标签:des style blog http color 使用 os 文件
公司项目的游戏数据模型文档写在Confluence上,由于在项目初期模型变动比较频繁,手工去将文档中最新的模型结构同步到代码中比较费时费力,而且还很容易出错,于是写了一个小工具来自动化这个同步更新模型到代码中的工作。
如下是一个野怪的数据模型文档:
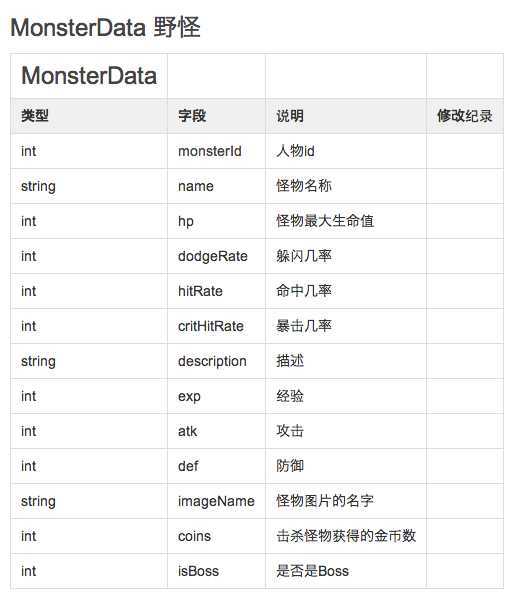
最终在Unity的C#代码中它会是这个形式:
1 using UnityEngine; 2 using System.Collections; 3 4 public class MonsterData 5 { 6 public int monsterId; //人物id 7 public string name; //怪物名称 8 public int hp; //怪物最大生命值 9 public int dodgeRate; //躲闪几率 10 public int hitRate; //命中几率 11 public int critHitRate; //暴击几率 12 public string description; //描述 13 public int exp; //经验 14 public int atk; //攻击 15 public int def; //防御 16 public string imageName; //怪物图片的名字 17 public int coins; //击杀怪物获得的金币数 18 public int isBoss; //是否是Boss 19 }
我们需要的就是将图1中得结构自动写成包含以上代码内容的C#文件。
首先,出于从实现难度和跨平台(前端开发用Mac后端开发用Windows)的考虑,我选择用Python来实现这个工具;
然后,分析这个问题可以知道,这个问题可以分解成2个小的问题来解决:
1.从Conflunce上获取对应文档页面的html table;
2.本地解析这个html table后,将其按照C#类的格式写入到文件中。
对于第一个问题
Confluence自带了Remote API,给开发者提供了非常方便的接口来访问或者更改指定页面的数据,点击这里可以查看它的官方文档。不过这个Remote API默认是关闭的,需要手工在设置里面开启,具体开启的步骤可以看这里,每个版本可能设置的布局略有不同,但是设置的东西都是一样的。
在python中可以使用xmlrpclib来调用Confluence的API。具体的实例可以看这两个链接:Updating a Confluence Wiki with a script和modify wiki page confluence programmatically.这样,第一个问题就解决了。
这里插一句,我在开始的时候不知道有这个Remote API,所以尝试过不用他来实现获取Confluence的页面内容,能够访问到对应的页面,可是一直拿不到想要的html内容,不知道是什么问题,后来因为知道了Remote API,也没再继续尝试自己去获取了,有时间再研究以下。
对于第二个问题
解析html可以用python的库beautifulsoup来实现。关于beautifulsoup你可以看这里。这个beautifulsoup不仅名字好看,功能也异常强大。
好了,解决问题的思路确定了,下面我们可以动手来实现这个工具了。以下便是我实现的代码,python写的不多,所以代码可能比较丑,见谅:)
1 #!/usr/bin/python 2 3 from bs4 import BeautifulSoup 4 5 #for change encoding 6 import sys 7 8 #for login in confluence 9 import xmlrpclib 10 11 import os 12 13 def mkdir(path): 14 15 path = path.strip() 16 17 path = path.rstrip("\\") 18 19 isExists = os.path.exists(path) 20 21 if not isExists: 22 print path + ‘ create successfully!‘ 23 os.makedirs(path) 24 return True 25 else: 26 print path + ‘ exists!‘ 27 return False 28 29 def makeTableContentList(table): 30 result = [] 31 allrows = table.findAll(‘tr‘) 32 rowIndex = 0 33 for row in allrows: 34 result.append([]) 35 #exclude the strike one 36 if row.findAll(‘s‘): 37 continue 38 39 allcols = row.findAll(‘td‘) 40 #print "rowIndex = ",rowIndex 41 #print "allcols = ",allcols 42 43 for col in allcols: 44 #print "col",col 45 thestrings = [unicode(s) for s in col.findAll(text=True)] 46 thetext = ‘‘.join(thestrings) 47 48 result[-1].append(thetext) 49 rowIndex += 1 50 return result 51 52 def makeFile(tableContentList): 53 54 className = tableContentList[0][0] 55 56 outputFile = file("output/" + className + ".cs","w") 57 58 #start to write file 59 60 #write header 61 outputFile.write("using UnityEngine;\n") 62 outputFile.write("using System.Collections;\n\n") 63 outputFile.write("public class " + className + "\n{\n") 64 65 #write members 66 rowCounter = 0 67 for row in tableContentList: 68 if row and rowCounter > 0: #rowCounter == 0 is className 69 70 #--------format--------- 71 beginSpaces = " public " 72 typeString = "{:<12}".format(row[0]) 73 memberName = "{:<30}".format(row[1] + ";") 74 comments = "" 75 76 if len(row[2]) > 1: 77 comments = " //" + row[2] 78 79 s = beginSpaces + typeString + memberName + comments + "\n" 80 81 outputFile.write(s) 82 83 rowCounter += 1 84 85 #write tail 86 outputFile.write("}\n") 87 88 outputFile.close() 89 90 def setDefaultEncodingUTF8(): 91 reload(sys) 92 sys.setdefaultencoding(‘utf-8‘) 93 94 def loadConfluencePage(pageID): 95 96 # login Confluence 97 CONFLUENCE_URL = "http://192.168.1.119:8090/rpc/xmlrpc" 98 CONFLUENCE_USER_NAME = "userName" # use your Confluence user Name 99 CONFLUENCE_PASSWORD = "password" # use your Confluence password 100 101 # get this from the page url while editing 102 # e.g. ../editpage.action?pageId=132350005 <-- here 103 #PAGE_ID = "4686604" 104 105 client = xmlrpclib.Server(CONFLUENCE_URL, verbose = 0) 106 auth_token = client.confluence2.login(CONFLUENCE_USER_NAME, CONFLUENCE_PASSWORD) 107 page = client.confluence2.getPage(auth_token, pageID) 108 109 htmlContent = page[‘content‘] 110 111 client.confluence2.logout(auth_token) 112 113 return htmlContent 114 115 def main(): 116 117 #change Encoding to UTF8 118 setDefaultEncodingUTF8() 119 120 #make output directory 121 mkdir(sys.path[0] + "/output") 122 123 #there are two pages contain data model 124 pageIDs = ("4686602","4686604") 125 126 for pageID in pageIDs: 127 128 print "Make data in page with id: ",pageID 129 130 htmlContent = loadConfluencePage(pageID) 131 132 soup = BeautifulSoup(htmlContent) 133 #print soup.prettify() 134 135 tables = soup.findAll(‘table‘) 136 137 for table in tables: 138 #print table 139 result = makeTableContentList(table) 140 makeFile(result) 141 #print "result = " 142 #print result 143 144 print "Make Over! Have a nice day!" 145 146 if __name__ == "__main__": 147 main()
OK,就到这里,希望大家喜欢:)
转载请注明出处,谢谢:)
[原创]从Confluence获取html table并将其序列化为C#类文件的工具,布布扣,bubuko.com
[原创]从Confluence获取html table并将其序列化为C#类文件的工具
标签:des style blog http color 使用 os 文件
原文地址:http://www.cnblogs.com/flyFreeZn/p/3860848.html