标签:
提到HashMap,使用Java语言的人来说,是再熟悉不过了。今天就简单聊聊我们认识的HashMap;
首先我们看一下Java中的HashMap类
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { private static final long serialVersionUID = 362498820763181265L; ....... }
我们可以看出HashMap是一组泛型的容器,继承AbstractMap类,实现了Map接口,Cloneable接口,Serializable接口;其中AbstractMap类也是一个抽象类,部分实现Map接口;
public abstract class AbstractMap<K,V> implements Map<K,V> { .............. }
HashMap的实现原理是使用了Hash散列存储的原理:
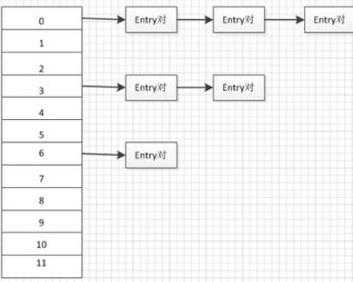
这图片是从baidu上搜到的,就拿来用了。
原理如下:
1. 在New HashMap时或者put操作时,会预先申请一个大小为2n的数组,数组中存放的都是Node<K,V>[] ; 数组的元素都是存放的链表的一个头结点的引用;
2. 当put一个Node<K,V>时,会首先计算hashCode(k) & (len-1)来计算在数组中的位置a[i];
3. 如果该位置a[i]还未被填充,则会进行直接将Node<K,V>存放在a[i]处;
4. 如果a[i]已经有值,那么就会以链表的形式在链表的末端位置加上Node<K,V>;
5. 当链表的长度超出TREEIFY_THRESHOLD - 1时,将其改变为treeMap,减少查找的时间复杂度;
通过上述的阐述,很容易明白HashMap的优势了:
1. 能够快速定位到结点位置;
2. 能动态的添加结点;
分析JDK1.8.0_25的源码时,发现New HashMap其实没有立即new 操作,而是将new操作放在了put时:
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); } /** * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and the default load factor (0.75). * * @param initialCapacity the initial capacity. * @throws IllegalArgumentException if the initial capacity is negative. */ public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } /** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
可以发现构造函数中并没有new Node结点的操作;真正的扩展HashMap容量的操作是在resize方法中;
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
所以我们可以理解他的高效的原因了。
最后再来说一下HashMap和HashTable之间的事了;
1. 两者的继承不同:
public class HashMap<K,V> extends AbstractMap<K,V> public class Hashtable<K,V> extends Dictionary<K,V>
2. HashTable中使用了synchronized来实现了线程安全;而HashMap则需要使用者自己来控制线程安全;
3. HashMap的K,V都可以为null, 若V为null, 表示还没有存放该键值;
4. 哈希值的计算方式不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。HashMap的hash计算方式为:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
而在HashTable中,则只是使用了int hash = key.hashCode()来计算;
5. Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
参考博文:http://www.cnblogs.com/devinzhang/archive/2012/01/13/2321481.html
能力有限,如有错误,烦请指出,请不吝赐教。
标签:
原文地址:http://www.cnblogs.com/yw-technology/p/5397956.html