标签:
DOM 文档对象类型,
一:节点层次
DOM把HTM或是XML描绘成一个由多层节点构成的结构(节点树)
1:Node类型
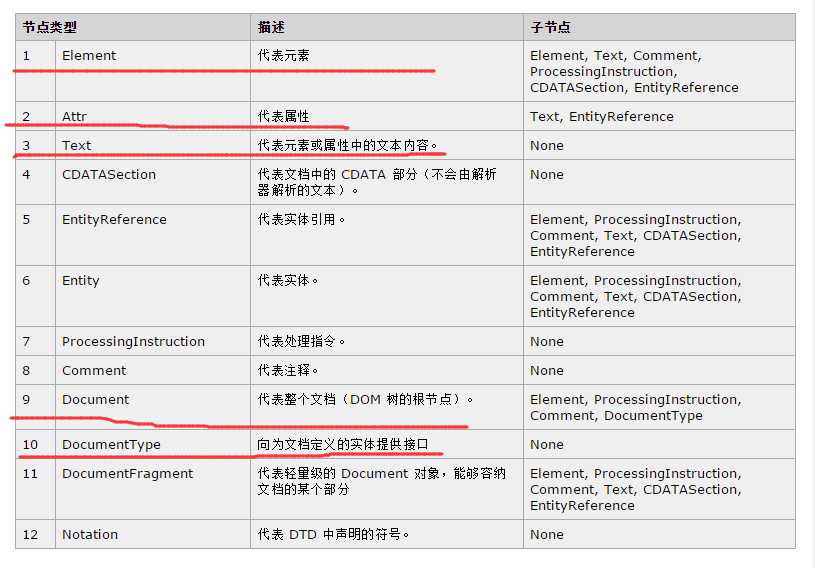
BOM1级定义Node接口,实现DOM所有节点类型,javascript所以的节点都是继承Node类型,所以节点都有着相同的属性和方法,每个节点都有nodeType属性
nodeType 属性返回数字值,下面是12节点类型
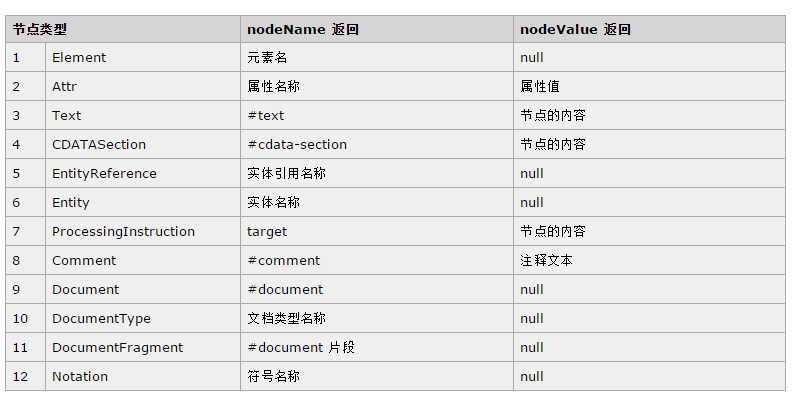
nodeName nodeValue属性 返回值
1.1:节点关系
每个节点都有childNodes属性,
childNodes 值是NodeList对象,这个对象有length属性,
下面例子
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>childNodes</title> </head> <body> <div id="box1"> <p>这是一个p段落</p> <a href=""></a> </div> <script> var box=document.getElementById("box1"); </script> </body> </html>
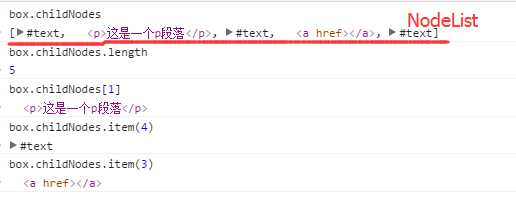 (通过列子知道,通过childNodes获得子节点,值NodeList是一种类数组对象,得到里面的值可以[]获取,也可以用item()方法)
(通过列子知道,通过childNodes获得子节点,值NodeList是一种类数组对象,得到里面的值可以[]获取,也可以用item()方法)
nextSibling、lastChild 获取childNodes 最后一个节点
previousSibling、firstChild 获取childNodes第一个节点
box.firstChild;
box.previousSibling
box.lastChild
box.nextSibling
hasChildNodes() 检查元素有没有子节点,返回true fasle
ownerDocument() 指向整个文档的文档节点,返回#document
1.2:操作节点
appendChild() 向childNodes末尾添加节点,返回新节点
insertBefore() 把节点放在childNodes指定位置,两个参数,第一个参数,节点,第二个参数,参考位置(插入到参考位置之前),如果没第二个参数,同appendChild一样效果
replaceChild() 替换节点,第一个参数插入的节点,第二个参数,替换的节点
removeChild() 移除节点
1.3:其他方法
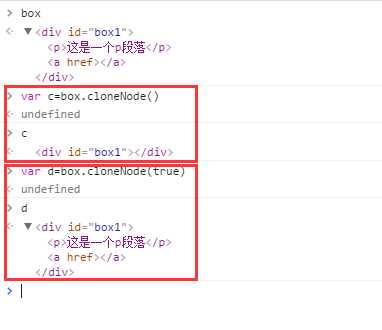
cloneNode() 克隆节点,如果带上参数true,为深度克隆,复制子节点及整个子节点树(IE会连带事件处理也被复制)
2: Document类型
Document nodeType值为9,表示的是整个Html文档,document对象是window对象的一个属性,所以认为是全局对象即可
2.1文档的子节点
documentElement 指向HTML文件的html元素(document.documentElement获得html引用)所有浏览器都支持
body 指向body元素(document.body获得body引用) 所有浏览器都支持
doctype 获得<!Doctype>的引用(document.doctype)浏览器差异比较大,IE8及以下,获得为null,IE9+ firefox可通过document.childNodes[0]获得,但是如果有注释的话,就成第一个,所有尽量不要使用
2.2 文档信息
title 获得当前页面的标题(读:document.title,设置:document.title="xxx";)
URL 获得当前页面的URL(document.URL)
domain 获得当前页面的域名(document.domain)
referrer 属性中则保存着链接到当前页面的那个页面的URL(document.referrer)
直接获取试试,更直观:
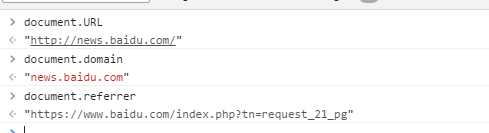 (我从百度首页进入百度新闻页面,所有referrer获取的是百度首页地址)
(我从百度首页进入百度新闻页面,所有referrer获取的是百度首页地址)
2.3查找元素
getElementByID() 传入想获得元素的ID返回该元素(严格模式,区分大小写)IE8及以下不区分大小写,IE7而且也跟name匹配,谁第一个出现就匹配谁,所有应避免id名与name相同
getElementsByTagName() 要取得得标签,返回零个或多个的NodeList对象
namedItem() 通过元素name特性取得的集合中匹配,下面代码体现一下
<div id="box1"> <p name="xx">这是一个p段落</p> <a href=""></a> <p name="yy">这是一个yy</p> </div> <script> var p=document.getElementsByTagName("p") p.namedItem(xx); // <p name="xx">这是一个p段落</p> </script>
getElementsByName() 返回带有指定name的元素
2.4文档写入 将输出流写入文档
wirte() 原样写入
writeln() 会最后加换行符\n
open() close() 打开 关闭网页的输出流,如果有write() writeln则不需要这两个方法
3:Element类型
Element 的nodeType 值为1
tagName 返回标签名同nodeName一样(如DIV,标签名都是大写)
3.1 HTML元素
html元素:<div id="myDiv" class="bd" title="Body text" lang="en" dir="ltr"></div>
可以直接获取和修改 var div=document.getElementById("myDiv");
div.title //"Body text"
div.title="new Body text"
3.2 各种操作属性 (特性名称不区分大小写,自定义添加的属性,用data-前缀)
getAttribute() 取得属性(div.getAttribute("class");一般用于自定义属性)
setAttribute(属性名,值) 设置属性,如果有替换,没有添加
div.mycolor = "red"; alert(div.getAttribute("mycolor")); //null(IE 除外)像这样添加属性,不会自动添加到元素
removeAttribute() 彻底删除元素属性(完全从元素中删除)
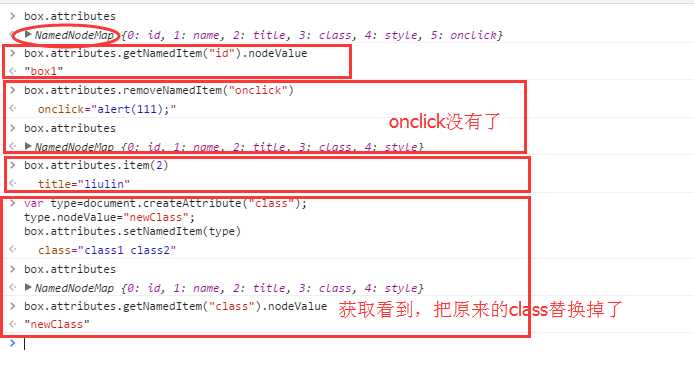
attributes属性 值NameNodeMap是一个动态集合,同NodeList类似
NameNodeMap的方法:
getNamedItem(name) 返回NodeName属性的name节点
removeNamedItem(name)从列表中删除NodeName属性name节点
setNamedItem(node) 向列表中添加节点,以节点的NodeName为索引
iten(pos) 返回位于数字位置的节点
操作理解一下
标签:
原文地址:http://www.cnblogs.com/liulin0524/p/5386248.html