标签:
第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-)
科科。。。妹子就算了,大晚上的爬点吃的吧。食物图集:抿一口,舔一舔,扭一扭~·SCD
写个简单的爬图爬虫方法还蛮多的。
这次尝试用urlib.request来实现。
读取图片网源码,利用re.compile找到其中符合要求的img标签生成图片list,最后用request.urlretrieve下载图片到本地。
Code:
import os import re import urllib.request def pic_collector(url): content = urllib.request.urlopen(url).read() r = re.compile(‘<img class="BDE_Image" pic_type="1" width="450" height="450" src="(.*?)" ‘) pic_list = r.findall(content.decode(‘utf-8‘)) os.mkdir(‘pic_collection‘) os.chdir(os.path.join(os.getcwd(), ‘pic_collection‘)) for i in range(len(pic_list)): pic_num = str(i) + ‘.jpg‘ urllib.request.urlretrieve(pic_list[i], pic_num) print("success!" + pic_list[i]) pic_collector("http://tieba.baidu.com/p/4341640851")
Note:
1. re.compile()内容由网页源代码决定。比如我扒的这个网页,用chrome查看源代码,找到想下载的包含图片的<img>标签,其完整内容如下(以某一张图为例):
<img class="BDE_Image" pic_type="1" width="450" height="450" src="http://imgsrc.baidu.com/forum/w%3D580/sign=a6080fca870a19d8cb03840d03fb82c9/2683ea039245d688be88e4dfa3c27d1ed31b2445.jpg" size="259380">
即所扒的图片标签内容匹配‘<img class="BDE_Image" pic_type="1" width="450" height="450" src="(.*?)"‘。不必把标签完整的表达都写出来,但要包含到src内容
2. r.findall()中的content后要有decode(‘utf-8‘)这样才是能看懂的utf-8格式网页源代码
3. os.mkdir(filename)新建文件夹;os.chdir(filename)更改路径到xx文件夹;os.getcwd()获取当前文件夹名(字符串)
4. urllib.request.urlretrieve(pic,pic_name) 保存图片到上述路径并设定文件名
保存的文件如下图:
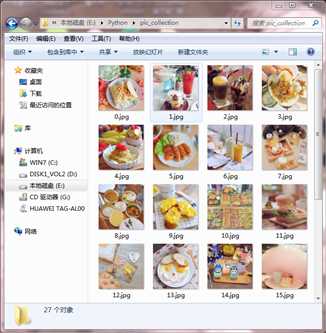
今后看到美少年的皂片不必再无限右键了,朕心甚慰_(:3 」∠)_
哦,要是在贴吧、堆糖想下载xx页到xx页图片怎么办,。? ? ?。
比如上面那个图片贴,网址是酱紫的:
http://tieba.baidu.com/p/4341640851?pn=1 #第1页 http://tieba.baidu.com/p/4341640851?pn=2 #第2页 http://tieba.baidu.com/p/4341640851?pn=3 #第3页 http://tieba.baidu.com/p/4341640851?pn=4 #第4页 ... http://tieba.baidu.com/p/4341640851?pn=n #第n页
那就改一下代码啦:
import urllib.request import re import os def fetch_pictures(url, m, n): os.chdir(os.path.join(os.getcwd(), ‘pic_collection‘)) temp = 1 # 记录图片张数 for x in range(n-m+1): html_content = urllib.request.urlopen(url + "?pn=" + str(n+x-1)).read() # key! r = re.compile(‘<img class="BDE_Image" pic_type="1" width="450" height="450" src="(.*?)" ‘) picture_url_list = r.findall(html_content.decode(‘utf-8‘)) print(picture_url_list) for i in range(len(picture_url_list)): picture_name = str(temp) + ‘.jpg‘ urllib.request.urlretrieve(picture_url_list[i], picture_name) print("Success!" + picture_url_list[i]) temp += 1 fetch_pictures("http://tieba.baidu.com/p/4341640851", 1, 3)
这样就可以下载第1~3页的图片了,向下整张帖子的图片就看下页数自己改呗。
标签:
原文地址:http://www.cnblogs.com/liez/p/5397447.html