标签:
一:背景
http://www.cnblogs.com/aijianiula/p/5397857.html
上节中,总结了频繁项集挖掘的最基本算法:Apriori算法。这篇文章写下它的改进算法FGrowth算法,记得这个算法是香港一位教师提出来的,其思想非常值得借鉴和思考。
二:FGrowth
FPGrowth算法采用频繁增长模式,通过建立增长树来产生优化Apriori算法,减少数据库的扫描次数和在必要时候剪枝来减少枚举程度,同样以上面的例子来说明FPGrowth算法优化过程。这里引用《数据挖掘概念和技术》这本书中的图来进行说明。
这个算法主要分为两个步骤:
1.FP树的构造,2.FP树中频繁项集的挖掘
1.FP树的构造
FP树的构造过程其实也非常简单,首先建立一个只有null节点的树。然后在数据库中拿出第一个事务,按照事务中的1项集支持度进行排序,从大到小。
|
交易ID |
商品ID列表 |
交易ID |
商品ID列表 |
|
|
T100 |
I1,I2,I5 |
T600 |
I2,I3 |
|
|
T200 |
I2,I4 |
T700 |
I1,I3 |
|
|
T300 |
I2,I3 |
T800 |
I1,I2,I3,I5 |
|
|
T400 |
I1,I2,I4 |
T900 |
I1,I2,I3 |
|
|
T500 |
I1,I3 |
如上图的事务表中,取出第一条记录,T100事务{I1,I2,I3},在上节中我们统计过1项集的支持度了,如下图:
|
项集 |
支持度计数 |
|
{I1} |
6 |
|
{I2} |
7 |
|
{I3} |
6 |
|
{I4} |
2 |
|
{I5} |
2 |
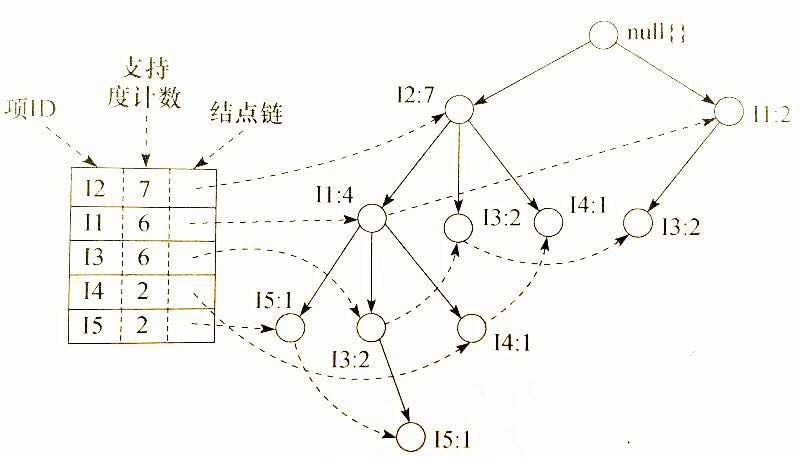
所以它的T100事务的支持度排序之后为:I2,I1,I5,然后开始创建分支<I2,1>,<I1,1>,<I5,1>。I2作为分支连接到根节点null中,I1链接到I2,I5链接到I1.
第2个事务T200按1项集排序分别为I2,I4,为T200创建分支,I2链接到根,I4链接到I2。因为分支中与T100共享了前缀I2,所以I2的计数加1。因此创建一个新节点<I4,1>链接到<I2,2>节点上。
第3个事务T300 {I2,I3}排序后为I2,I3。为此事务创建分支,I2链接到根节点,I3链接到I2,I2的计数加1,因此<I3,1>链接到<I2,3>
第4个事务T400 {I1,I2,I4}排序后为I2,I1,I4。为此事物创建分支,I2链接到根节点,I1链接到I2,I4链接到I1,I2的计数加1,I1的计数加1,创建节点<I4,1>链接到<I1,2>
......
至于FP树的左边创建了一个数组,是为了方便树的遍历,创建一个项头表,每项通过一个节点链指向它在树中的位置。
2.FP树中频繁项集的挖掘
标签:
原文地址:http://www.cnblogs.com/aijianiula/p/5398179.html