标签:
一个页面上有很多的ajax请求,这样的页面右键查看源文件是没法看到全部的html。事实上,这种网页也是从正常的html页面改造过来的,常用的一个场景是,同一个区域大量循环,在动态页面里(比如jsp等),改造成ajax请求,返回数据的时候,拼接html代码。拼装的时候要小心,一行一般只能凭借一个标签,最后的形式大概是这样的:
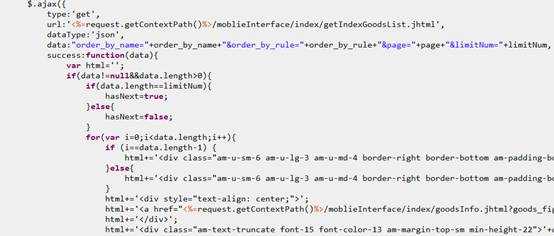
然后循环这个区域。最后显示的是正常的页面了。
这种网页如果使用的爬虫,是爬网页源代码的方式,爬出来的东西肯定是不全的。
那这种网页的静态页面如何从网上拉下来,这时候就要用浏览器的审查元素了,审查元素把组成当前页面的所标签都显示出来了。最后,记得把ajax的javacscript去掉,就把网页还原成改造前的静态页面。是不是觉得很有趣呢,可以试一试。
这也说明了,只要网页显示出来的数据,通过浏览器都是可以获取到的,更不用说还有很多除了浏览器的强大获取工具,比如CometAssistant等,网页上的数据毫无秘密可言。至于能不能在本地再次实时获取服务器最新的数据,这个就不一定了。很多地址要获取数据,要带其他数据,还有域名的限制,得另想其他的方法,这就是跨域请求的范畴了。
标签:
原文地址:http://www.cnblogs.com/xiaochongchong/p/5388079.html