标签:
攥写人:李鹏举 学号:20132201
( *原创作品转载请注明出处*)
( 学习课程:《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000)
一、实验要求:
理解Linux系统中进程调度的时机,可以在内核代码中搜索schedule()函数,看都是哪里调用了schedule(),判断我们课程内容中的总结是否准确;
使用gdb跟踪分析一个schedule()函数 ,验证您对Linux系统进程调度与进程切换过程的理解;推荐在实验楼Linux虚拟机环境下完成实验。
特别关注并仔细分析switch_to中的汇编代码,理解进程上下文的切换机制,以及与中断上下文切换的关系;
二、实验过程:
1、使用gdb跟踪分析schedule()函数,首先开启分布执行内核的指令。
输入指令:qemu –kernel linux-3.18.6/arch/x86/boot/bzImage –initrd rootfs.img –S –s :
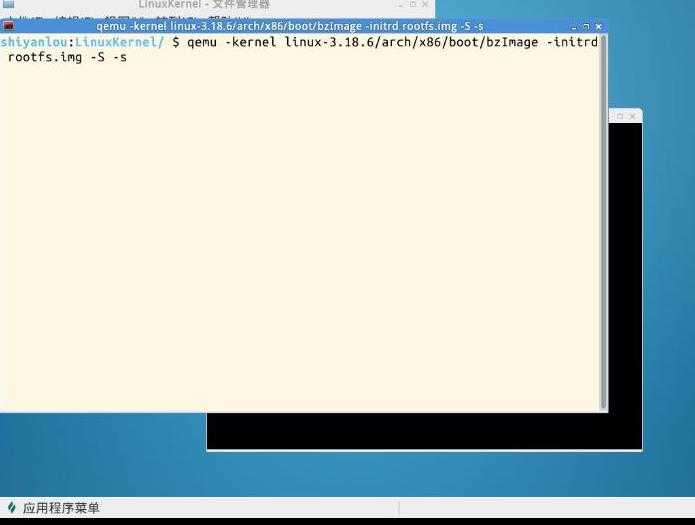
2、然后打开另一个终端输入
gdb (gdb)file linux-3.18.6/vmlinux (gdb)target remote:1234 (gdb)b schedule (gdb)c
进行调试跟踪schedule的执行过程 :
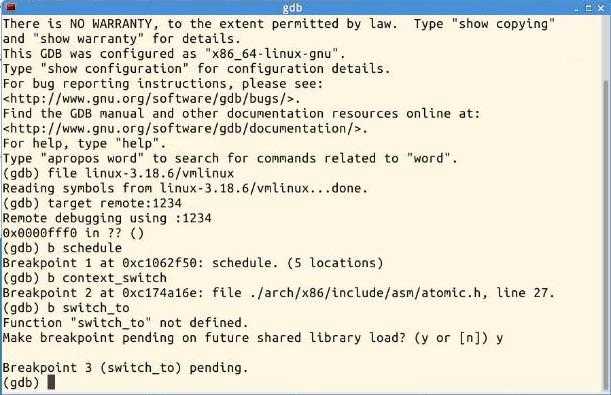
之后运行这些设置的断点:
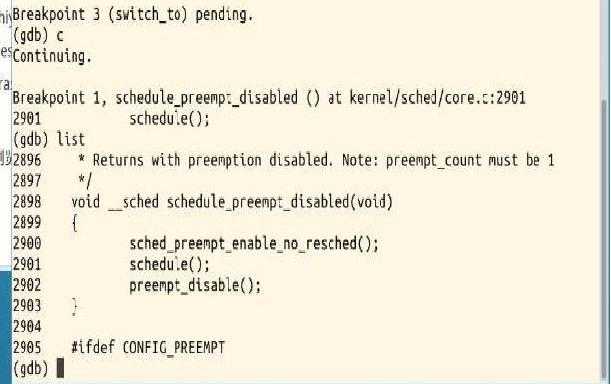
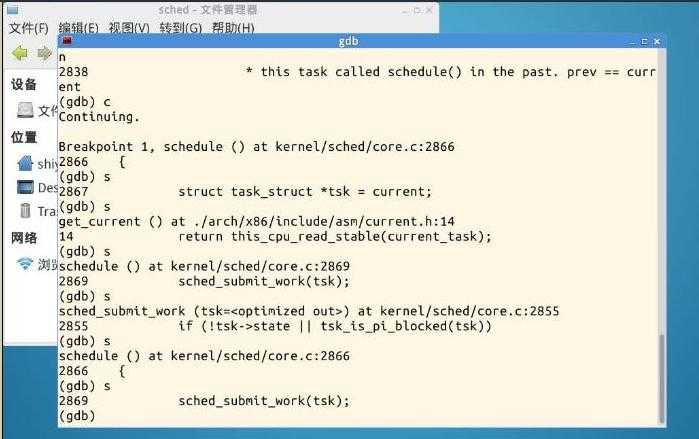

三、实验知识点总结:
进程调度时,首先进入schedule()函数,将一个task_struct结构体的指针tsk赋值为当前进程然后调用sched_submit_work(tsk) 我们进入这个函数,查看一下做了什么工作 我们在执行到sched_submit_work时,输入si进入函数,可以看到这个函数时检测tsk->state是否为0 (runnable)若为运行态时则返回tsk_is_pi_blocked(tsk),检测tsk的死锁检测器是否为空,若非空的话就return。然后检测是否需要刷新plug队列,用来避免死锁sched_submit_work主要是来避免死锁然后我们进入__schedule()函数。
之后我直接打开了一下switch_to.h,和core.c观察switch_to的调用:
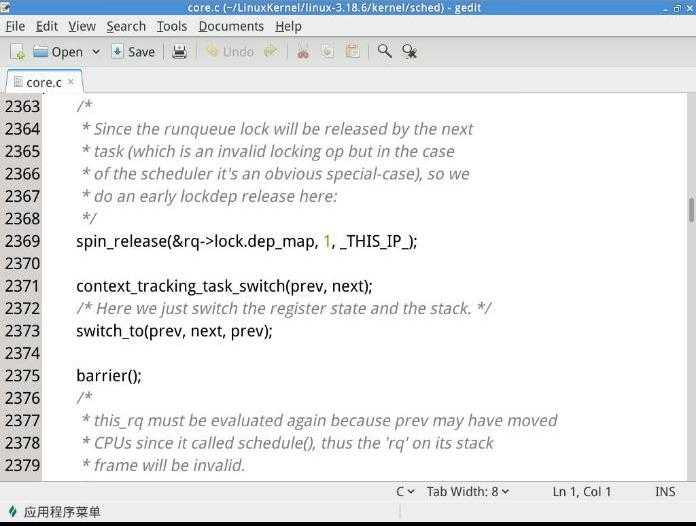
我们看到在context_switch中使用switch_to(prev,next,prev)来切换进程。
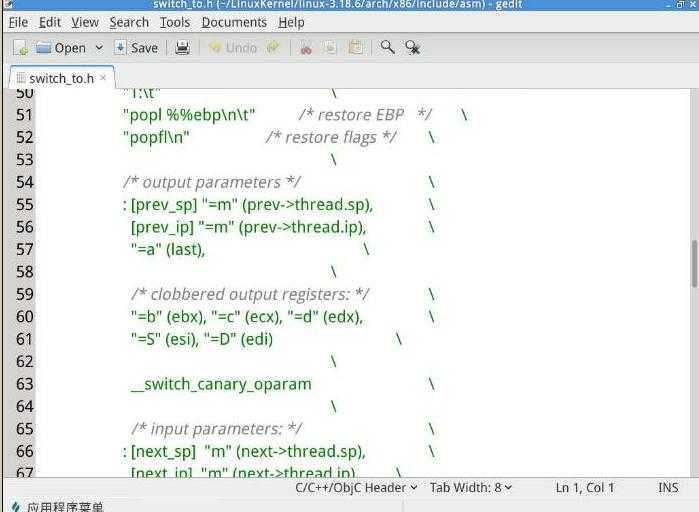
switch_to是一个宏定义,完成进程从prev到next的切换,首先保存flags,然后保存当前进程的ebp,然后把当前进程的esp保存到prev->thread.sp中,然后把标号1:的地址保存到prev->thread.ip中。然后把next->thread.ip压入堆栈。这里,如果之前B也被switch_to出去过,那么next->thread.ip里存的就是下面这个1f的标号,但如果next进程刚刚被创建,之前没有被switch_to出去过,那next->thread.ip里存的将是ret_ftom_fork__switch_canqry应该是现代操作系统防止栈溢出攻击的金丝雀技术。
jmp __switch_to使用regparm call, 参数不是压入堆栈,而是使用寄存器传值,来调用__switch_to
eax存放prev,edx存放next。这里为什么不用call __switch_to而用jmp,因为call会导致自动把下面这句话的地址(也就是1:)压栈,然后__switch_to()就必然只能ret到这里,而无法根据需要ret到ret_from_fork。当一个进程再次被调度时,会从1:开始执行,把ebp弹出,然后把flags弹出。
本次的实验让我们看到了Linux是如何进行进程调度,又是在何时进行进程调度切换的。我们研究了几个进程调度的函数,并且看到了系统是如何在死锁状况出现时进行处理与恢复的。进程的调度是操作系统运行的重中之重,只有系统调用才能保障操作系统快速的运行多个任务,让多个任务同时进行,这样才能让操作系统的运行有意义,满足用户同时打开多个程序,同时进行多种任务,不会长时间处于等待之中
标签:
原文地址:http://www.cnblogs.com/puputongtong/p/5399405.html