标签:
(1) 可靠性
end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
(2) 可扩展性
agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(3) 可管理性
所有agent和colletor由master统一管理, 这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各 个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
(4) 功能可扩展性
正如前面提到的,Flume采用了分层架构:分别为agent,collector和storage。
其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
Flume使用两个组件:Master和Node,Node根据在Master shell或web中动态配置,决定其是作为Agent还是Collector。
Flume自带了很多直接可用的数据源(source),如:
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/18/2050465.html
Flume自带了很多直接可用的数据源(sink),如:
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/18/2050472.html
它的source和sink与agent类似。
Flume自带了很多直接可用的数据源(source),如:
collectorSource[(port)]:Collector source,监听端口汇聚数据
Flume自带了很多直接可用的数据源(sink),如:
(4) Master
注:Flume框架对hadoop和zookeeper的依赖只是在jar包上,并不要求flume启动时必须将hadoop和zookeeper服务也启动。
注意:flume集群整个集群的网络环境要保证稳定,可靠,否则会出现一些莫名错误(比如:agent端发送不了数据到collector)。

$wget http://cloud.github.com/downloads/cloudera/flume/flume-distribution-0.9.4-bin.tar.gz
$tar -xzvf flume-distribution-0.9.4-bin.tar.gz
$cp -rf flume-distribution-0.9.4-bin /usr/local/flume
$vi /etc/profile #添加环境配置
export FLUME_HOME=/usr/local/flume
export PATH=.:$PATH::$FLUME_HOME/bin
$source /etc/profile
$flume #验证安装
Flume master数量的选择原则:
分布式的master能够继续正常工作不会崩溃的前提是正常工作的master数量超过总master数量的一半。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>flume.master.servers</name>
<value>master</value>
</property>
</configuration>
<property>
<name>flume.master.servers</name>
<value>hadoopmaster.com,hadoopedge.com,datanode4.com</value>
<description>A comma-separated list of hostnames, one for each machine in the Flume Master.</description>
</property>
<property>
<name>flume.master.store</name>
<value>zookeeper</value>
<description>How the Flume Master stores node configurations. Must be either ‘zookeeper‘ or ‘memory‘.</description>
</property>
<property>
<name>flume.master.serverid</name>
<value>2</value>
<description>The unique identifier for a machine in a Flume Master ensemble. Must be different on every master instance.</description>
</property>
注意:flume.master.serverid 属性的配置主要是针对master,集群上Master节点的flume.master.serverid 必须是不能相同的,该属性的值以0开始。
<property>
<name>flume.collector.event.host</name>
<value>collector</value>
<description>This is the host name of the default "remote" collector.</description>
</property>
<property>
<name>flume.collector.port</name>
<value>35853</value>
<description>This default tcp port that the collector listens to in order to receive events it is collecting.</description>
</property>
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/18/2050443.html。
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/18/2050461.html
1. 设置逻辑节点(logical node)
$flume shell
>connect localhost
>help
>exec map 192.168.0.1 agentA
>exec map 192.168.0.2 agentB
>exec map 192.168.0.3 agentC
>exec map 192.168.0.4 agentD
>exec map 192.168.0.5 agentE
>exec map 192.168.0.6 agentF
>getnodestatus
192.168.0.1 --> IDLE
192.168.0.2 --> IDLE
192.168.0.3 --> IDLE
192.168.0.4 --> IDLE
192.168.0.5 --> IDLE
192.168.0.6 --> IDLE
agentA --> IDLE
agentB --> IDLE
agentC --> IDLE
agentD --> IDLE
agentE --> IDLE
agentF --> IDLE
>exec map 192.168.0.11 collector
2.启动Collector的监听端口
>exec config collector ‘collectorSource(35853)‘ ‘collectorSink("","")‘#collector节点监听35853端口过来的数据,这一部非常重要
$netstat -nalp|grep 35853
3.设置各节点的source和sink
>exec config collector ‘collectorSource(35853)‘ ‘collectorSink("hdfs://namenode/flume/","syslog")‘
>exec config agentA ‘tail("/tmp/log/message")‘ ‘agentBESink("192.168.0.11")‘ #经过实验,好像一个逻辑节点,最多只能有一个source和sink.
>...
>exec config agentF ‘tail("/tmp/log/message")‘ ‘agentBESink("192.168.0.11")‘
以上通过flume shell进行的动态配置,在flume master web中都可以进行,在此不做进一步说明。
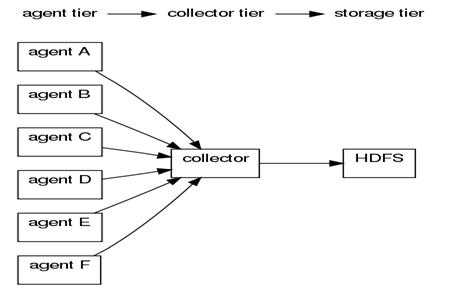
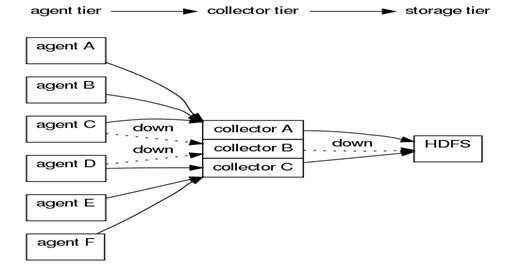
agent*Chain来指定多个Collector来保证其日志传输的可用性。看一下一般正式环境中flume的逻辑图:
这里agentA和agentB指向collectorA,如果CollectorA crach了,根据配置的可靠性级别agent会有相应的动作,我们很可能为了保障高效传输而没有选择E2E(即使是这种方式,Agent本地日志累积过多依然是一个问题),一般会配置多个Collector,形成collector chain。
>exec config agentC ‘tail("/tmp/log/message")‘ ‘agentE2EChain("collectorB:35853","collectorA:35853")‘
>exec config agentD ‘tail("/tmp/log/message")‘ ‘agentE2EChain("collectorB:35853","collectorC:35853")‘
首先,storage层的失败和collector层的失败是一样的,只要数据放不到最终的位置,就认为节点是失败的。我们一定会根据收集数据的可靠性设定合适的传输模式,而且会根据我们的配置,自己控制collector接收数据的情况,collector的性能影响的是整个flume集群的数据吞吐量,所以collector最好单独部署,所以一般不用考虑高可用问题。
agent层的失败,Flume数据安全级别的配置主要Agent的配置上,Agent提供三种级别发送数据到collector:E2E、DFO、BF,在些不赘述。看一下一位大牛的总结:
agent节点监控日志文件夹下的所有文件,每一个agent最多监听1024个文件,每一个文件在agent的都会有一个类似游标的东西,记录监听文件读取的位置,这样每次文件有新的记录产生,那么游标就会读取增量记录,根据agent配置发送到collector的安全层级属性有E2E,DFO。
如果是E2E的情况那么agent节点会首先把文件写入到agent节点的文件夹下,然后发送给collector,如果最终数据最终成功存储到storage层,那么agent删除之前写入的文件,如果没有收到成功的信息,那么就保留信息。
如果agent节点出现问题,那么相当于所有的记录信息都消失了,如果直接重新启动,agent会认为日志文件夹下的所有文件都是没有监听过的,没有文件记录的标示,所以会重新读取文件,这样,日志就会有重复,具体恢复办法如下
将agent节点上监听的日志文件夹下已经发送的日志文件移出,处理完,故障重新启动agent即可。
注:在agent节点失败的情况下,按照失败的时间点,将时间点之前的数据文件移出,将flume.agent.logdir配置的文件夹清空,重新启动agent。
1.Flume在agent端采集数据的时候默认会在/tmp/flume-{user}下生成临时的目录用于存放agent自己截取的日志文件,如果文件过大导致磁盘写满那么agent端会报出
Error closing logicalNode a2-18 sink: No space left on device,所以在配置agent端的时候需要注意
<property>
<name>flume.agent.logdir</name>
<value>/data/tmp/flume-${user.name}/agent</value>
</property>
属性,只要保证flume在7*24小时运行过程agent端不会使该路径flume.agent.logdir磁盘写满即可。
2. Flume在启动时候会去寻找hadoop-core-*.jar的文件,需要修改标准版的hadoop核心jar包的名字 将hadoop-*-core.jar改成hadoop-core-*.jar。
3.Flume集群中的flume必须版本一致。否则会出现莫名其妙的错误。
4.Flume集群收集的日志发送到hdfs上建立文件夹的时间依据是根据event的时间,在源代码上是Clock.unixTime(),所以如果想要根据日志生成的时间来生成文件的话,需要对
com.cloudera.flume.core.EventImpl 类的构造函数
public EventImpl(byte[] s, long timestamp, Priority pri, long nanoTime,
String host, Map<String, byte[]> fields)重新写,解析数组s的内容取出时间,赋给timestamp。
注意:flume的框架会构造s内容是空的数组,用来发送类似简单验证的event,所以需要注意s内容为空的时候timestamp的问题。
5.如果collector和agent不在一个网段的话会发生闪断的现象,这样的话,就会造成agent端不能传送数据个collector所以,在部署agent和collector最好在一个网段。
6.如果在启动master时出现:“试着启动hostname,但是hostname不在master列表里的错误“,这是需要检查是否主机地址和hostname配置的正确与否。
7.在源端,有一个比较大的缺陷,在tail类的source,不支持,断点续传功能。因为重启node后没有记录上次文件读到的位置,从而没办法知道,下次再读时,从什么地方开始读。
特别是在日志文件一直在增加的时候。flume的source node挂了。等flume的source再次开启的这段时间内,增加的日志内容,就没办法被source读取到了。
不过flume有一个execStream的扩展,可以自己写一个监控日志增加情况,把增加的日志,通过自己写的工具把增加的内容,传送给flume的node。再传送给sink的node。
标签:
原文地址:http://www.cnblogs.com/hellochennan/p/5372454.html