标签:
linux中进程切换是很常见的一个操作,而这个操作是在内核中实现的。
实现的时机有以下三个时机:
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
linux内核中的线程切换主要通过schedule()这个函数实现。
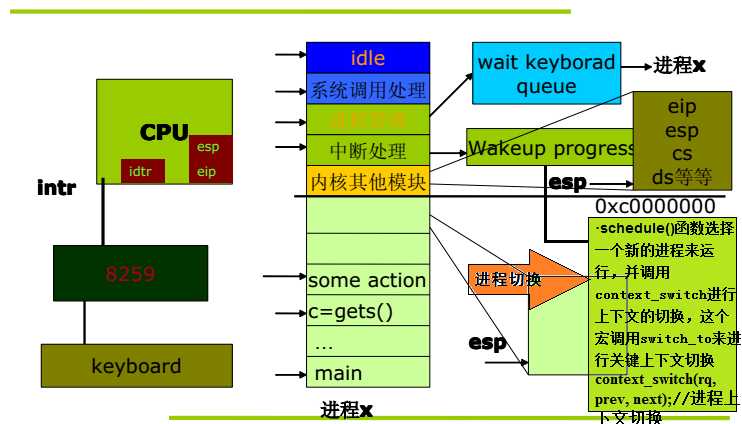
schedule()函数
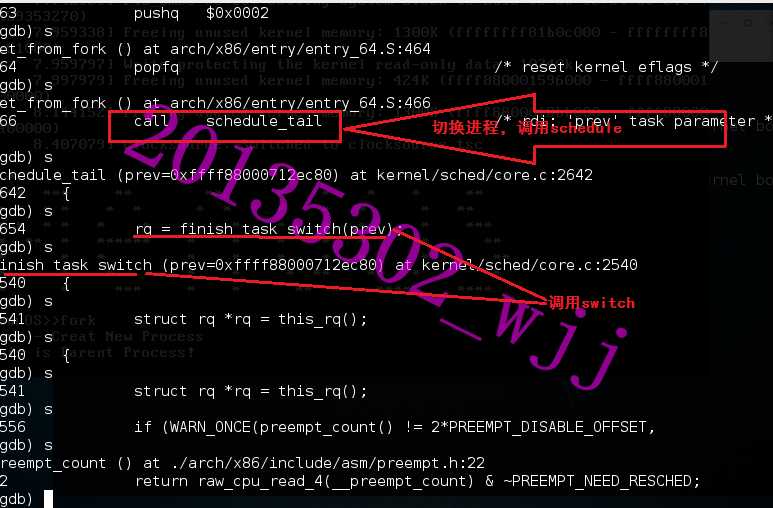
context_switch
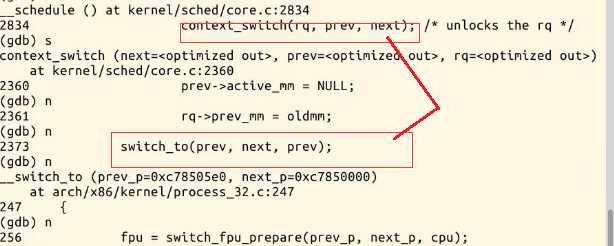
进程切换:
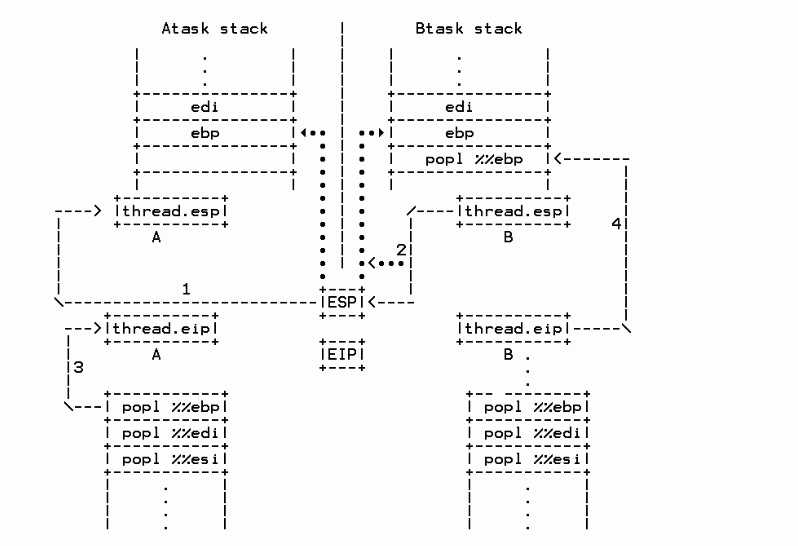
第一步:即movl %%esp,%0也就是将寄存器esp中的值保存在进程A的thread.esp中。
第二步:即movl %3,%%esp也就是将进程B的thread.esp的值赋给寄存器esp。(实际上这个值就是上一次从B中切换走的时候执行的第一步的结果。为了要返回,必须为以后考虑周全。)
第三步:即movl $1f,%1其中1f就是说程序后面标号为1的地方,将标号为1的地方的代码的地址保存到A的thread.eip中。
第四步:即pushl %4,将进程B的thread.eip的值压栈,此时的esp指向已是进程B的堆栈。(实际上此时的thread.eip就是上一次从B中切换走的时候第三步执行的结果,即标号一得位置。所以任何进程恢复运行,首先肯定是执行的标号1的代码。)
pushl %4后面的一句代码是调转jmp __switch_to 而__switch_to是个函数,他执行完成以后会有一个ret的操作,即将栈中的第一个地址作为函数返回的地址,所以就会跳到标号1的地方去执行代码了。
由于__switch_to的代码在schedule()中,而shedule()函数又在其他系统调用函数中,比如sys_exit()中,所以先返回到调用B进程上次切换走时的schedule()中,然后返回到调用schedule()的系统调用函数中,最后系统调用又是在用户空间调用的,所有返回到系统调用的那个地方,接着执行用户空间的代码。这样就彻底的回到了B进程。注意由于此时的返回路径是根据B堆栈中保存的返回地址来返回的,所以肯定会返回到B进程中。
进程的切换时需要保存要切换进程的相关信息,但是这与中断是不同的,因为中断是在一个进程当中,而切换进程需要在不同的进程间切换。
进程切换时需要保存的数据如下:
用户地址空间: 包括程序代码,数据,用户堆栈等
控制信息 :进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)

2.Linux系统的一般执行过程
最一般的情况:正在运行的进程X切换到运行进程Y的过程
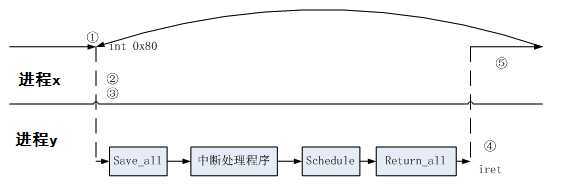
发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
restore_all //恢复现场
iret - pop cs:eip/ss:esp/eflags from kernel stack
继续运行用户态进程Y
几种特殊情况
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
linux内核中实现进程的切换主要通过保存进程相关的信息实现,这里需要注意进程切换中内核级进程的切换和用户态进程切换的不同。内核态可以直接调用schedule函数并不需要陷入中断这个过程。而用户态则需要陷入内核态才能实现进程的切换。从switch_to这个函数当中也可以验证我们进程切换时会保存相关信息的推断。
Linux是一个多进程的操作系统,所以,其他的进程必须等到正在运行的进程空闲CPU后才能运行。当正在运行的进程等待其他的系统资源时,Linux内核将取得CPU的控制权,并将CPU分配给其他正在等待的进程,这就是进程切换。内核中的调度算法决定将CPU分配给哪一个进程。
Linux系统有一个进程控制表(process table),一个进程就是其中的一项。进程控制表中的每一项都是一个task_struct结构,在task_struct结构中存储各种低级和高级的信息,包括从一些硬件设备的寄存器拷贝到进程的工作目录的链接点。进程控制表既是一个数组,又是一个双向链表,同时又是一个树,其物理实现是一个包括多个指针的静态数组。系统启动后,内核通常作为某一个进程的代表。一个指向task_struct的全局指针变量current用来记录正在运行的进程。变量current只能由kernel /sched.c中的进程调度改变。
Linux下函数调用堆栈帧的详细解释 http://blog.chinaunix.net/uid-21237130-id-159883.html
Linux中断一:初看Linux中断 http://blog.csdn.net/xuexingyang/article/details/7350420
Linux用户态和内核态 http://blog.chinaunix.net/uid-1829236-id-3182279.html
深入理解Linux下用户态与内核态切换 http://www.threeway.cc/sitecn/InformationInfo.aspx?pid=2578&tid=1382
Linux操作系统是如何工作的?破解操作系统的奥秘
linux 内核原理——关于进程的简介 http://essayteam.blogbus.com/logs/3870611.html
标签:
原文地址:http://www.cnblogs.com/20135302wei/p/5388498.html