标签:
链接是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或拷贝)到存储器并执行。
链接可以执行于编译时,也就是在源代码被翻译成机器代码时;也可以执行于加载时,也就是在程序被加载器加载到存储器并执行时;甚至执行于运行时,由应用程序来执行。
在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由叫链接器的自动执行的。
大多数编译系统提供编译驱动程序,它代表用户在需要时调用语言预处理器、编译器、汇编器和链接器。
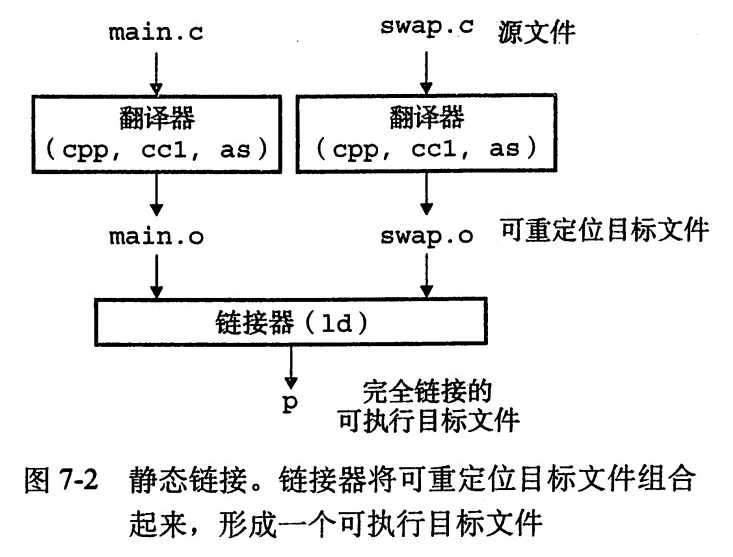
例子: 函数main()调用swap交换外部全局数据buf中的两个元素。这个例子贯穿全文,分析链接是如何工作的。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/* $begin main *//* main.c */void swap();int buf[2] = {1, 2};int main(){ swap(); return 0;}/* $end main */ |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
/* $begin swap *//* swap.c */extern int buf[];int *bufp0 = &buf[0];int *bufp1;void swap(){ int temp; bufp1 = &buf[1]; temp = *bufp0; *bufp0 = *bufp1; *bufp1 = temp;}/* $end swap */ |
像Unix ld程序这样的静态链接器以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的可以加载和运行的可执行目标文件作为输出。输入的可重定位目标文件由各种不同的代码和数据节组成。指令在一个节中,初始化的全局变量在另一个节中,而未初始化的变量又在另外一个节中。
为了构造可执行文件,链接器必须完成两个主要任务:
链接器的一些基本事实:目标文件纯粹是字节块的集合。这些块中,有些包含程序代码,有些则包含程序数据,而其他的则包含指导链接器和加载器的数据结构。链接器将这些块连接起来,确定被连接块的运行时位置,并且修改代码和数据块中的各种位置。链接器和汇编器已经完成了大部分工作。
目标文件纯粹是字节快的集合。这些块中,有些包含程序代码,有些则包含程序数据,而其他的则包括指导链接器和加载器的数据结构。链接器将这些块链接起来,确定被连接块的运行时位置,并且修改代码和数据块中的各种位置。链接器对目标机器了解甚少。产生目标文件的编译器和汇编器已经完成了大部分工作。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。从技术上来说,一个目标模块就是一个字节序列,而一个目标文件就是一个存放在磁盘文件中的目标模块。
编译器和汇编器生成可重定义目标文件(包括共享目标文件)。链接器生成可执行目标文件。
各个系统之间,目标文件格式都不相同。
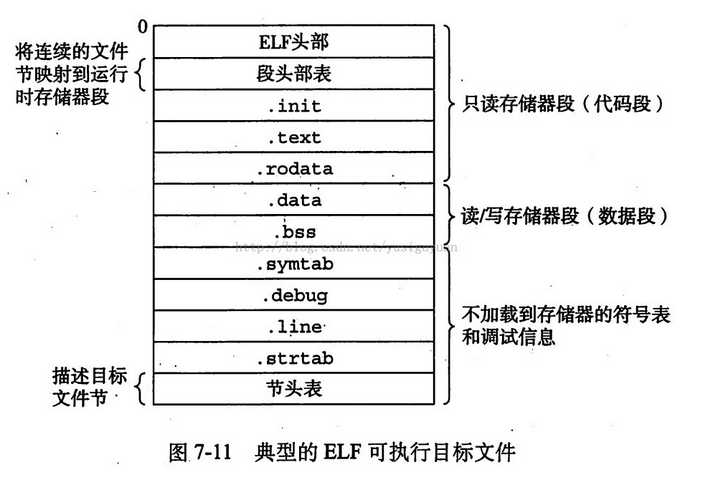
一个典型的ELF可重定位目标文件的格式P451。ELF头(ELF header)以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含帮助链接器语法分析和解释目标文件的信息。其中包括ELF头的大小、目标文件的类型(如可重定位、可执行或是共享的)、机器类型(如IA32)、节头部表的文件偏移,以及节头部表中的条目大小和数量。不同的节的位置和大小是由节头部表描述的,其中目标文件中每个节都有一个固定大小的条目。
夹在ELF头和节头部表之间的都是借。一个典型的ELF可重定位目标文件包含下面几个节:
在链接器的上下文中,有三种不同的符号:
在编译是,编译器向汇编器输出每个全局符号,或者是强或者是弱,而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量时强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Unix链接器使用下面的规则来处理多重定义的符号:
在Unix系统中,静态库以一种称为存档的特殊文件格式村凡在磁盘中。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。存档文件名由后缀.a标识。
在符号解析的阶段,链接器从左到右按照它们在编译器驱动程序命令行上出现的相同顺序来扫描可重定位目标文件和存档文件。在这次扫描中,链接器维持一个可重定位目标文件的集合E(这个集合中的文件会被合并起来形成可执行文件),一个未解析的符号(即引用了但是尚未定义的符号)集合U,以及一个在前面输入文件中已定义的符号集合D。初始时,E、U和D都是空的。
1.对于命令行上的每个输入文件f,链接器会判断f是一个目标文件还是一个存档文件。如果f是一个目标文件,那么链接器吧f添加到E, 修改U和D来反映f中的符号定义和引用,并继续下一个输入文件。
2.如果f是一个存档文件,那么链接器就尝试匹配U中未解析的符号和由存档文件成员定义的符号。如果某个存档文件成员m,定义了一个符号来解析U中的一个引用,那么就将m加到E中,并且链接器修改U和D来反映m中的符号定义和引用。对存档文件中所有的成员目标文件都反复进行这个过程,直到U和D都不再发生变化。在此时,任何不包含在E中的目标文件都简单地被丢弃,而链接器将继续处理下一个输入文件。
3.如果当链接器完成对命令行上输入文件的扫描后,U是非空的,那么链接器就好输出一个错误并终止。否则,它会合并和重定位E中的目标文件,从而构建输出的可执行文件。
这种算法会导致一些令人困扰的链接时错误,因为命令行上的库和目标文件的顺序非常重要。在命令行中,如果定义一个符号的库出现在引用这个符号的目标文件之前,那么引用就不能被解析,链接会失败。关于库的一般准则是将它们放在命令行的 结尾。
另一方面,如果库不是相互独立的,那么它们必须排序,使得对于每个被存档文件的成员外部引用的符号s,在命令行中至少有一个s的定义实在对s的引用之后的。
如果需要满足依赖需求,可以在命令行上重复库。
一旦链接器完成了符号解析这一步,它就是把代码中的每个符号引用和确定的一个符号定义(即它的一个输入目标模块中的一个符号表条目)联系起来。在此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。
重定位有两步组成:
1.重定位节和符号定义。在这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。然后,链接器将运行时存储器地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号。当这一步完成时,程序中的每个指令和全局变量都有唯一的运行时存储器地址了。
2.重定位节中的符号引用。在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址。为了执行这一步,链接器依赖于称为重定位条目的可重定位目标模块中的数据结构。
当汇编器生成一个目标模块时,它并不知道数据和代码最终存放在存储器中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置位置的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码的重定位条目放在.rel.text中。 已初始化的数据的重定位条目放在.rel.data中。
ELF定义了11种不同的重定位类型。我们只关心其中两种最基本的重定位类型:
可执行目标文件的格式类似于可重定位目标文件的格式。ELF头部描述文件的总体格式。它还包括程序的入口点,也就是当程序运行时要执行的第一条指令的地址。.text 、.rodata和.data 节和可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时存储器地址以外。.init节定义了一个小函数,叫做_init,程序的初始化代码会调用它。因为可执行文件是完全链接的(已被重定位了),所以它不再需要.rel节。
ELF可执行文件被设计得很容易加载到存储器,可执行文件的连续的片被映射到连续的存储器段。段头部表描述了这种映射关系。
要运行可执行目标文件p,可以在Unix外壳的命令行中输入它的名字:
|
1
|
unix> ./p |
因为p不是一个内置的外壳命令,所以外壳会认为p是一个可执行目标文件,通过调用某个驻留在存储器中的称为加载器(loader)的操作系统代码来运行它。任何Unix程序都可以通过调用execve函数来调用加载器。加载器将可执行目标文件中的代码和数据从磁盘拷贝到存储器中,然后通过跳转到程序的第一条指令或入口点来运行该程序。这个将程序拷贝到存储器并运行的过程叫做加载。
每个Unix程序都有一个运行时存储器映像。例如:在32位Linux系统中,代码段总是从地址(0x8048000)处开始。数据段是在接下来的下一个4KB对齐的地址处。运行时堆在读/写段之后接下来的第一个4KB对齐的地址处,并童工调用malloc库往上增长。还有一个段是为共享库保留的。用户栈总是从最大的合法用户地址开始,向下增长的(向低存储器地方向增长)。从栈的上部开始的段是为操作系统驻留存储器的部分(也就是内核)的代码和数据保留的。
在可执行文件中段头部表的指导下,加载器将可执行文件的相关内容拷贝到代码和数据段。接下来,加载器跳转到程序的入口点,也就是符号_start的地址。在_start地址处的启动代码是在目标文件ctrl.o中定义的,对所有的C程序都是一样的。在从.text和.init节中调用了初始化例程后,启动代码调用atexti例程,这个程序附加了一系列在应用程序正常中止时应该调用的程序。exit函数运行atexit注册的函数,然后通过调用_exit将控制返回给操作系统。接着,启动代码调用应用程序的main程序,它会开始执行我们的C代码。在应用程序返回之后,启动代码调用_exit程序,它将控制返回给操作系统。
加载的工作流程:
UNIX系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当外壳运行一个程序时,父外壳进程生成一个子进程,它是父进程的一个复制品。子进程通过execve系统调用启动加载器。加载器删除子进程现有的虚拟存储器段,并创建一组新的代码、数据、堆和栈段、新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页大小的片,新的代码和数据段被初始化为可执行文件的内容。最后,加载器跳转到_start地址,它最终会调用应用程序的main函数。除了一些头部信息,在加载过程中没有任何从磁盘到存储器的数据拷贝。直到CPU应用一个被映射的虚拟页才会进行拷贝,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到存储器。
共享库是致力与解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行时,可以加载到任意的存储器地址,并加一个在存储器中的程序链接起来。这个过程称为动态链接,是由一个叫做动态链接器的程序来执行的。共享库也称为共享目标,在Unix系统中通常用.so后缀来表示。
动态链接在现实中的例子:
PIC数据引用
PIC函数调用
标签:
原文地址:http://www.cnblogs.com/20135336wwz/p/5397854.html