标签:
因为编码不对!
什么是编码?编码不对为什么会乱码?
……??
编码转换为什么会丢失数据?
……??
不管是数据库还是网页,都可能碰到过乱码问题
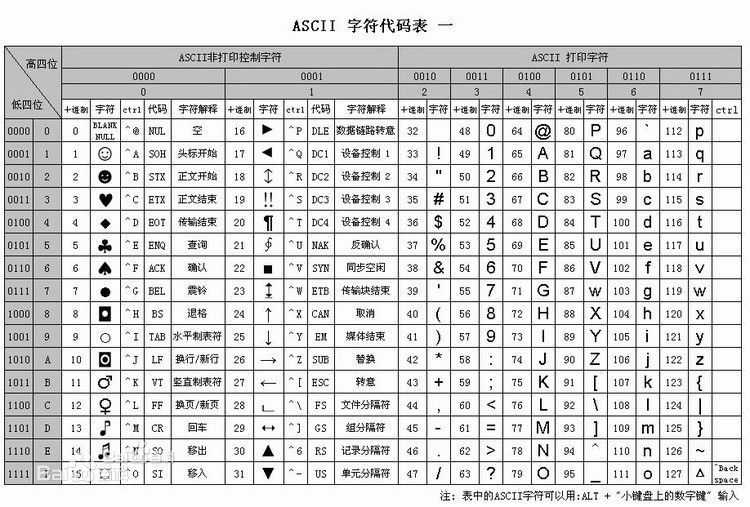
在计算机世界里,所有数据都使用二进制存储,即只有1和0,在人的世界里有中文/英文/阿拉伯文等,还有图片/视频/音频,如何使用二进制存储和显示它们呢?具体使用哪些二进制字符表示哪个符号的这样一种规则就叫编码。编码充当着一个翻译的角色,计算机是美国人发明的,为了存储他们使用的语言abcd等26个英文字母以及常用的符号~!@#¥%……&*()-+,美国有关标准化组织出台了ASCII编码,但是,ASCII编码是单字节编码系统,最多只能表示256个字符,因此ASCII只适用于拉丁文字子母,而其他国家有各种各样的语言文字,比如中文字符有好几万个,于是有了GB2312双子节编码。
GB2312适用于汉字处理、汉字通信等系统之间的信息交换,GB2312共收录6763个常用中文和非汉字图形字符682个,由中国国家标准总局于1980年发布,随着汉字标准的发展,GB2312收录的6千多字明显不够用了,1995年又发布了GBK编码,GBK是GB2312点扩展,向下兼容GB2312编码,GBK编码共收录了21003个汉字。
观察ASCII会发现,ASCII编码只能表示寥寥256个字符,而GB2312共收录6千多个字符,假如想用ASCII来表示六千多个中文,很明显ASCII里面并没有与中文对应的映射关系,所以就显示乱码了。
每个国家都有自己相应的编码规则,为了解决编码不统一的问题,Unicode编码方案应运而生。Unicode是计算机科学领域里的一项业界标准,包括字符集、编码方案等,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求,于1994年正式公布。UTF8就是Unicode编码方案的一种。
UTF8的长度是1-6位,GB2312长度是2位,一个长度为3位的UTF8字符转换成GB2312就会丢失信息,显示乱码,再转换回UTF8也无济于事,因为信息已经丢失。这就是我们有时候在转换编码的时候乱码的原因。
作者:王美建
出处:http://www.cnblogs.com/wangmeijian
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
如果您觉得本篇博文对您有所收获,请点击右下角的 [推荐],谢谢!
标签:
原文地址:http://www.cnblogs.com/wangmeijian/p/5374507.html