标签:
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下
主要包括公历/农历日期,以及忌宜信息的等。但是手里并没有现成的数据可供使用,怎么办呢?
革命前辈曾经说过,没有枪,没有炮,敌(wang)人(luo)给我们造!网络上有很多现成的在线
万年历应用可供使用,虽然没有现成接口,但是我们可以伸出手来,自己去拿。也就是所谓的数据
抓取。
这里介绍两个使用的工具,httpClient以及jsoup,简介如下:
HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。
httpClient使用方法如下:
1. 创建HttpClient对象。
2. 创建请求方法的实例,并指定请求URL。
3. 调用HttpClient对象的execute(HttpUriRequest request)发送请求,该方法返回一个HttpResponse。
4. 调用HttpResponse相关方法获取相应内容。
5. 释放连接。
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
需要更多信息可以参见官网
httpClient:http://hc.apache.org/httpcomponents-client-5.0.x/index.html
jsoup:http://jsoup.org/
接下来我们直接上代码,这里我们抓取2345在线万年历的数据 http://tools.2345.com/rili.htm
首先我们定义一个实体类Almanac来存储黄历数据
Almanac.java
1 package com.likx.picker.util.bean; 2 3 /** 4 * 万年历工具实体类 5 * 6 * @author 溯源blog 7 * 2016年4月11日 8 */ 9 public class Almanac { 10 private String solar; /* 阳历 e.g.2016年 4月11日 星期一 */ 11 private String lunar; /* 阴历 e.g. 猴年 三月初五*/ 12 private String chineseAra; /* 天干地支纪年法 e.g.丙申年 壬辰月 癸亥日*/ 13 private String should; /* 宜e.g. 求子 祈福 开光 祭祀 安床*/ 14 private String avoid; /* 忌 e.g. 玉堂(黄道)危日,忌出行*/ 15 16 public String getSolar() { 17 return solar; 18 } 19 20 public void setSolar(String date) { 21 this.solar = date; 22 } 23 24 public String getLunar() { 25 return lunar; 26 } 27 28 public void setLunar(String lunar) { 29 this.lunar = lunar; 30 } 31 32 public String getChineseAra() { 33 return chineseAra; 34 } 35 36 public void setChineseAra(String chineseAra) { 37 this.chineseAra = chineseAra; 38 } 39 40 public String getAvoid() { 41 return avoid; 42 } 43 44 public void setAvoid(String avoid) { 45 this.avoid = avoid; 46 } 47 48 public String getShould() { 49 return should; 50 } 51 52 public void setShould(String should) { 53 this.should = should; 54 } 55 56 public Almanac(String solar, String lunar, String chineseAra, String should, 57 String avoid) { 58 this.solar = solar; 59 this.lunar = lunar; 60 this.chineseAra = chineseAra; 61 this.should = should; 62 this.avoid = avoid; 63 } 64 }
然后是抓取解析的主程序,写程序之前需要在官网下载需要的jar包
AlmanacUtil.java
package com.likx.picker.util; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import org.apache.http.HttpEntity; import org.apache.http.ParseException; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** *<STRONG>类描述</STRONG> : 2345万年历信息爬取工具<p> * * @version 1.0 <p> * @author 溯源blog * * <STRONG>创建时间</STRONG> : 2016年4月11日 下午14:15:44<p> * <STRONG>修改历史</STRONG> :<p> *<pre> * 修改人 修改时间 修改内容 * --------------- ------------------- ----------------------------------- *</pre> */ public class AlmanacUtil { /** * 单例工具类 */ private AlmanacUtil() { } /** * 获取万年历信息 * @return */ public static Almanac getAlmanac(){ String url="http://tools.2345.com/rili.htm"; String html=pickData(url); Almanac almanac=analyzeHTMLByString(html); return almanac; } /* * 爬取网页信息 */ private static String pickData(String url) { CloseableHttpClient httpclient = HttpClients.createDefault(); try { HttpGet httpget = new HttpGet(url); CloseableHttpResponse response = httpclient.execute(httpget); try { // 获取响应实体 HttpEntity entity = response.getEntity(); // 打印响应状态 if (entity != null) { return EntityUtils.toString(entity); } } finally { response.close(); } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { // 关闭连接,释放资源 try { httpclient.close(); } catch (IOException e) { e.printStackTrace(); } } return null; } /* * 使用jsoup解析网页信息 */ private static Almanac analyzeHTMLByString(String html){ String solarDate,lunarDate,chineseAra,should,avoid=" "; Document document = Jsoup.parse(html); //公历时间 solarDate=getSolarDate(); //农历时间 Element eLunarDate=document.getElementById("info_nong"); lunarDate=eLunarDate.child(0).html().substring(1,3)+eLunarDate.html().substring(11); //天干地支纪年法 Element eChineseAra=document.getElementById("info_chang"); chineseAra=eChineseAra.text().toString(); //宜 should=getSuggestion(document,"yi"); //忌 avoid=getSuggestion(document,"ji"); Almanac almanac=new Almanac(solarDate,lunarDate,chineseAra,should,avoid); return almanac; } /* * 获取忌/宜 */ private static String getSuggestion(Document doc,String id){ Element element=doc.getElementById(id); Elements elements=element.getElementsByTag("a"); StringBuffer sb=new StringBuffer(); for (Element e : elements) { sb.append(e.text()+" "); } return sb.toString(); } /* * 获取公历时间,用yyyy年MM月dd日 EEEE格式表示。 * @return yyyy年MM月dd日 EEEE */ private static String getSolarDate() { Calendar calendar = Calendar.getInstance(); Date solarDate = calendar.getTime(); SimpleDateFormat formatter = new SimpleDateFormat("yyyy年MM月dd日 EEEE"); return formatter.format(solarDate); } }
为了简单明了我把抓取解析抽象成了几个独立的方法,
其中pickData()方法使用httpClient来抓取数据到一个字符串中(就是在网页上点击查看源代码看到的HTML源码),
analyzeHTMLByString()方法来解析抓取到的字符串,getSuggestion方法把抓取方法类似的宜忌数据抽象到了
一起,另外因为公历时间可以很容易的自己生成就没有在网页上爬取。
然后下面是一个测试类简单测试下效果:
AlmanacUtilTest.java
package com.likx.picker.util.test; public class AlmanacUtilTest { public static void main(String args[]){ Almanac almanac=AlmanacUtil.getAlmanac(); System.out.println("公历时间:"+almanac.getSolar()); System.out.println("农历时间:"+almanac.getLunar()); System.out.println("天干地支:"+almanac.getChineseAra()); System.out.println("宜:"+almanac.getShould()); System.out.println("忌:"+almanac.getAvoid()); } }
运行结果如下:
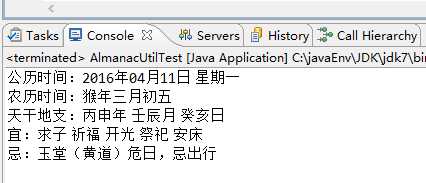
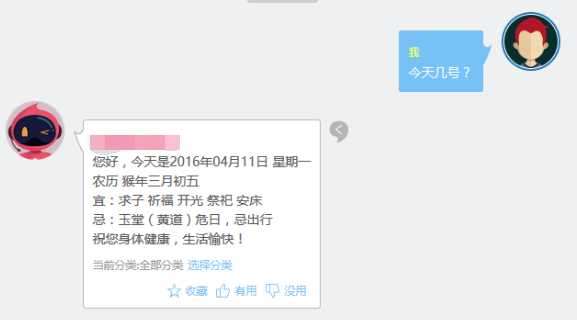
集成到实际项目中效果是这样的:
另外最近博客一直没怎么更新,因为最近考虑到技术氛围的原因,离开了对日外包行业,前往
一家互联网公司就职。说一下最近的感受,那就是一个程序员最核心的竞争力不是学会了多少框架,
掌握多少种工具(当然这些对于程序员也不可或缺),而是扎实的基础以及快速学习的能力,比如今天
这个项目,从对httpClient,jsoup工具一无所知到编写出Demo代码总计大概1个多小时,在之前对于
我来说是不可想象的,在技术氛围浓厚的地方快速get技能的感觉,非常好。
当然本例只是一个非常浅显的小例子,网页上内容也很容易抓取,httpClient及jsoup工具更多强大
的地方没有体现到,比如httpClient不仅可以发送get请求,而且可以发送post请求,提交表单,传送
文件,还比如jsoup最强大的地方在于它支持仿jquery的选择器。本例仅仅使用了最简单的document.getElementById()
匹配元素,实际上jsoup的选择器异常强大,可以说它就是java版的jquery,比如这样:
Elements links = doc.select("a[href]"); // a with href
Elements pngs = doc.select("img[src$=.png]");
// img with src ending .png
Element masthead = doc.select("div.masthead").first();
// div with class=masthead
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
另外还有很多强大的功能水平有限就不一一列举了,感兴趣的可以参照官网文档,也欢迎交流指正。新技能get起来!
本文版权归作者及博客园所有,转载请注明作者及原文出处
溯源blog http://www.cnblogs.com/lkxsnow/
使用java开源工具httpClient及jsoup抓取解析网页数据
标签:
原文地址:http://www.cnblogs.com/lkxsnow/p/5380164.html