的name
start,有序集合索引起始位置(非分数)
end,有序集合索引结束位置(非分数)
desc,排序规则,默认按照分数从小到大排序
withscores,是否获取元素的分数,默认只获取元素的值
score_cast_func,对分数进行数据转换的函数
更多:
从大到小排序
zrevrange(name, start, end, withscores=False, score_cast_func=float)
按照分数范围获取name对应的有序集合的元素
zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
从大到小排序
zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value):获取某个值在 name对应的有序集合中的排行(从 0 开始)
更多:
# zrevrank(name, value),从大到小排序
zrangebylex(name, min, max, start=None, num=None):
当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员
对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大
# 参数:
# name,redis的name
# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间
# min,右区间(值)
# start,对结果进行分片处理,索引位置
# num,对结果进行分片处理,索引后面的num个元素
# 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex(‘myzset‘, "-", "[ca") 结果为:[‘aa‘, ‘ba‘, ‘ca‘]
# 更多:
# 从大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values):
RabbitMQ
标签:
原文地址:http://www.cnblogs.com/spykids/p/5372130.html
