标签:
1.RBM简介
受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数,其网络结构如下:
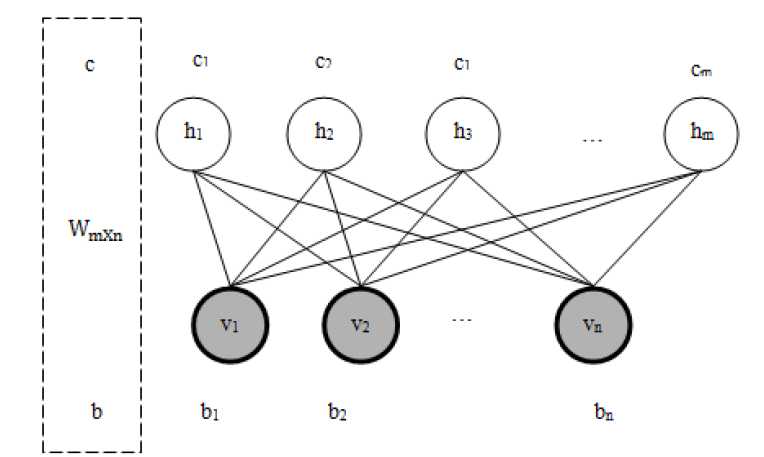
以上的RBM的贝叶斯网络图,该网络可网络结构有 n个可视节点和m个隐藏节点 ,其中每个可视节点只与m个隐藏节点相关,与其他可视节点独立,对于隐藏节点同理,RBM中的参数有隐层与可见层的权重参数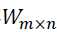 ,还有上图没给出的偏置项,
,还有上图没给出的偏置项,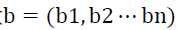 为可见层的偏置,
为可见层的偏置,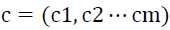 为隐藏层的偏置,以上便是RBM中的所有参数。
为隐藏层的偏置,以上便是RBM中的所有参数。
RBM的用途主要有两种:
1)类似栈式自编码器,对数据编码,得到数据的高阶表示,然后使用监督学习的方法进行分类或回归
2)预训练深度神经网络,因为网络层数加深时,为了避免局部最优解,这种用途也类似于栈式自编码器
而且RBM中还可以求得输入输出的联合概率p(v,h)或者条件概率分布p (h|v)。
2.能量模型
先看一个引例,把一个表面粗糙又不太圆的小球,放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗的哪个地方。一般来说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附近(这个碗是比较浅的一个碗);能量模型把小球停在哪个地方定义为一种状态,每种状态都对应着一个能量E ,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一样)可以通过这种状态下小球具有的能量来定义(换个说法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E ,而发生“小球停在碗口附近”这种状态的概率p ,可以用E 来表示,表示成p=f(E),其中f 是能量函数),其实还有一个简单的理解,球在碗底的能量一般小于在碗边缘的,比如重力势能这,显然碗底的状态稳定些,并且概率大些, 这便是对能量模型的直观理解。
RBM是一种随机网络,描述一个随机网络可从以下两点入手:
1)概率分布函数。各个节点的状态取值是概率的随机的,这里用三种概率分布来描述整个RBM网络,联合概率密度,条件概率密度和边缘概率密度。
2)能量函数。随机神经网络的思想来源于统计力学,能量函数是描述整个系统状态的一种测度,系统越有序或者概率分布越集中(比如小球在碗底的情况),系统的能量越小,反之,系统越无序并且概率分布发散(比如平均分布),则系统的能量越大,能量函数的最小值,对应着整个系统最稳定的状态。
RBM中能量模型起啥作用呢?
1)参数估计问题中,当分布未知时,统计力学的一项研究表明,其概率分布可以表示为基于能量的模型,即对于未知的分布,可以将这个分布改写成能量函数的形式。
2)能量函数可以为RBM引入目标函数与目标解,即引入能量函数后,使得学习一组数据的分布变得容易了,能否把求解最优解嵌入能量模型中至关重要,决定这具体问题求解的好坏。
3)能量模型要捕获变量之间的相关性,变量的相关程度决定了能量的高低,把变量的相关关系用图表示出来,并引入概率测度方式就构成了概率图(为什么是概率图?前面一句说了,RBM 是一个图,以概率为测度,所以是概率图)模型的能量模型。
RBM的能量函数如下:
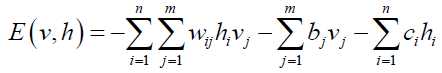
这个能量 函数的意思就是,每可视节点和隐藏之间连接结构都有通俗来说就是可视节点的 每一组取值和隐藏都有个能量,通俗来说就是可视节点的每一组取值和隐藏节点的每一组取值都有一个能量,如果可视节点的一组取值(即一个训练样本)为(1,0,1,0,1,1,0),隐藏节点的一组取值(经过RBM编码后的值)为(1,0,1),分别带入到上面的公式,对于训练后的网络已经得到其参数,即 W,b,c 均已知,这样根据能量函数便可求得RBM整个连接结构的能量。但实际情况是 W,b,c 均为未知的,所以要求得这些参数。
现在可以进一步想一下要搞能量函数?前面指出未知分布不好求解但是可以通过能量函数来表示,那么能量函数的概率模型很大程度上可以得到未知分布的概率模型,这样大致就知道了数据的分布,RBM网络是hidden和visible整个框架的能量函数,可以定义这个能量函数出现的概率,显然该能量函数与 hidden 层和 visible 的每个节点均有关,定义联合概率密度:
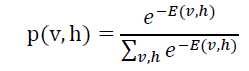
即现在p(v = v‘ , h = h‘)的概率可以由以上能量函数决定, v‘ 为一组观测值和 h‘ 为一组隐藏节点的取值,其发生的概率p(v = v‘ , h = h‘)是由以上能量函数定义的概率密度表示的。RBM 的概率密度是建立在热力学的解释基础上的,当系统及其周围环境处于热平衡状态时,状态 i 发生的概率如下:
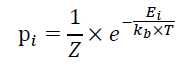
Ei表示系统在状态i时的能量,T为开尔文绝对温度,KB为Boltzmann常数,Z为归一化系数,上述方程中 i 替换为(v ,h),,另KB =T = 1,即得到RBM的概率密度公式。其实这个分布是一个特殊的Gibbs分布,且这个分布是有一组参数的即原来提到的 W , c, b 。
有了这个联合概率,就可以得到一些其他概率:
1)边缘概率
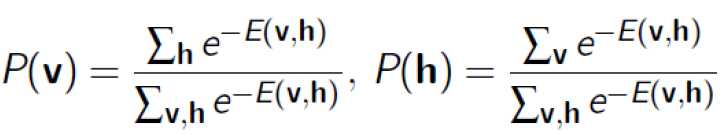
2)条件概率
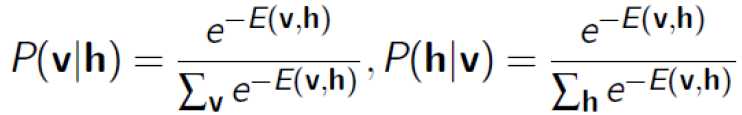
3.极大似然
1)相对熵解释
假设训练数据 {x1 x2 ...xn } 来自于随机变量 X(X 来自样本空间 Ω),q(X)表示训练样本的概率,设 q 为 RBM 中课件变量 v 的边缘分布,即
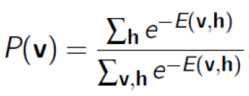
则输入样本 {x1 x2 ...xn } 的分布 q 与 RBM 网络表示的边缘分布 p 的KL距离为:
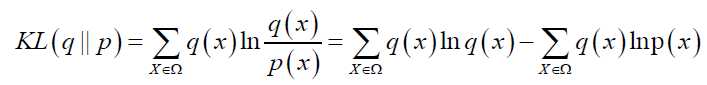
![]() 值的大小代表了 q 与 p 分布的距离,为了使 q 与 p 的分布更接近,
值的大小代表了 q 与 p 分布的距离,为了使 q 与 p 的分布更接近,![]() 应尽可能小,即
应尽可能小,即![]() 应该尽可能大,给定样本后 q(x) 为定值,所以只需要求
应该尽可能大,给定样本后 q(x) 为定值,所以只需要求![]() 得极大值即可。
得极大值即可。
2)自由能量解释
参考:
http://www.cnblogs.com/tornadomeet/archive/2013/03/27/2984725.html
(六)6.14 Neurons Networks Restricted Boltzmann Machines
标签:
原文地址:http://www.cnblogs.com/ooon/p/5392272.html