标签:
目标网站:http://www.netbian.com/
目的:实现对壁纸各分类的第一页壁纸的获取
一:分析网站,编写代码:
(ps:源代码在文章的最后)
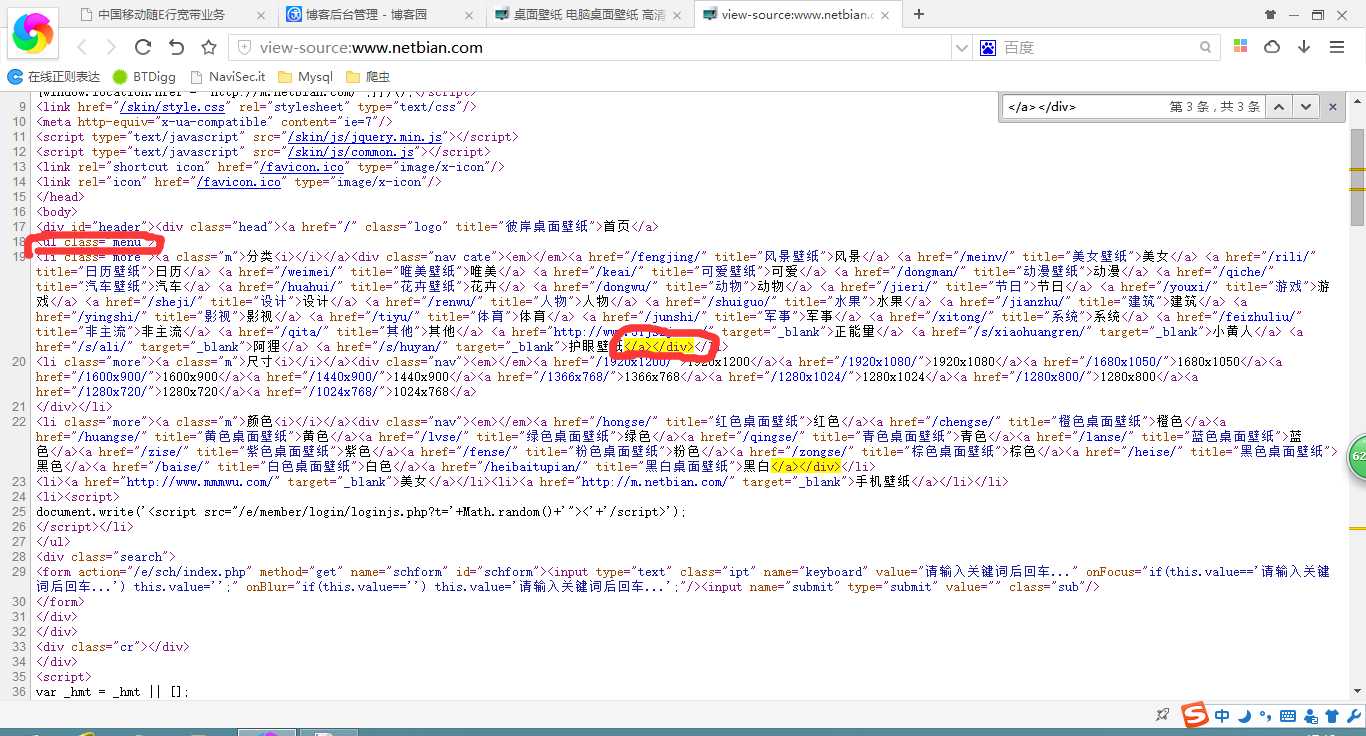
1.获取网站目录部分的一大段代码,下一步再进行仔细匹配网址与标题.
1 #coding=gbk 2 #目标:下载各目录的壁纸(大图) 3 __author__ = ‘CQC‘ 4 import urllib2 5 import urllib 6 import re 7 import os 8 9 #创建壁纸下载文件夹 10 path = ‘d:\\彼岸壁纸‘ 11 if not os.path.isdir(path): 12 os.makedirs(path) 13 #目录 14 big_title = [] 15 16 #首页打开 17 url = ‘http://www.netbian.com/‘ 18 headers = {‘User-agent‘ : ‘Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0‘} 19 request = urllib2.Request(url,headers = headers) 20 response = urllib2.urlopen(request) 21 22 #首页目录源代码获取 23 pat_menu = re.compile(‘<ul class="menu">(.*?)</a></div>‘,re.S) 24 code_menu = re.search(pat_menu,response.read())
如图:
2.进行分类的标题与链接的匹配。
1 #目录标题 2 pat_menu_title = re.compile(‘<a href=".*?" title="(.*?)">‘,re.S) 3 menu_title = re.findall(pat_menu_title,code_menu.group(1)) 4 for a_item in menu_title: 5 big_title.append(a_item) 6 print a_item 7 8 #目录链接 9 pat_menu_link = re.compile(‘<a href="(.*?)" title=".*?">‘,re.S) 10 menu_link = re.findall(pat_menu_link,code_menu.group(1))
如下图所示:

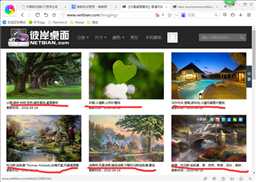
3.从爬取到的目录进入,获得该目录下所有壁纸的标题与链接.
1 #进入目录 2 j = 0 3 for b_item in menu_link: 4 url_menu = ‘http://www.netbian.com/‘ + b_item 5 request_son = urllib2.Request(url_menu,headers = headers) 6 response_son = urllib2.urlopen(request_son) 7 #获得每个目录的图片标题,链接 8 9 #获得子目录标题 10 title_son = [] 11 pat_title_son = re.compile(‘<img src=".*?" data-src=".*?" alt="(.*?)"/>‘,re.S) 12 res_title = re.findall(pat_title_son,response_son.read()) 13 for c_item in res_title: 14 title_son.append(c_item) 15 16 #筛选出子目录代码 17 pat_code_son = re.compile(‘<ul>(.*?)</ul>‘,re.S) 18 middle_pattern = urllib2.Request(url_menu,headers = headers) 19 middle_response = urllib2.urlopen(middle_pattern) 20 res_code_son = re.search(pat_code_son,middle_response.read()) 21 22 #获得子目录链接,合成大图网页链接 23 pat_link_son = re.compile(‘<li><a href="(.*?)" target="_blank"><img‘,re.S) 24 res_link = re.findall(pat_link_son,res_code_son.group(1))
如下图所示:
4.根据上一步爬取到的链接,合成真正的1080p壁纸链接.
因为我们从上图标题点进去后是这样:
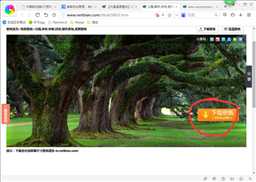
还需要点击下载按钮才能打开1080p壁纸的链接。为了方便,我们直接合成1080p壁纸的链接.
例如: http://www.netbian.com/desk/9805.htm
对应的1080p网址:http://www.netbian.com/desk/9805-1920x1080.htm
代码:
1 i = 0 2 #显示进度 3 print big_title[j] 4 for d_item in res_link: 5 #获得大图下载链接 6 if d_item == ‘http://www.mmmwu.com/‘: 7 pass 8 else: 9 new_link = ‘http://www.netbian.com/‘ + d_item[:-4] + ‘-1920x1080.htm‘ 10 print new_link
(ps:由于‘美女’分类中的第一个标题链接到了其他网站,为了简单一点,所以我直接跳过了)
5.进入1080p壁纸链接,下载壁纸.
1 request_real = urllib2.Request(new_link,headers = headers) 2 response_real = urllib2.urlopen(request_real) 3 pat_real = re.compile(‘<img src="(.*?)" alt=".*?"/></td></tr>‘) 4 5 link_real = re.search(pat_real,response_real.read()) 6 #跳过vip壁纸 7 if link_real: 8 fina_link = link_real.group(1) 9 #创建下载目录 10 path_final = ‘d:\\彼岸壁纸\\‘ + big_title[j] + ‘\\‘ 11 if not os.path.isdir(path_final): 12 os.makedirs(path_final) 13 path_pic = path_final + title_son[i] + ‘.jpg‘ 14 f = open(path_pic,‘wb‘) 15 data = urllib.urlopen(fina_link) 16 f.write(data.read()) 17 f.close() 18 if not data: 19 print "Download Failed." 20 i += 1 21 print ‘One menu download OK.‘ 22 j += 1
6.下载完成.
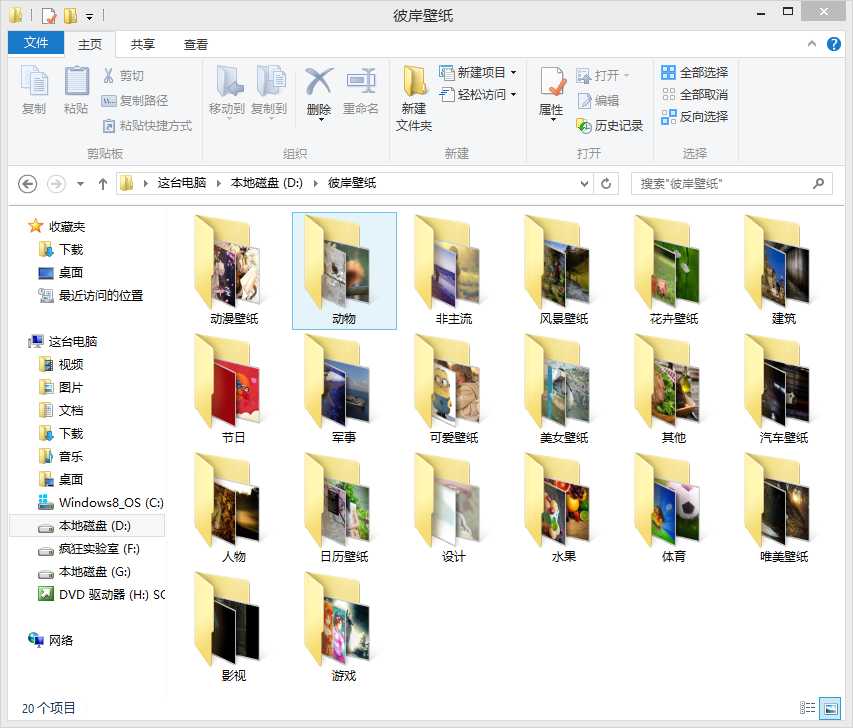
二、所有的源代码。
1 #coding=gbk 2 #目标:下载各目录的壁纸(大图) 3 __author__ = ‘CQC‘ 4 import urllib2 5 import urllib 6 import re 7 import os 8 9 #创建壁纸下载文件夹 10 path = ‘d:\\彼岸壁纸‘ 11 if not os.path.isdir(path): 12 os.makedirs(path) 13 #目录 14 big_title = [] 15 16 #首页打开 17 url = ‘http://www.netbian.com/‘ 18 headers = {‘User-agent‘ : ‘Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0‘} 19 request = urllib2.Request(url,headers = headers) 20 response = urllib2.urlopen(request) 21 22 #首页目录源代码获取 23 pat_menu = re.compile(‘<ul class="menu">(.*?)</a></div>‘,re.S) 24 code_menu = re.search(pat_menu,response.read()) 25 26 #目录标题 27 pat_menu_title = re.compile(‘<a href=".*?" title="(.*?)">‘,re.S) 28 menu_title = re.findall(pat_menu_title,code_menu.group(1)) 29 for a_item in menu_title: 30 big_title.append(a_item) 31 print a_item 32 33 #目录链接 34 pat_menu_link = re.compile(‘<a href="(.*?)" title=".*?">‘,re.S) 35 menu_link = re.findall(pat_menu_link,code_menu.group(1)) 36 37 #进入目录 38 j = 0 39 for b_item in menu_link: 40 url_menu = ‘http://www.netbian.com/‘ + b_item 41 request_son = urllib2.Request(url_menu,headers = headers) 42 response_son = urllib2.urlopen(request_son) 43 #获得每个目录的图片标题,链接 44 45 #获得子目录标题 46 title_son = [] 47 pat_title_son = re.compile(‘<img src=".*?" data-src=".*?" alt="(.*?)"/>‘,re.S) 48 res_title = re.findall(pat_title_son,response_son.read()) 49 for c_item in res_title: 50 title_son.append(c_item) 51 52 #筛选出子目录代码 53 pat_code_son = re.compile(‘<ul>(.*?)</ul>‘,re.S) 54 middle_pattern = urllib2.Request(url_menu,headers = headers) 55 middle_response = urllib2.urlopen(middle_pattern) 56 res_code_son = re.search(pat_code_son,middle_response.read()) 57 58 #获得子目录链接,合成大图网页链接 59 pat_link_son = re.compile(‘<li><a href="(.*?)" target="_blank"><img‘,re.S) 60 res_link = re.findall(pat_link_son,res_code_son.group(1)) 61 i = 0 62 #显示进度 63 print big_title[j] 64 for d_item in res_link: 65 #获得大图下载链接 66 if d_item == ‘http://www.mmmwu.com/‘: 67 pass 68 else: 69 new_link = ‘http://www.netbian.com/‘ + d_item[:-4] + ‘-1920x1080.htm‘ 70 print new_link 71 request_real = urllib2.Request(new_link,headers = headers) 72 response_real = urllib2.urlopen(request_real) 73 pat_real = re.compile(‘<img src="(.*?)" alt=".*?"/></td></tr>‘) 74 75 link_real = re.search(pat_real,response_real.read()) 76 #跳过vip壁纸 77 if link_real: 78 fina_link = link_real.group(1) 79 #创建下载目录 80 path_final = ‘d:\\彼岸壁纸\\‘ + big_title[j] + ‘\\‘ 81 if not os.path.isdir(path_final): 82 os.makedirs(path_final) 83 path_pic = path_final + title_son[i] + ‘.jpg‘ 84 f = open(path_pic,‘wb‘) 85 data = urllib.urlopen(fina_link) 86 f.write(data.read()) 87 f.close() 88 if not data: 89 print "Download Failed." 90 i += 1 91 print ‘One menu download OK.‘ 92 j += 1
初学爬虫,欢迎指导~
标签:
原文地址:http://www.cnblogs.com/try2333/p/5396334.html