标签:des style blog http color 使用 os strong
MongoDB以文档的形式来存储数据,此结果类似于JSON键值对。文档类似于编程语言中将键和值关联起来的结构(比如:字典、Map、哈希表、关联数组)。MongoDB文档是以BOSN文档的形式存在的。BSON是JSON附加了类型信息的一种二进制的表现形式。
文档中的字段可以是任何BSON类型,比如(文档类型、数组、文档数组)
MongoDB将所有文档存储在collection中,collection是一组相关的文档集合,这一组文档集合拥有共同的索引,collection类似于关系型数据库中的表。
数据库操作,有读操作和写操作,我们先来看读操作
MongoDB只针对一个特定的collection来查询。查询通过指定的查询条件来指定要查询的文档,mongoDB将结果返回给客户端,查询操作还可能包含投影,投影指定了要返回文档的字段,投影减小了mongoDB返回到客户端的数据量。
查询接口
MongoDB提供了一个db.collection.find()方法来执行查询,该方法接受查询条件和投影,并返回给客户端一个获取匹配文档的指针。还可以为查询添加limit、skip、sort等方法。
注:在内部, db.collection.findOne() 方法是db.collection.find()查询结果并限制1
查询collection中的所有文档:
指定一个空查询文档用来查询所有该collection中的文档:
db.inventory.find({})
没有指定查询文档的 find()方法和指定了空查询文档的方法是等价的
db.inventory.find()
指定相等条件:
相等条件通过使用查询文档 { <field>: <value> }来选择所有包含<field>属性并且属性值为<value>的文档
下例从inventory 中获取了所有type属性为snacks的文档
db.inventory.find( { type: "snacks" } )
通过查询操作符来指定条件:
一个查询文档中可以使用查询操作符来查询指定文档。
下例从inventory 中获取了所有type属性为snacks或food的文档
db.inventory.find( { type: { $in: [ ‘food‘, ‘snacks‘ ] } } )
尽管可以使用$or操作符达到同样的效果,但是$in操作符通常用在同一字段的相等比较上
db.inventory.find( { $or: [ { type: ‘food‘ }, { type: ‘snacks‘ } ] } )
指定AND条件
一个复合查询可以为多个字段指定查询条件,隐式地,一个逻辑AND链接了一个复合查询的子句,所以查询collection中的文档需要满足所有的条件。
在下例中,一个查询文档指定了type上的相等匹配和price上的小于比较
db.inventory.find( { type: ‘food‘, price: { $lt: 9.95 } } )
这个查询选择了所有type字段等于food并且price字段小于9.95的文档
比较操作符有:$gt(大于)、$gte(大于等于)、$in(在……中)、$lt(小于)、$lte(小于等于)、$ne(不等于)、$nin(不在……中)
指定OR条件
使用$or操作符,你可以指定一个复合查询以“或”来链接子句,因此查询语句会选择至少满足一个条件的文档。
下例中查询语句查询所有qty字段大于100或者price字段小于9.95的文档
db.inventory.find({ $or: [ { qty: { $gt: 100 } }, { price: { $lt: 9.95 } } ] })
AND和OR混合使用
下例中,复合查询文档选中了type字段是’food’并且要么qty大于100要么price小于9.95的文档
db.inventory.find({ type: ‘food‘, $or: [ { qty: { $gt: 100 } }, { price: { $lt: 9.95 } } ] })
内嵌文档
当字段值为一个文档时,查询可以指定一个准确匹配的内嵌文档或者指定使用点符号链接来匹配内嵌文档的单个字段。
精确匹配内嵌文档
可以通过在查询文档中提供一个内嵌文档来对文档进行等值比较{ <field>:<value> } ,其中<value>是内嵌文档,内嵌文档是一个精确匹配,包括字段的顺序。
在下例中,查询producer 字段是一个内嵌文档,并且该内嵌文档仅包含了company字段值为‘ABC123‘并且address字段值为‘123 Street‘,且字段顺序必须一致
db.inventory.find({ producer:{ company: ‘ABC123‘, address: ‘123 Street‘ } })
内嵌文档字段字段的相等匹配
使用点符号在内嵌文档中进行字段的匹配。该内嵌文档中可能还会包含其他字段,所以此方法是指精确匹配内嵌文档中指定的字段,而不是精确匹配整个内嵌文档。
在下例中,查询使用点符号来匹配所有producer字段 是内嵌文档的文档,并且producer 的company字段值为‘ABC123‘,也可能会有其他字段。
db.inventory.find( { ‘producer.company‘: ‘ABC123‘ } )
数组
当字段值是一个数组时,可以通过指定该数组来进行精确匹配。如果该数组中的元素是内嵌文档,你还可以通过使用点符号来查询内嵌文档中的指定属性。
如果你使用$elemMatch操作符来指定多个条件,那么数组中必须至少有一个元素满足所有的条件。
考虑一下inventory 集合,包含了如下文档:
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] }
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] }
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] }
数组精确匹配
使用查询文档 { <field>: <value> } 来对数组进行相等比较,其中<value>就是要匹配的数组。数组的相等性比较要求数组元素和顺序必须一致。
如下查询语句会查询出所有ratings 字段为一个数组,并且数组元素为5, 8, 9,且顺序一致。
db.inventory.find( { ratings: [ 5, 8, 9 ] } )
查询结果如下:
{ "_id" : 5, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
匹配数组中的一个元素
可以通过指定数组中的某个元素来匹配数组。如果数组中存在至少一个匹配是元素,那么该数组就是匹配查询条件的;
如下查询语句会查询出所有的ratings 字段为一个数组,且数组元素中至少有一个元素为5
db.inventory.find( { ratings: 5 } )
查询结果如下:
{ "_id" : 5, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
{ "_id" : 6, "type" : "food", "item" : "bbb", "ratings" : [ 5, 9 ] }
{ "_id" : 7, "type" : "food", "item" : "ccc", "ratings" : [ 9, 5, 8 ] }
匹配数组中指定的元素
可以通过点符号来匹配数组中指定下标或位置的元素。
如下查询中,用点符号指定了查询所有ratings 的第一个元素为5的文档
db.inventory.find( { ‘ratings.0‘: 5 } )
查询结果如下:
{ "_id" : 5, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
{ "_id" : 6, "type" : "food", "item" : "bbb", "ratings" : [ 5, 9 ] }
为数组元素指定混合条件
单个元素满足所有条件:
使用$elemMatch操作符为数组中的单个元素指定混合条件,数组中至少有一个元素满足所有条件。
如下查询中,ratings 中至少有一个元素满足大于5并且小于9
db.inventory.find( { ratings: { $elemMatch: { $gt: 5, $lt: 9 } } } )
查询结果如下,其中ratings 数组中只有8满足所有的查询条件
{ "_id" : 5, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
{ "_id" : 7, "type" : "food", "item" : "ccc", "ratings" : [ 9, 5, 8 ] }
混合元素满足条件
如下查询中,查询文档的ratings 数组中以一种组合满足查询条件的方式,一个元素满足大于5的条件,而另一个元素满足小于9的条件,或者一个元素满足所有的条件:
db.inventory.find( { ratings: { $gt: 5, $lt: 9 } } )
查询结果如下:
{ "_id" : 5, "type" : "food", "item" : "aaa", "ratings" : [ 5, 8, 9 ] }
{ "_id" : 6, "type" : "food", "item" : "bbb", "ratings" : [ 5, 9 ] }
{ "_id" : 7, "type" : "food", "item" : "ccc", "ratings" : [ 9, 5, 8 ] }
Ratings字段为[ 5, 9 ] 的文档满足条件是因为元素9大于5,并且元素5小于9
内嵌文档数组
考虑以下文档集合inventory:
{ _id: 100, type: "food", item: "xyz", qty: 25, price: 2.5, ratings: [ 5, 8, 9 ], memos: [ { memo: "on time", by: "shipping" }, { memo: "approved", by: "billing" } ] } { _id: 101, type: "fruit", item: "jkl", qty: 10, price: 4.25, ratings: [ 5, 9 ], memos: [ { memo: "on time", by: "payment" }, { memo: "delayed", by: "shipping" } ] }
使用数组索引匹配内嵌文档字段
可以使用点符号来匹配内嵌文档所在数组的下标。
以下查询选中了所有memos 数组的第一个元素的by字段为shipping的文档
db.inventory.find( { ‘memos.0.by‘: ‘shipping‘ } )
查询结果如下:
{ _id: 100, type: "food", item: "xyz", qty: 25, price: 2.5, ratings: [ 5, 8, 9 ], memos: [ { memo: "on time", by: "shipping" }, { memo: "approved", by: "billing" } ] }
不使用数组索引匹配字段
如果不知道数组文档的下标,可以将数组字段名称和子文档字段名称用点符号链接起来。
以下查询选中了memos 字段数组至少有一个内嵌文档的by属性的值为‘shipping‘:
db.inventory.find( { ‘memos.by‘: ‘shipping‘ } )
查询结果如下:
{ _id: 100, type: "food", item: "xyz", qty: 25, price: 2.5, ratings: [ 5, 8, 9 ], memos: [ { memo: "on time", by: "shipping" }, { memo: "approved", by: "billing" } ] } { _id: 101, type: "fruit", item: "jkl", qty: 10, price: 4.25, ratings: [ 5, 9 ], memos: [ { memo: "on time", by: "payment" }, { memo: "delayed", by: "shipping" } ] }
为数组文档指定混合查询条件
单个元素满足所有条件:
使用 $elemMatch操作符可以为数组文档指定查询条件,至少要有一个文档满足所有条件。
以下查询会选中memos 中所有数组元素内嵌文档至少有一个满足memo 属性值为‘on time‘ 并且by属性值为‘shipping‘
查询结果如下:
{ _id: 100, type: "food", item: "xyz", qty: 25, price: 2.5, ratings: [ 5, 8, 9 ], memos: [ { memo: "on time", by: "shipping" }, { memo: "approved", by: "billing" } ] }
混合元素满足条件
如下查询中,查询文档的memos 数组中以一种组合满足查询条件的方式,一个文档的memo 字段满足值为‘on time‘的条件,而另一个文档的by字段满足值为‘shipping‘的条件,或者一个文档满足所有的条件:
db.inventory.find({ ‘memos.memo‘: ‘on time‘, ‘memos.by‘: ‘shipping‘ })
查询结果如下:
{ _id: 100, type: "food", item: "xyz", qty: 25, price: 2.5, ratings: [ 5, 8, 9 ], memos: [ { memo: "on time", by: "shipping" }, { memo: "approved", by: "billing" } ] } { _id: 101, type: "fruit", item: "jkl", qty: 10, price: 4.25, ratings: [ 5, 9 ], memos: [ { memo: "on time", by: "payment" }, { memo: "delayed", by: "shipping" } ] }
默认情况下,mongoDB查询会将查询文档的所有字段返回到客户端,为了减少mongoDB不必要的数据传输,在查询的同时可以指定投影,来只返回那些需要返回到客户端的字段。可以通过投影对查询结果集中的字段进行限制,投影通过find方法的第二个参数来指定,投影通过提供文档形式的字段列表来指定字段的包含(如{ field: 1 })和排除({ field: 0 })。
注意:
_id字段默认是包含在结果集中的。要从结果集中排除_id字段,可以显式指定排除_id字段(如{ _id: 0 })
不可以在一个投影中同时指定包含和排除,_id字段除外。
返回查询结果中匹配的字段
如果没有指定投影,find()放将会返回结果集中的所有字段。
db.inventory.find( { type: ‘food‘ } )
只返回结果集中指定的字段和_id字段
一个投影可以显式指定几个包含字段。如下查询中find方法返回所有满足查询条件的文档,但结果集的文档中只有item和qty字段,还有默认的_id字段
db.inventory.find( { type: ‘food‘ }, { item: 1, qty: 1 } )
只返回结果集中指定的字段
可以通过在投影中显式将结果中的_id字段排除,如下:
db.inventory.find( { type: ‘food‘ }, { item: 1, qty: 1, _id:0 } )
只返回未被排除的字段
可以使用以下形式来排除一个或者一组字段:
db.inventory.find( { type: ‘food‘ }, { type:0 } )
此查询会返回所有type值为’food’的文档,结果集中不包含type字段。
数组字段投影
只能使用 $elemMatch和 $slice操作符对数组投影
更多例子:
从结果集中排除指定字段
db.records.find( { "user_id": { $lt: 42} }, { history: 0} )
此查询通过records集合筛选了符合查询条件 { "user_id":{ $lt: 42} }的文档,但是把history字段排除在外
返回两个字段,并包含_id字段
db.records.find( { "user_id": { $lt: 42} }, { "name": 1, "email": 1} )
此查询通过records集合筛选了符合查询条件 { "user_id":{ $lt: 42} }的文档,但是只包括name和email字段,还有默认的_id字段
返回两个字段,并排除_id字段
db.records.find( { "user_id": { $lt: 42} }, { "_id": 0, "name": 1 , "email": 1 } )
此查询通过records集合筛选了符合查询条件 { "user_id":{ $lt: 42} }的文档,但是只包括name和email字段,但是将_id字段显示的排除在外
db.collection.find() 方法返回指向查询结果的游标对象,要想访问查询结果,需要遍历此游标对象,在mongo shell中db.inventory.find( { type: ‘food‘ } );
方法默认会打印出前20条文档,可以通过DBQuery.shellBatchSize来指定默认的遍历条数。
以下描述了手工迭代游标和使用迭代器索引访问文档。
游标手工迭代:
在mongo命令窗口中,将find方法的返回游标付给一个变量时,游标就不会自动迭代。
以下例子中,游标变量会默认迭代20次,并打印出文档。
var myCursor = db.inventory.find( { type: ‘food‘ } ); myCursor
还可以使用游标的next方法来访问文档,例子如下:
var myCursor = db.inventory.find( { type: ‘food‘ } ); while (myCursor.hasNext()) { print(tojson(myCursor.next())); }
还可以使用游标的forEach()方法迭代,并访问文档,如下所示:
var myCursor = db.inventory.find( { type: ‘food‘ } ); myCursor.forEach(printjson);
可以对DBQuery.shellBatchSize赋值来改变命令窗口中迭代20条的默认行为:
DBQuery.shellBatchSize =10
迭代器下标:
在mongo命令窗口中,可以在游标对象上使用toArray()方法,将查询结果转化为一个数组:
var myCursor = db.inventory.find( { type: ‘food‘ } ); var documentArray = myCursor.toArray(); var myDocument = documentArray[3];
toArray()方法将游标返回的所有文档加载到RAM中,toArray()方法会将游标遍历完。
另外,在一些驱动中提供了通过游标下标的方式来访问文档,这只不过是在游标上调用 toArray()方法,然后用下标访问返回数组的一种快捷方法罢了:
var myCursor = db.inventory.find( { type: ‘food‘ } ); var myDocument = myCursor[3];
myCursor[3]跟下面的是一样的:
myCursor.toArray() [3];
不活动游标的关闭
默认情况下,服务器会关闭在10分钟之内不活动的游标对象,或者游标对象已被被遍历完,为了覆盖这种默认行为,可以通过在查询语句中指定noTimeout 协议标识,然而这样设置之后,你要确保要么手动关闭游标,要么把它遍历完。在 mongo shell中你可以这样设置:
var myCursor = db.inventory.find().addOption(DBQuery.Option.noTimeout);
游标批次
MongoDB服务器以批次的方式返回结果,批次的大小不会超过 BSON文档最大大小(默认为16megabytes)
对于大多数的查询来说,第一批次不会超过101个文档或者1 megabyte,接下来的批次大小是4 megabytes,我们可以通过batchSize和limit方法来覆盖默认大小
对于在没有索引的查询上进行排序,服务器必须要加载所有的文档来执行排序操作,所以第一批次会返回所有文档。
当你遍历游标,并到达该批次的结尾时,如果有更多记录cursor.next()会执行一个获取操作来获取下一批次的数据。当在遍历游标时,如果想知道本批次还有多少未遍历,可以使用objsLeftInBatch() 来查询
var myCursor = db.inventory.find(); var myFirstDocument = myCursor.hasNext() ? myCursor.next() : null; myCursor.objsLeftInBatch();
游标信息
db.serverStatus() 返回一个文档,其中包含了metrics 字段,metrics 字段包含了一个cursor字段,可以调用db.serverStatus().metrics.cursor
返回以下信息:
{ "timedOut" : <number> "open" : { "noTimeout" : <number>, "pinned" : <number>, "total" : <number> } }
索引可以提高读取操作的效率,而不用读取所有的数据。使mongoDB的查询操作变得简单。
创建索引
如果应用程序要在一个collection中查询特定的字段,那么在查询字段上添加索引可以避免扫描整个collection来获取需要的数据。
比如:一个应用要查询inventory 集合中的type字段
db.inventory.find( { type: typeValue } );
为了提高此查询的效率,可以在inventory集合上添加type字段的升序或者降序索引,在mongo命令行中可以使用db.collection.ensureIndex()方法来添加:
db.inventory.ensureIndex( { type: 1 } )
为了优化查询,索引还为排序操作提供支持,并且更高效的利用存储。
查询的选择性
一些查询操作是不具有选择性的,这些查询不能高效的使用索引或者根本就不能使用索引。
不等操作符 $nin 和 $ne就不怎么有选择性,因为他们经常要去匹配一大部分索引。因此大部分情况下,$nin 和 $ne对索引查询不会比遍历所有文档强多少。
查询中指定正则表达式不会使用索引,除了一种情况,就正则表达式字符串以锚开头。
分片集群允许你以透明的方式将一个数据集分片部署到一个集群的不同mongoDB实例上。对于分片集群,应用程序来协调查询集群中的某一个mongoDB实例。
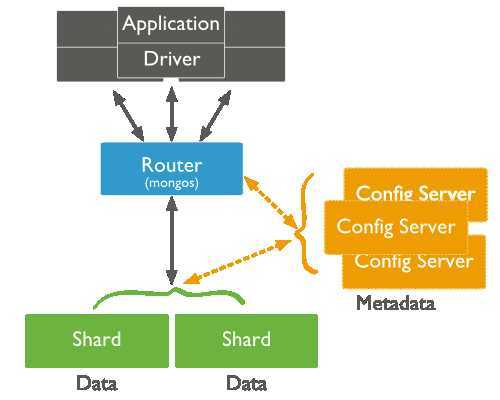
集群示例图
在集群上执行读取操作最有效率的是直接读取集群上的指定分片。对分片上的集合查询应该包括collection的分片键(shard key)。当一个查询包含了分片键(shard key),mongos就可以使用数据库配置(config database)的集群元信息将查询路由到指定分片。
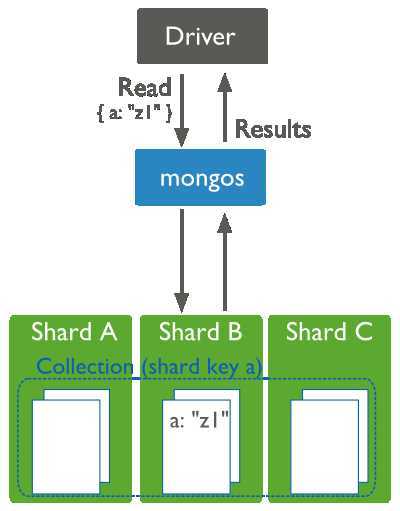
对分片集群执行读取操作,查询条件包含了分片键,查询分发器mongos可以将查询定位到合适的分片
如果查询中没有包含分片键,mongos必须将查询定位到所有的集群分片上。这种分散聚集查询非常低效。在大的集群上,分散聚集查询很难执行常规的操作。
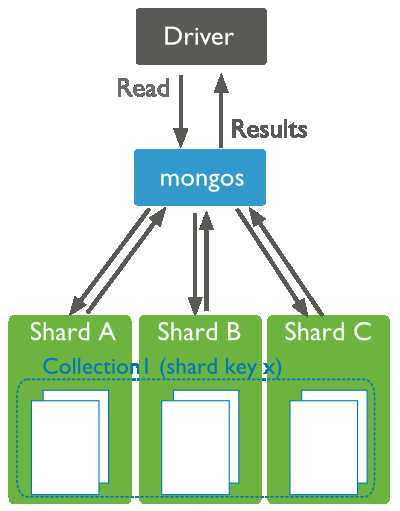
对分片集群执行读取操作,查询条件没有包含分片键,查询分发器mongos必须要将查询广播到所有的分片的collection上
副本集(Replica sets)使用读优先(read preferences)来决定怎么将读取操作定位到副本集成员。默认情况下,mongoDB总是从副本集的主副本读取。你可以通过修改读优先( read preference )模式来修改此行为。
你可以基于每个连接或者每个查询配置读优先( read preference )模式,允许从次要副本中读取:
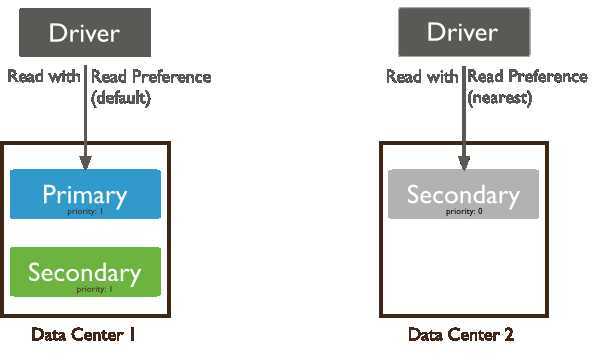
从副本集总读取,默认读优先被定向到了主副本,读优先的nearest 将读取操作定向到了最近的副本
从次要副本读取数据不能保证数据就是主副本中的当前状态。次要副本的状态总是落后主副本一段时间。通常,应用并不依赖这种严格一致性,但是开发人员应该总是考虑应用的读优先。
游标上的 explain()方法允许你对查询系统进行监视,此方法对于分析查询效率和如何使用索引非常有用。explain()方法只是测试查询操作,并不对查询性能计时。由于explain()方法会尝试多次查询计划,所以它并不能准确反映计时查询性能。
计算一个查询的性能:
在find()方法返回的游标上调用explain()方法。
NoSql数据库初探-mongoDB读操作,布布扣,bubuko.com
标签:des style blog http color 使用 os strong
原文地址:http://www.cnblogs.com/lmtoo/p/3873891.html