标签:
Hibernate学习笔记
Java相关课程系列笔记之十四
笔记内容说明
Hibernate(梁建全老师主讲,占笔记内容100%);
目 录
一、 Hibernate的概述...................................................................................................................1
1.1Hibernate框架的作用........................................................................................................1
1.2 Hibernate访问数据库的优点............................................................................................ 1
1.3 JDBC访问数据库的缺点.................................................................................................. 1
1.4 Hibernate的设计思想........................................................................................................ 1
二、 Hibernate的基本使用...........................................................................................................2
2.1 Hibernate的主要结构........................................................................................................2
2.2Hibernate主要的API........................................................................................................2
2.3 Hibernate使用步骤............................................................................................................2
2.4HQL语句(简要介绍)...................................................................................................6
三、 数据映射类型.......................................................................................................................7
3.1映射类型的作用.................................................................................................................7
3.2 type映射类型的两种写法.................................................................................................7
四、 Hibernate主键生成方式.......................................................................................................8
4.1五种生成方式.....................................................................................................................8
五、 Hibernate基本特性...............................................................................................................9
5.1对象持久性.........................................................................................................................9
5.2处于持久状态的对象具有的特点.....................................................................................9
5.3三种状态下的对象的转换.................................................................................................9
5.4批量操作:注意及时清除缓存.........................................................................................9
5.5案例: 三种状态下的对象使用....................................................................................... 10
5.6一级缓存机制(默认开启)...........................................................................................10
5.7一级缓存的好处...............................................................................................................10
5.8管理一级缓存的方法....................................................................................................... 10
5.9延迟加载机制...................................................................................................................11
5.10具有延迟加载机制的操作............................................................................................. 11
5.11常犯的错误.....................................................................................................................12
5.12延迟加载的原理.............................................................................................................12
5.13 Session的 get和 load方法的区别................................................................................ 12
5.14延迟加载的好处.............................................................................................................12
5.15案例: 测试延迟加载..................................................................................................... 12
5.16案例: 重构 NetCTOSS资费管理模块.........................................................................13
5.17 Java Web程序中如何用延迟加载操作 (OpenSessionInView) ................................ 15
六、 关联映射............................................................................................................................. 18
6.1一对多关系 one-to-many................................................................................................. 18
6.2多对一关系 many-to-one................................................................................................. 19
6.3多对多关联映射 many-to-many...................................................................................... 19
6.4关联操作 (查询 join fetch/级联 cascade) ....................................................................21
6.5继承关系映射...................................................................................................................24
七、 Hibernate查询方法.............................................................................................................27
7.1HQL查询.........................................................................................................................27
7.2 HQL和 SQL的相同点...................................................................................................27
7.3 HQL和 SQL的不同点....................................................................................................27
7.4HQL典型案例.................................................................................................................27
7.5 Criteria查询.....................................................................................................................30
7.6Native SQL原生 SQL查询.............................................................................................31
八、 Hibernate高级特性.............................................................................................................32
8.1二级缓存...........................................................................................................................32
8.2二级缓存开启方法及测试............................................................................................... 32
8.3二级缓存管理方法...........................................................................................................33
8.4二级缓存的使用环境.......................................................................................................33
8.5查询缓存...........................................................................................................................33
8.6查询缓存开启方法及测试............................................................................................... 33
8.7查询缓存的使用环境.......................................................................................................33
九、 Hibernate锁机制.................................................................................................................34
9.1悲观锁...............................................................................................................................34
9.2悲观锁的实现原理...........................................................................................................34
9.3悲观锁使用步骤及测试...................................................................................................34
9.4乐观锁...............................................................................................................................35
9.5乐观锁的实现原理...........................................................................................................35
9.6乐观锁使用步骤及测试...................................................................................................35
十、 其他注意事项.....................................................................................................................36
10.1源码服务器管理工具.....................................................................................................36
10.2利用 MyEclipse根据数据表自动生成实体类、 hbm.xml...........................................36
10.3根据实体类和 hbm.xml生成数据表.............................................................................37
10.4 Hibernate中分页查询使用 join fatch的缺点...............................................................37
10.5 Hibernate的子查询映射................................................................................................ 38
Hibernate 的概述一
、.1 Hibernate框架的作用
Hibernate框架是一个数据访问框架(也叫持久层框架,可将实体对象变成持久对象,详见第5章)。通过 Hibernate框架可以对数据库进行增删改查操作, 为业务层构建一个持久层。可以使用它替代以前的 JDBC访问数据。
1.2 Hibernate访问数据库的优点
1)简单,可以简化数据库操作代码。
2) Hibernate可以自动生成 SQL,可以将 ResultSet中的记录和实体类自动的映射(转化)。
Hibernate不和数据库关联,是一种通用的数据库框架(支持30多种数据库),
方便数据库移植。任何数据库都可以执行它的 API。因为 Hibernate的 API中是不涉及 SQL
语句的, 它会根据 Hibernate的配置文件, 自动生成相应数据库的 SQL语句。
1.3 JDBC访问数据库的缺点
需要编写大量的复杂的 SQL语句、 表字段多时 SQL也繁琐、 设置各个问号值。
需要编写实体对象和记录之间的代码, 较为繁琐。数据库移植时需要修改大量的 SQL语句。
1.4 Hibernate的设计思想
Hibernate是基于ORM(Object Relation Mapping)思想设计的,称为对象关系映射。负
责 Java
Hibernate是一款主流的 ORM工具,还有其他很多 ORM工具,如: MyBatis(以前叫 iBatis)、
JPA。 Hibernate功能比 MyBatis强大些, 属于全自动类型, MyBatis属于半自动。但全自动会
有些不可控因素, 因此有些公司会用 MyBatis。
ORM工具在完成 Java对象和数据库之间的映射后:
在查询时, 直接利用工具取出“对象”(不论是查询一条记录还是多条记录, 取出的
都是一个个对象, 我们不用再去转化实体了)。
在增删改操作时,直接利用工具将“对象”更新到数据库表中(我们不用再去把对象
转成数据了)。
中间的 SQL+JDBC细节, 都被封装在了工具底层, 不需要程序员参与。注意事项:
v Java程序想访问数据库, 只能通过 JDBC的方式,而 Hibernate框架也就是基于
ORM思想对 JDBC的封装。
v Hibernate是以“对象”为单位进行数据库的操作。
二、 Hibernate的基本使用
2.1 Hibernate的主要结构
1) hibernate.cfg.xml(仅1个): Hibernate的主配置文件,主要定义数据连接参数和框架
设置参数。
u 注意事项:就是个xml文件,只是名字比较奇葩!
2) Entity实体类(n个,一个表一个):主要用于封装数据库数据。
3) hbm.xml映射文件(n个): 主要描述实体类和数据表之间的映射信息。 描述表与类,字段与属性的对应关系。
u 注意事项: hbm.xml是个后缀,如:命名可写Cost.hbm.xml。
2.2 Hibernate主要的 API
1) Configuration: 用于加载 hibernate.cfg.xml配置信息。 用于创建 SessionFactory。
2) SessionFactory:存储了 hbm.xml中描述的信息,内置了一些预编译的 SQL,可以创建 Session对象。
3) Session: 负责对数据表执行增删改查操作。 表示 Java程序与数据库的一次连接会话,是对以前的 Connection对象的封装。 和 JSP中的 session不是一回事, 就是名字一样而已。
4) Query:负责对数据表执行特殊查询操作。
5) Transaction: 负责 Hibernate操作的事务管理。 默认情况下 Hibernate事务关闭了自动
提交功能, 需要显式的追加事务管理(如调用 Transaction对象中的 commit();提交事务)!
u 注意事项:
v 这些 API都是在 Hibernate包下的, 导包别导错!
v 第一次访问数据库比较慢,比较耗资源,因为加载的信息多。
2.3 Hibernate使用步骤
step1:建立数据库表。
step2:建立 Java工程(Web工程也可),引入Hibernate开发包和数据库驱动包。必须引入的包: hibernate3.jar、 cglib.jar、 dom4j.jar、 commons-collections.jar、 commons-logging.jar„等
step3: 添加 hibernate.cfg.xml配置文件, 文件内容如下:
<?xml version=‘1 .0‘ encoding=‘UTF-8‘?>
<! DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD3.0//EN"
"http://hibernate. sourceforge.net/hibernate-configuration-3 .0.dtd">
<hibernate-configuration>
<session-factory>
<property name="dialect"><!-- 指定方言, 决定 Hibernate生成哪种 SQL-->
org.hibernate.dialect.OracleDialect<!-- 不知道数据库版本就写 OracleDialect-->
</property><!--可在 hibernate3.jar中 org.hibernate.dialect包下查看名字-->
<property name="connection.url">
jdbc:oracle:thin: @localhost: 1 52 1 :dbchang
</property>
<property name="connection.username">system</property>
<property name="connection.password">chang</property>
<property name="connection.driver_class">
oracle.jdbc.driver.OracleDriver
</property>
<!--框架参数, 将 hibernate底层执行的 SQL语句从控制台显示-->
<property name="show_sql">true</property>
<!--格式化显示的 SQL-->
<property name="format_sql">true</property>
<!--指定映射描述文件-->
<mapping resource="org/tarena/entity/Cost.hbm.xml" />
</session-factory>
</hibernate-configuration>
u 注意事项:应该放在源文件的 src目录下,默认为 hibernate.cfg.xml。文件内容是
Hibernate工作时必须用到的基础信息。
step4:编写Entity实体类(也叫 POJO类),例如:资费实体类Cost
private Integer id; //资费 ID private String feeName; //资费名称
private Integer baseDuration; //基本时长 private Float baseCost; //基本定费
private Float unitCost; //单位费用 private String status; //0: 开通; 1: 暂停;private String descr; //资费信息说明 private Date createTime; //创建日期
private Date startTime; //启用日期 private String costType; //资费类型
„„getter/setter方法
u 注意事项: POJO类表示普通类(Plain Ordinary Old Object),没有格式的类,只有
属性和对应的 getter/setter方法,而没有任何业务逻辑方法的类。这种类最多再加入
equals()、 hashCode()、 toString()等重写父类 Object的方法。不承担任何实现业务逻
辑的责任。
step5:编写hbm.xml映射(文件)描述信息:映射文件用于指明 POJO类和表之间的映射关系(xx属性对应xx字段),一个类对应一个映射文件。例如: Cost.hbm.xml内容如下:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC"-//Hibernate/Hibernate Mapping DTD3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<!-- 定义 COST_CHANG表和 Cost类型之间的映射信息 -->
<hibernate-mapping><!-- <hibernate-mapping package="包名写这也行"> -->
<!--name:包名.类名,指定是哪个类; table:数据库中哪个表; catalog:对Oracle而言为哪个数据库, 对 MySQl而言为某个用户(MySQl是在用户下建表, Oracle是在库中建表),不写也行(若用工具则会自动生成)。例如, select* from cost_chang则会在 hibernate.cfg配置文件中定义的库(或用户)下去找表。若写了则为 select*from system.cost_chang -->
<class name="org.tarena.entity.Cost" table="COST_CHANG" catalog="system">
<!-- <id></id>表明此为主键列,且必须写否则xml报错,主键映射-->
<id name="id" type="java.lang.Integer">
<column name="ID" /><!-- 或双标签<column name="ID"></column> -->
<!--指定主键值生成方式,采用序列方式生成主键,仅对添加操作有效-->
<generator class="sequence">
<param name="sequence">COST_SEQ_CHANG</param> <!--指定序列名-->
</generator>
</id>
<propertyname="name"type="java.lang.String"><!--以下为非主键映射-->
<column name="NAME" /><!--可有 length、 not-null属性, 如: length="20" -->
</property>
<propertyname="baseDuration"type="java.lang.Integer"><!--映射顺序没关系-->
<column name="BASE_DURATION" />
</property>
<property name="baseCost" type="java.lang.Float"><!--类型要和实体定义的相同 -->
<column name="BASE_COST" />
</property>
<property name="startTime" type="java.sql.Date"><!--列名写错则报错读不到实体-->
<column name="STARTIME" /><!--junit测试右键点 Copy Trace查看错误列-->
</property>
<!--也可写成<property name=" " type=" " column=" "></property>, 主键列同理!-->
„„„„其他省略„„„„
</class>
</hibernate-mapping>
u 注意事项:
v 映射文件默认与POJO类放在一起;命名规则为:类名.hbm.xml。
v hbm.xml中已写出的属性与字段的映射要一一对应,若表中没有某个字段,却
写了映射关系,则报错:找不到实体类。
step6: 利用 HibernateAPI实现 DAO
1)新建 HibernateUtil类,用于封装创建 Session的方法。如下:每个用户会对应一个
Session, 但是 SessionFactory是共享的。
public class HibernateUtil{
private static SessionFactory sf;
static{//不用每次都加载配置信息, 所以放 static块中, 否则每次都加载会耗费资源
Configuration conf=new Configuration();//加载主配置 hibernate.cfg.xml
conf.configure("/hibernate.cfg.xml");
sf=conf.buildSessionFactory();//获取SessionFactory }
public static Session getSession(){//获取 Session
Sessionsession=sf.openSession(); returnsession; } }
2) 新建 CostDAO接口
public Cost findById(int id); public void save(Cost cost);
public void delete(int id); public void update(Cost cost);
public List<Cost> findAll();
3)新建 CostDAOImpl类, 用于实现 CostDAO接口
public class CostDAOImpl implements CostDAO{
private Session session;
public CostDAOImpl() {//不想老写获得 session的方法, 就写在构造器中
session=HibernateUtil.getSession(); }
/** get方法执行查询, 按主键当条件查询, 如何判断是主键, 是根据写的描述文件来定,get方法就是findById,就是按主键去查,需指定:操作哪个类和id(主键)条件值即可,其他条件查询做不了*/
public Cost findById(int id) {
//Session session=HibernateUtil.getSession();
Costcost=(Cost)session.get(Cost.class,id); session.close(); returncost; }
/**save方法执行增加操作,注意1:获取事务并开启,增删改要注意,查询可以不管事务,因为没对数据库进行修改;注意2:主键值根据 hbm.xml中的<generator>定义生成,执行后, 会先获取序列值, 再去做 insert操作。
即先: selectCOST_SEQ_CHANG.nextvalfromdual;然后: insertinto„„ */
public void save(Cost cost) {
//Session session=HibernateUtil.getSession();
Transactiontx=session.beginTransaction();//打开事务 session.save(cost);
tx.commit();//提交事务 session.close();//释放 }
/** delete方法执行删除操作,由于 Hibernate以“对象”为单位进行数据库操作,所以这里要传进去一个对象,虽然是个对象,但还是按主键做条件删除,只要把主键值设置上就行,其他非主键值不用管。也可先通过id查再删*/
public void delete(int id) {
//Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction(); Cost cost=new Cost();
cost.setId(id); session.delete(cost); tx.commit(); session.close(); }
/** update方法执行修改操作, */
public void update(Cost cost) {
//Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
session.update(cost);//将 cost对象更新到数据库 tx.commit();
session.close();
}
/**特殊查询, SQL语句: String sql="select* from COST_CHANG";
HQL语句: String hql="from Cost"; (Hibernate Query Language)是面向对象的查询语句。from后写映射的类名,它是Hibernate中特有的查询语句,根据映射的类去查询。 */
public List<Cost> findAll() {
//Session session=HibernateUtil.getSession();
String hql="from Cost";//HQL语句
Query query=session.createQuery(hql);
List<Cost> list=query.list();//执行查询, 返回 List集合
session.close(); returnlist; } }
4) 新建 TestCostDAO类, 使用 junit测试
@Test
public void testFindById(){//当 get方法没有记录时, 返回 null
CostDAO costDao= new CostDAOImpl(); Cost cost= costDao.findById(1);
System.out.println(cost.getName());System.out.println(cost.getBaseDuration());
System.out.println(cost.getBaseCost()); System.out.println(cost.getUnitCost());
System.out.println(cost.getDescr()); }
@Test
public void testSave(){//id主键列由 Hibernate管理, 这里不用设置
Cost cost=newCost(); cost.setName("2013计时");
cost.setUnitCost(0.8f); cost.setDescr("2013-08-09计时, 0.8元/小时。");
cost.setStatus("0"); cost.setCreaTime(newDate(System.currentTimeMillis()));
CostDAO costDao= new CostDAOImpl(); costDao.save(cost); }
@Test
public void testUpdate(){//开通某个资费, 把状态由 0变为1
CostDAO costDAO=new CostDAOImpl();
/**注意事项:更新部分字段,不能和实现类中的删除那样,做一个对象出来!否
则没设置的字段将被改为空! 即不能: Costcost=newCost(); cost.setId(90);
cost. setStatus(" 1 "); cost.setStartTime(new Date(System.currentTimeMillis())); */
Cost cost=costDAO.findById(90);//只能先通过 id找到带有所有值的对象
cost.setStatus(" 1 ");//然后再对部分字段进行更新, 才能避免把其他字段更新为空
cost.setStartTime(new Date(System.currentTimeMillis()));
costDAO.update(cost); }
@Test
public void testDelete(){
CostDAOcostDAO=newCostDAOImpl(); costDAO.delete(90); }
@Test
public void testFindAll(){
CostDAO costDAO=new CostDAOImpl(); List<Cost> list=costDAO.findAll();
for(Costc:list){ System.out.println(c.getName()); } }
2.4 HQL语句 (简要介绍)
简要介绍见2.3节中 step6中的3)特殊查询(本页最上)。详细介绍见第七章。
三、 数据映射类型
hbm.xml在描述字段和属性映射时, 采用 type属性来指定映射类型。
3 .1 映射类型的作用
主要负责实现属性和字段值之间的相互转化。
3.2 type 映射类型的两种写法
1)指定 Java类型,例如: java.lang.String、 java.lang.Integer„,不能写成String„ 2)指定Hibernate类型,例如:
①整数: byte、 short、 integer、 long;
②浮点数: float、 double; ③字符串: string;
④日期和时间: date(只处理年月日), time(只处理时分秒), timestamp(处理年
月日时分秒);
⑤布尔值: true/false<-yes_no->char(1)(数据库存 Y/N, 显示时自动转为 true/false)、
true/false<-true_false->char(1) (数据库存 T/F, 显示时自动转为 true/false)、
true/false<-boolean->bit (数据库存1/0, 显示时自动转为 true/false);
⑥其他: blob(以字节为单位存储大数据)、 clob(以字符为单位存储大数据)、
big_decimal、 big_integer;
u 注意事项: Hibernate类型都是小写!建议使用 Hibernate类型。
3)所以2.3节中 step5的 Cost.hbm.xml内的 type也可这样写:
<property name="name" type="string"><column name="NAME" /></property>
<property name="baseCost" type="float"><column name="BASE_COST" /></property>
<property name="startTime" type="date"><column name="STARTIME" /></property>
u 注意事项:
v java.util.Date有年月日时分秒毫秒,但如果用 date映射,则只把年月日存进数
据库; java.sql.Date只有年月日。 java.sql.Timestamp有年月日时分秒毫秒。
v 若在页面显示按特定格式显示则用 Struts2标签:
<s: date name="属性名" format="yyyy-MM-dd HH: mm: ss"/>
四、 Hibernate主键生成方式
Hibernate 负责管理主键值。 它提供了多种主键生成方式。
4.1五种生成方式
1) sequence:可以按指定序列生成主键值。只适用于 Oracle数据库。不担心并发量!
例如: <generator class="sequence">
<param name="sequence">序列名字</param></generator>
u 注意事项:创建序列时如果不指定参数,默认从1开始,步进是1。
2) identity:按数据库自动增长机制生成主键值。一般适用于 MySql、 SQLServer数据库。
例如: <generator class="identity"></generator>
3) native: Hibernate 会根据方言类型不同, 选择不同的主键生成方式。 如果是OracleDialect则会选择 sequence, 如果是 MySQLDialect则会选择 identity。
例如: <generator class="native"></generator>
u 注意事项:如果是 MySql数据库,<paramname="sequence">序列名字</param>是不
起作用的, 但也不会出错; 如果是 Oracle数据库, <param name="sequence">序列名
字</param>就会起作用, 所以一般我们会加上这句话, 这样通用性更强。
4) assigned: Hibernate会放弃主键生成,采用此方法,需要在程序中指定主键值。
例如: <generator class="assigned"></generator>
5) increment: Hibernate先执行 selectmax(id)...语句获取当前主键的最大值,执行加1操作, 然后再调用 insert语句插入。 Oracle和 MySQL都可用。 但不适合并发量很大的情况!
例如: <generator class="increment"></generator>
6) uuid/hilo: uuid:按UUID算法生成一个主键值(字符串类型); hilo:按高低位算法生成一个主键值 (数值类型)。
例如: <generator class="hilo"></generator>
u 注意事项:
v 主键一般都是自动生成的。我们一般不使用业务数据作为主键,因为业务逻辑
的改变有可能会改变主键值。
v 主键生成方式是枚举类型,只能从一个有限的范围内选择,不能自定义。其中,
sequence是使用序列生成主键(Oracle数据库经常使用)。
5.1对象持久性
五、 Hibernate基本特性
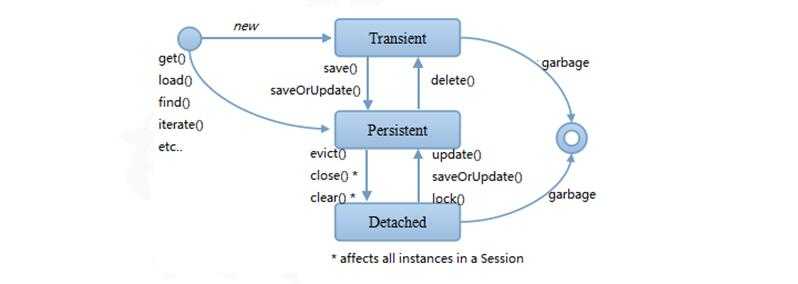
在 Hibernate使用过程中, 实体对象可以具有以下三种状态:
1)临时状态:采用 new关键字创建的对象,该对象未与 Session发生关联(未调用
Session的 API)。 也叫临时对象。 临时状态的对象会被 Java的垃圾回收机制回收。
2)持久状态:实体对象与 Session发生关联(调用了 Session的get、 load、 save、 update 等 API)。 也叫持久对象。
3)游离状态:原来是持久状态,后来脱离了 Session的管理。如: Session被关闭,对象
将从持久状态变为游离状态, 同时垃圾回收机制可以回收掉, 不再占用缓存空间了。
5.2处于持久状态的对象具有的特点
对象生命期持久,垃圾回收机制不能回收。
对象的数据可以与数据库同步 (即对象中的数据发生改变, 则数据库中的数据自动同
步)。 由 Session对象负责管理和同步。
对象在 Session的一级缓存中存放 (或者说在 Session缓存中的对象都是持久对象)。
注意事项: Session.close();有两个作用:①关闭连接、释放资源②使对象变为游离状
态,当对象的引用不存在时,对象才被回收。没被回收时,对象中的数据还在!
5.3 三种状态下的对象的转换
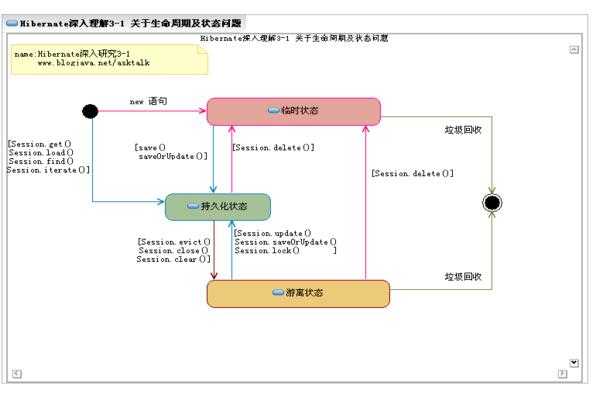
5.4批量操作: 注意及时清除缓存
Transaction tx= session.beginTransaction();
for(int i=0;i<100000;i++){ Foo foo= newFoo();
session.save(foo);//设置 foo属性
if(i%50==0){//够50个对象, 与数据库同步下, 并清除缓存
session.flush();//同步
session.clear();//清除缓存
} }
tx.commit();
5.5案例: 三种状态下的对象使用
当持久对象数据改变后, 调用 session.flush()方法,会与数据库同步更新。
commit()方法, 内部也调用了 flush()方法, 因此使用 commit()方法可以省略 flush()方法的调用。
@Test
publicvoidtest1(){//Foo实体有id、 name、 salary、 hireDate、 marry等属性
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
Foo foo=(Foo)session.get(Foo.class, 1);//foo具有持久性
foo.setName("chang"); foo.setSalary(6000);
/**提交事务,若后面不写 flush,只写提交 commit,则也能执行更新操作。因为 commit 在内部会先调用 flush,再提交事务,所以此时flush可不写*/
tx.commit();
/**触发同步动作,同步和提交是两回事。数据有变化才同步(更新),没变化不会更新*/
session.flush(); session.close();//关闭session释放资源 }
@Test
public void test2(){
Foofoo=newFoo(); foo.setName("tigger"); foo.setSalary(8000);
foo.setMarry(true); foo.setHireDate(newDate(System.currentTimeMillis()));
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
session.save(foo);//以上都是临时状态, 此时由临时状态转为持久状态
foo.setSalary(10000);//修改 foo持久对象的数据, 也是更新操作, 可不写 update方法
tx.commit();//同步、提交 session.close(); }
@Test
public void test3(){
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
Foo foo=(Foo)session.get(Foo.class, 2);//foo具有持久性
session.clear();//下面的则不会与数据库同步了
foo.setName("常"); foo.setSalary(8800);
tx.commit(); //session.flush();//数据有变化才同步 update,没变化不会update session.close(); }
5.6一级缓存机制 (默认开启)
一级缓存被称为 Session级别的缓存: 每个 Session都有自己独立的缓存区, 该缓存区随
着 Session创建而开辟(由 SessionFactory创建), 随着 Session.close()而释放。
该缓存区可以存储当前 Session关联的持久对象。 只有在缓存区中, Session才管该对象。
5.7一级缓存的好处
Hibernate在查询时,先去缓存当中查找,如果缓存中没有,才去数据库查询。如果利用Session对同一个对象查询多次,第一次去数据库查,后续的会从缓存查询,从而减少了与数据库的交互次数。
5.8 管理一级缓存的方法
1) session.evict()方法:将对象清除。
2) session.clear()方法:清除所有对象。
3) session.close()方法:清除所有对象,并关闭与数据库的连接。
u 注意事项: 不同的 session的缓存区不能交叉访问。
4)案例:测试一级缓存
@Test
public void test1(){ Session session=HibernateUtil.getSession();
Foo foo1=(Foo)session.get(Foo.class, 1);//第一次查询
System.out.println(foo1 .getName());//能出现 SQL 查询语句
Foo foo2=(Foo)session.get(Foo.class, 1);//后续查询
System.out.println(foo2.getSalary());//不能出现 SQL查询语句
session.close(); } @Test
public void test2(){ Session session=HibernateUtil.getSession();
Foo foo1=(Foo)session.get(Foo.class, 1);//第一次查询
System.out.println(foo1 .getName());//能出现 SQL 查询语句
session.evict(foo1); //或session.clear(foo1);
Foo foo2=(Foo)session.get(Foo.class, 1);//后续查询
System.out.println(foo2.getSalary());//能出现 SQL查询语句
session.close(); } @Test
public void test3(){ Session session=HibernateUtil.getSession();
Foo foo1=(Foo)session.get(Foo.class, 1);//不同的对象, 所以查询两次
System.out. println(foo1 .getName());
Foofoo2=(Foo)session.get(Foo.class,2); System.out.println(foo2.getName()); } @Test
public void test4(){ Session session=HibernateUtil.getSession();
Foo foo1=(Foo)session.get(Foo.class, 1); System.out.println(foo1.getName());
session.close();
session=HibernateUtil.getSession();//不同的 session 的缓存区不能交叉访问
Foo foo2=(Foo)session.get(Foo.class, 1);//又一次查询
System.out.println(foo2.getName()); }
5.9延迟加载机制
Hibernate在使用时, 有些 API操作是具有延迟加载机制的。
延迟加载机制的特点:当通过 Hibernate的 API获取一个对象结果后,该对象并没有数据库数据。 当通过对象的 getter方法获取属性值时, 才去数据库查询加载。
5.10 具有延迟加载机制的操作
1) session.load();//延迟加载查询, session.get();是立即加载查询
2) query.iterator();//查询
3)获取关联对象的属性信息
u 注意事项:这些方法返回的对象,只有id属性(主键)有值,其他属性数据在使用
的时候(调用 getXXX()方法时,除主键外,调主键 get方法不会发 SQL)才去获取。
5.11常犯的错误
1)报错: LazyInitializationException: could not initialize proxy- no Session, 原因: 代码
中使用了延迟加载操作, 但是 session在加载数据前关闭了。 只要看到这个类名:
LazyInitializationException就都是 session过早关闭, 后面的描述可能不同。
2)报错: NonUniqueObjectException: a different object with the same identifier value was already associated with the session, 原因: 有两个不同对象, 但是主键, 即 id却相同。例如:
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
Account account1=(Account)session.get(Account.class, 1010);//将 account1放入缓存
System.out.println(account1 .getRealName());System.out.println(account1 .getIdcardNo());
Account account2=newAccount(); account2.setId(1010);
//update操作会将 accont2放入缓存,此时会出现异常,缓存中已经存在一个1010对象,
不允许再放入 id为1010的对象
session.update(account2); tx.commit(); session.close();
5.12延迟加载的原理
在使用延迟加载操作后, Hibernate返回的对象是 Hibernate利用 CGLIB技术 (cglib.jar)新生成的一个类型 (动态的在内存中生成)。 在新类型中, 将属性的 getter方法重写。 新生成的类是原实体类的子类 (继承关系)。
例如: public class Foo$$EnhancerByCGLIB$$87e5f322 extends Foo{
public String getName(){
//判断是否已加载过数据,如果加载过,返回 name值
//没有加载过, 则发送 SQL语句查询加载数据, 然后返回 name值
} }
u 注意事项:一般情形: *.java-->*.class-->载入类加载器-->执行
延迟加载: javassist.jar/cglib.jar(生成新类型)-->类加载器-->执行
5.13 Session的 get和 load方法的区别
1)相同点:两者都是按“主键”做条件查询。
2)不同点:①get是立刻加载; load是延迟加载。
②get返回的对象类型是实体类型; load返回的是动态生成的一个代理类 (动态代
理技术), 该代理类是实体类的子类。
③get未查到数据返回 null; load未查到数据抛出 ObjectNotFoundException异常。
u 注意事项: 若实体类用了 final修饰, 则破坏了延迟加载机制,那么 load效果与 get
就完全相同了。
5.14延迟加载的好处
1) 提高了内存的使用效率。
5.15案例: 测试延迟加载
2) 可以使数据访问降低并发量。
@Test
public void test1(){ Session session=HibernateUtil.getSession();
//load是延迟加载, foo没有数据
Foo foo=(Foo)session.load(Foo.class, 1);//此时还没去数据库查询
//session.close();//放这里报错, session关的过早 could not initialize proxy- no Session
System.out.println(foo.getName());//第一次调用属性的 getter方法时触发查询
session.close();//放这里不报错,对象没被回收
System.out.println(foo.getSalary()); }
@Test
public void test2(){ Session session=HibernateUtil.getSession();
Foo foo=(Foo)session.load(Foo.class, 1);//此时还没去数据库查询
//类 org.tarena.entity.Foo$$EnhancerByCGLIB$$87e5f322, 由 cglib.jar生产
System.out.println(foo.getClass().getName()); session.close(); }
5.16案例:重构 NetCTOSS资费管理模块
step1: 引入 Hibernate开发框架 (jar包和主配置文件)
step2: 采用 Hibernate操作 COST_CHANG表
1)添加实体类
private Integer id; //资费 ID private String name; //资费名称 NAME
private Integer baseDuration; //包在线时长 BASE_DURATION
private Float baseCost; //月固定费 BASE_COST
private Float unitCost; //单位费用 UNIT_COST
privateStringstatus;//0:开通1:暂停; STATUS
private String descr; //资费信息说明 DESCR
private Date startTime; //启用日期 STARTTIME
private Date creaTime;//创建时间 CREATIME
2)追加 Cost.hbm.xml
<hibernate-mapping><!-- <hibernate-mapping package="包名写这也行"> -->
<class name="com.tarena.netctoss.entity.Cost" table="COST_CHANG" catalog="system">
<id name="id" type="java.lang.Integer">
<column name="ID" />
<generator class="sequence">
<param name="sequence">COS T_SEQ_CHANG</param>
</generator>
</id>
<property name="name" type="java.lang.String">
<column name="NAME" />
</property>
<property name="baseDuration" type="java.lang.Integer">
<column name="BASE_DURATION" />
</property>
<property name="baseCost" type="java.lang.Float"><!--类型要和实体定义的相同 -->
<column name="BASE_COST" />
</property>
„„„„„„„„其他略„„„„„„„„
</class>
</hibernate-mapping>
u 注意事项:
v 实体类和 hbm.xml必须保持一致!列名写错则会报:不能读取实体类。
v junit测试右键点 Copy Trace查看错误列。
step3: 借用2.3节中 step6的 HibernateUtil类
step4: 按 CostDAO接口重构一个 DAO实现组件: HibernateCostDAOImpl
public void delete(int id) throws DAOException{Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Costcost=newCost(); cost.setId(id); session.delete(cost);
tx.commit(); session.close();
}
public List<Cost> findAll() throws DAOException{
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
String hql="from Cost"; Query query=session.createQuery(hql);
Listlist=query.list(); tx.commit(); session.close(); returnlist;
}
public List<Cost> findAll(int page, int rowsPerPage) throws DAOException{
Session session=HibernateUtil.getSession();//分页查询
Transaction tx=session.beginTransaction(); String hql="from Cost";
Query query=session.createQuery(hql);
int start=(page-1)*rowsPerPage;//设置分页查询参数
query.setFirstResult(start);//设置抓取记录的起点,从0开始(第一条“记录”)query.setMaxResults(rowsPerPage);//设置抓取多少条记录
List list=query.list();//按分页参数查询
tx.commit(); session.close(); returnlist;
}
public Cost findById(Integer id) throws DAOException{
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Costcost=(Cost)session.load(Cost.class,id); tx.commit();
Stringname=cost.getName(); session.close(); returncost;
}
public Cost findByName(String name) throws DAOException{
//select* from COST_CHANG where NAME=?
String hql="from Cost where name=?";
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Query query=session.createQuery(hql);
query.setString(0, name);//注意 Hibernate赋值从 0开始, 即第一个问号
Cost cost=(Cost)query.uniqueResult();//适用于只有一行查询结果返回
//如果返回记录为多条,则会报错,多条用 query.list();
tx.commit(); session.close(); returncost;
}
public int getTotalPages(int rowsPerPage) throws DAOException{
//select count(*) from COST_CHANG
String hql="select count(*) from Cost";//类名
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Query query=session.createQuery(hql); Object obj=query.uniqueResult();
int totalRows=Integer.parseInt(obj.toString());
tx.commit(); session.close();
if(totalRows%rowsPerPage==0){ return totalRows/rowsPerPage;
}else{ return(totalRows/rowsPerPage)+1;
}
}
public void save(Cost cost) throws DAOException{
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();//下面的设置属性建议写到 Action中
cost.setStatus(" 1 "); cost.setCreaTime(new Date(System.currentTimeMillis()));
session.save(cost); tx.commit(); session.close();
}
public void update(Cost cost) throws DAOException{
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();//下面设置属性建议写到 Action中, 不
写 DAO中, 因为 update有通用性可封装, 到时无法确定 setXX方法
Cost cost1=(Cost)session.get(Cost.class, cost.getId());
cost1 .setName(cost.getName()); cost1 .setBaseDuration(cost.getBaseDuration());
cost1 .setUnitCost(cost.getUnitCost()); cost1 .setDescr(cost.getDescr());
session.update(cost1); tx.commit(); session.close();
}
step5: 修改 DAOFactory
private static CostDAO costDAO= new HibernateCostDAOImpl();
5.17 Java Web程序中如何用延迟加载操作(OpenSessionInView)
1) Java Web程序工作流程:
*.action-->Action-->DAO(延迟API)-->JSP(利用标签或EL获取数据,会触发延
迟加载数据) -->生成响应 HTML页面给浏览器。
2)基于上述原因,在 DAO中不能关闭 Session, 需要将 Session关闭放到 JSP解析之后(把 Session的关闭延迟到 View组件运行完之后), 这种模式被称为 OpenSessionInView。
3) OpenSessionInView和 ThreadLocal:
使用 OpenSessionInView必须满足 Session的线程单例, 一个线程分配一个 Session,
在该线程的方法中可以获得该 Session, 具体使用 ThreadLocal(一个线程为 key的 Map)。
Hibernate支持的 Session线程单例, 配置文件中:
<property name="current_session_context_class">thread</property>
然后调用: sessionFactory.getCurrentSession();//自动实现线程单例
4) OpenSessionInView模式也可以采用以下技术实现:
①利用 Struts2的拦截器(将关闭 session的操作写在拦截器中)。
step1: 基于 ThreadLocal技术改造2.3中 step6的 HibernateUtil类
public class HibernateUtil{ private static SessionFactory sf;
private static ThreadLocal<Session> sessionLocal= new ThreadLocal<Session>();
static{//不用每次都加载配置信息, 所以放 static块中, 否则耗费资源
Configuration conf=new Configuration();
conf.configure("/hibernate.cfg.xml");//加载主配置 hibernate.cfg.xml
sf=conf.buildSessionFactory();//获取SessionFactory
}
/**同一个线程,只创建一个 session,创建出来后利用 ThreadLocal将 session与当
前线程绑定*/
public static Session getSession(){ Session session=sessionLocal.get();
if(session==null){//当前线程第一次调用,创建一个
session=sf.openSession();
sessionLocal.set(session);//将 session存取 ThreadLocal
}
return session;//如果能取到 session, 说明当前线程已经创建过 session}
/**把关闭 session也封装一下*/
public static void closeSession(){ Session session=sessionLocal.get();
sessionLocal.set(null); if(session.isOpen()){
session.close();//关闭 session和释放 ThreadLocal空间
}
}
/**简单测试一下*/
public static void main(String[] args){
Session session1 = HibernateUtil.getSession();
Session session2 = HibernateUtil.getSession();
System.out.println(session1==session2);//true
}
}
step2:创建拦截器
public class OpenSessionInViewInterceptor extends AbstractInterceptor{//继承抽象类
@Override
public String intercept(ActionInvocation arg0) throws Exception{
Session session=HibernateUtil.getSession();
//开启事务, 或 Transaction tx=session.getTransaction(); tx.begin();
Transaction tx=session.beginTransaction();//等于以上两步
System.out.println("开启事务");
try{ arg0.invoke();//执行 action、 result-->jsp
if(!tx.wasCommitted()){ //当两个action连续调用时,避免重复提交
tx.commit();//提交事务 System.out.println("提交事务"); }
return null;
}catch(Exceptione) { tx.rollback();//回滚事务 System.out.println("回滚事务");
e.printStackTrace(); throwe;//受AbstractInterceptor类影响,必须抛异常
}finally{ HibernateUtil.closeSession(); //关闭 session
System.out.println("关闭事务");
}
}
}
u 注意事项: 重复提交的情况 redirectAction: add.action-->拦截器开启事务
-->AddCostAction-->拦截器开启事务-->ListCostAction-->cost_list.j sp-->拦截器
提交事务-->拦截器提交事务
step3: 在 NetCTOSS项目中的 struts-cost.xml中配置拦截器, 添加内容如下:
<interceptors>
<interceptor name="opensessioninview"
class="com.tarena.netctoss.interceptor.OpenSessionInViewInterceptor">
</interceptor>
<interceptor-stack name="opensessionStack">
<interceptor-ref name="opensessioninview"></interceptor-ref>
<interceptor-ref name="defaultStack"></interceptor-ref>
</interceptor-stack><!--默认的拦截器不能丢, 否则表单接收等不正常了-->
</interceptors>
<!--定义全局拦截器引用,若其他配置文件也有全局拦截器,则覆盖原来的,找最近的
(即在当前 struts-cost.xml中有效)类似于 Java中的局部变量-->
<default-interceptor-ref name="opensessionStack"></default-interceptor-ref>
step4:将5.16案例中 step4中的 HibernateCostDAOImpl类里的所有方法中的开
启事务、提交事务、关闭 Session全部删除。
②利用 Filter过滤器。
public void doFilter(request,response,chain){
//前期处理逻辑
chain.doFilter(request,response);//调用后续 action,result组件
//后期处理逻辑。 关闭 session
③利用 Spring的 AOP机制。
六、关联映射
关联映射主要是在对象之间建立关系。开发者可以通过关系进行信息查询、添加、删除和更新操作。
如果不使用 Hibernate 关联关系映射, 我们也可以取到用户对应的服务。
Account account= (Account)session.get(Account.class, 1);//取到用户信息String hql="from Service s where s.accountId=1";
Query query= session.createQuery(hql);//取到用户对应的服务
List<Item> list= query.list();
而 Hibernate提供的关联映射, 更方便一些。
6.1一对多关系 one-to-many
step1:新建项目,导入 Hibernate开发包,借用 NetCTOSS项目中的实体: Account和 Service,配置 hibernate.cfg.xml和两个实体的 hbm.xml映射文件。
step2: 一个 Account帐号对应多个 Service服务, 所以为一对多关系。 因此为 One方 Account 实体类添加 Set集合属性, 以及对应的 get/set方法。
//追加属性, 用于存储相关联的 Service信息
private Set<Service> services=new HashSet<Service>();
step3: 在 One方 Account.hbm.xml映射文件中, 加入 Set节点的映射
简单说明:
<set name="属性名">
<!--关联条件, column写外键字段,会默认的与ACCOUNT表的主键相关联-->
<key column="指定关联条件的外键字段"></key>
<!--指定采用一对多关系, class指定关联的类型-->
<one-to-manyclass="要关联的另一方(N方)"/>
</set>
具体实现:
<!--描述 services属性,采用一对多关系加载 service记录-->
<!-- 是 list集合用<list name=""></list> set集合用<set name=""></set> -->
<set name="services">
<key column="ACCOUNT_ID"></key><!--ACCOUNT_ID是 Service表中字段-->
<one-to-many class="org.tarena.entity.Service"/>
</set>
step4: 借用5.17节4)中的 step1中的 HibernateUtil类step5: 新建 TestOneToMany.java类用于测试
@Test
public void test1(){ Session session=HibernateUtil.getSession();
Account account=(Account)session.load(Account.class, 1011);//第一次发送 SQL查询
System.out.println(account.getRealName()); System.out.println(account.getIdcardNo());
/**显示与当前帐号相关的 Service业务帐号, 以前的方式需要写 hql:
String hql="from Service where ACCOUND_ID=1011";用了关联映射则不用写 hql了*/
Set<Service> services=account.getServices();//延迟加载, 第二次发送 SQL查询
for(Service s: services) {
System.out.println(s.getId()+" "+s.getOsUsername()+" "+s.getUnixHost());
}
session.close();
}
6.2多对一关系 many-to-one
step1:新建项目,导入 Hibernate开发包,借用 NetCTOSS项目中的实体: Account和 Service,配置 hibernate.cfg.xml和两个实体的 hbm.xml映射文件。
step2: 可多个 Service服务对应一个 Account帐号, 所以为多对一关系。 因此为 N方 Service 实体类添加 Account属性, 以及对应的 get/set方法。
//追加属性, 用于存储关联的 Account信息
privateAccount account;//已经包含 accountId了,原来的 accountId属性删!否则报错
u 注意事项: Service实体原来的 accountId属性删,相应的 get/set方法也删, Service
的映射文件对应的描述也删!否则报错: org.hibernate.MappingException: Repeated
column in mapping for entity: org.tarena.entity.Service column: ACCOUNT_ID
step3: 在 N方 Service.hbm.xml映射文件中描述 account属性
简单说明:
<many-to-one name="属性名" class="要关联的另一方类型 Account"
column="关联条件的外键字段"/> <!--指明外键字段,不写主键-->
u 注意事项:此时没有<setname="属性名"></set>标签。
具体实现:
<!--描述account,采用多对一关系加载-->
<many-to-one name="account" class="org.tarena.entity.Account"
column="ACCOUNT_ID"/> <!--指明外键字段,不写主键-->
step4: 借用5.17节4)中的 step1中的 HibernateUtil类
step5: 新建 TestManyToOne.java类用于测试
@Test
public void test1(){ Session session=HibernateUtil.getSession();
Service service=(Service)session.load(Service.class, 2002);
//System.out.println(service.getId());//结果为2002,但没去查数据库!主键传啥显示啥System.out.println(service.getOsUsername());//第一次 SQL查询
System.out.println(service.getUnixHost());
//查看账务账号的真实名字、身份证、 Account_ID
System.out.println(service.getAccount().getId());//第二次 SQL查询
System.out.println(service.getAccount().getRealName());
System.out.println(service.getAccount().getIdcardNo()); session.close();
}
6.3多对多关联映射 many-to-many
数据库设计是采用3张数据表,有一张是关系表。例如:
ADMIN_INFO-->ADMIN_ROLE<--ROLE
中间的关系表不用映射, 只映射两端的表。 但如何对关系表进行操作呢?
答: Hibernate会自动的通过已经映射的表, 进行关系表操作。u 注意事项:
v 多对多关系是默认的级联操作,可加 cascade属性,但是加了之后相当于进入
一个循环,若删除A数据,则所有表中有A的数据则都被删除!因此一般都是采用一对多或多对一, 从而破坏这个循环。 详情可看6.4节。
v 多对多关系一定有第三张表,间接实现多对多关系,两表之间不可能有多对多
关系!
案例1: step1: 在 Admin实体类中添加一个 Set集合属性
//追加属性, 用于存储相关联的 Role信息
private Set<Role> roles=new HashSet<Role>();
step2:在Admin.hbm.xml中定义属性的映射描述简单说明:
<set name="关联属性名" table="中间的关系表">
<key column="关系表中与当前一方关联的字段"></key>
<many-to-many class="关联的另一方类型"
column="关系表中与另一方关联的字段" />
</set>
具体实现:
<!--描述roles属性,采用多对多加载Role对象的数据-->
<set name="roles" table="ADMIN_ROLE_CHANG">
<key column="ADMIN_ID"></key>
<many-to-many class="org.tarena.entity.Role" column="ROLE_ID" />
</set>
step3:新建TestManyToMany类,用于测试
@Test
public void testFind(){//测试查询
Session session=HibernateUtil.getSession();
Admin admin=(Admin)session.get(Admin.class, 1001);
System.out.println(admin.getName()); System.out.println(admin.getEmail());
Set<Role> roles=admin.getRoles();//具有的角色
for(Rolerole:roles){ System.out.println(role.getId()+""+role.getName());
}
}
@Test
public void testAdd(){//测试添加管理员, 指定角色
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
Admin admin=newAdmin(); admin.setName("常1"); admin.setCode("chang1");
admin.setPassword("123123");
admin. setEnrollDate(new Date(System.currentTimeMillis()));
Role role1=(Role)session.load(Role.class, 20);//追加角色, 角色 ID为20
Role role2=(Role)session.load(Role.class, 24);//追加角色, 角色 ID为24
admin.getRoles().add(role1); admin.getRoles().add(role2);//把角色加入集合中
session.save(admin); tx.commit(); session.close();
}
@Test
public void testDelete(){ Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Admin admin=(Admin)session.get(Admin.class, 23);//查找 ID为23的管理员
Role role1=(Role)session.get(Role.class,2);//查找 ID为2的角色
admin.getRoles().remove(role1);//取消该管理员 ID为2的角色
//增加角色 admin.getRoles().add(role1);//和上个方法相同
session.update(admin);//更新admin tx.commit(); session.close();
}
案例2: step1: 在 Role实体类中添加一个 Set集合属性
//追加属性, 用于存储 admin信息
private Set<Admin> admins=new HashSet<Admin>();
step2:在Role.hbm.xml中定义属性的映射描述
<!--采用多对多加载 admin信息-->
<set name="admins" table="ADMIN_ROLE_CHANG">
<key column="ROLE_ID"></key><!--与 admin.hbm.xml是相反的-->
<many-to-many column="ADMIN_ID" class="org.tarena.entity.Admin">
</many-to-many>
</set>
step3:在 TestManyToMany类中添加方法,用于测试
@Test
public void testFindRole(){//根据 role查询相关 admin
Session session=HibernateUtil.getSession(); Role role=(Role)session.load(Role.class, 1);
System.out.println(role.getName());//查找ID为1的角色,然后显示名称
for(Admin admin:role.getAdmins()){//显示哪些 admin具有此角色
System.out.println(admin.getId()+" "+admin.getCode()+" "+admin.getName());
} session.close(); }
6.4关联操作(查询 join fetch/级联 cascade)
1)查询操作:建立关联映射后,默认情况下在调用关联属性的 getter方法时,会再发送
一个 SQL加载关系表数据。如果需要将关联数据与主对象一起加载(两个 SQL查询合成一个 SQL查询), 可以采用下面的方法:
①在 hbm.xml关联属性映射描述中(下例是在 Account.hbm.xml中),使用 lazy="false"
fetch="join"(不推荐使用!影响面太广)
<!--关联属性的 lazy属性默认为 true, 主属性默认为 false, 主属性也可加 lazy属性-->
<!-- <set name="services" lazy="false" fetch="join">, lazy="false"关闭了延迟操作,与主对象一起实例化。 fetch默认 select: 单独发送一个 SQL查询。 join: 表连接用一个 SQL查询。
不推荐用因为影响的映射范围太广, 推荐使用 HQL-->
<set name="services" lazy="false" fetch="join">
<key column="ACCOUNT_ID"></key><!--ACCOUNT_ID是 Service表中字段-->
<one-to-many class="org.tarena.entity.Service"/>
</set>
②编写 HQL, 采用 join fetch关联属性方式实现。 (推荐使用!)
@Test
/**我们期望: 当执行(Account)session.get(Account.class, 1001);语句, 取出 Account后,在属性 services已经填充了所有的服务项 service */
public void test1(){ Session session=HibernateUtil.getSession();
Account account=(Account)session.get(Account.class, 101 1);
session.close();//当 hbm.xml中关联属性设置了 lazy="false", 在这里关闭能正常执行Set<Service> services=account.getServices();//若 lazy="true"默认值, 则报错
for(Service s: services) {
System.out.println(s.getId()+" "+s.getOsUsername()+" "+s.getUnixHost());
}
System.out.println(account.getRealName());
}
@Test /**TestOneToMany中添加方法*/
public void test2(){ Session session=HibernateUtil.getSession();
//String hql="fromAccount where id=?";//与 TestOneToMany中 test1效果一样
//在下面的 hql中把需要关联的属性写出来, 效果与在 hbm.xml加 fetch的效果一样
String hql="fromAccount a join fetch a.services where a.id=?";//只执行一次 SQL查询
Query query=session.createQuery(hql);
query.setInteger(0, 1011); Account account=(Account)query.uniqueResult();
System.out.println(account.getRealName()); System.out.println(account.getIdcardNo());
Set<Service> services=account.getServices();
for(Service s: services) {
System.out.println(s.getId()+" "+s.getOsUsername()+" "+s.getUnixHost());
}
session.close();
}
@Test /**TestManyToOne中添加方法*/
public void test2(){ Session session=HibernateUtil.getSession();
String hql="from Service s join fetch s.account where s.id=?";//只执行一次 SQL查询
Query query=session.createQuery(hql);
query.setInteger(0, 2002);//Hibernate设置问号从 0开始
Service service=(Service)query.uniqueResult();
System.out.println(service.getOsUsername()); System.out.println(service.getUnixHost());
//查看账务账号的真实名字、身份证、 Account_ID
System.out.println(service.getAccount().getId());
System.out.println(service.getAccount().getRealName());
System.out.println(service.getAccount().getIdcardNo()); session.close();
}
2)级联操作
当对主对象增删改时, 可以对关系属性中的数据也相应的执行增删改。
例如: session.delete(account);当 account中有 services且 services有值,则删除 account
时, 相关联的 services也被删除。
级联操作执行过程:首先级联操作要开启,然后判断级联属性是否有数据,若无数
据则没有级联操作,若有数据则看是否有更改,有更改才有级联操作。
级联操作默认是关闭的, 如果需要使用, 可以在关联属性映射部分添加 cascade属
性,属性值有:①none:默认值,不支持级联。②delete:级联删除。③save-update:级联添加和更新④All:级联添加、删除、更新„„等。案例:级联增加:
step1: 修改 Account.hbm.xml:
<set name="services" cascade="all">
<key column="ACCOUNT_ID"></key>
<one-to-many class="org.tarena.entity.Service"/>
</set>
step2:新建TestCascade类,用于测试级联操作
@Test
public void testAdd(){//采用级联方式添加一个 Account和两个 Service
Account account=newAccount();//一个 Account, 简单操作: 只把非空列设置上
account.setLoginName("chang"); account.setLoginPasswd("123");
account.setRealName("常"); account.setIdcardNo("1234567890");
account.setTelephone(" 123456789");
Service service1=new Service();//两个 Service, 简单操作: 只把非空列设置上
service1.setAccount(account);//因 accountId被删了,所以这里用 account,它里面有 id
service1 .setOsUsername("chang1 "); service1 .setLoginPassword(" 1 1 1 ");
service1 .setUnixHost(" 1 92. 168.0.20"); service1 .setCostId(1);
Service service2=new Service();//同理
service2.setAccount(account); service2.setOsUsername("chang2");
service2.setLoginPassword("222"); service2.setUnixHost(" 192. 168.0.23");
service2.setCostId(2);
/**将 serivce1和 service2添加到 account.services集合中,否则不会级联添加这两个service, 同时 Hibernate会检测,新增数据若是 services中的原有的, 则不往数据库添加*/
account.getServices().add(service1); account.getServices().add(service2);
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
//hbm.xml添加 cascade="all", 则会对 account.service中的数据执行级联添加
session.save(account); tx.commit(); session.close(); }
3) inverse属性作用
默认情况下,采用了级联操作, Hibernate在执行 insert、 update、 deleted基本操作后,
还要执行 update关系字段的操作(即关系维护工作, 上例中维护的为 ACCOUNT_CHANG表中的 ID和 SERVICE_CHANG表中的 ACCOUNT_ID)。
默认是关联对象双方都要负责关系维护。 所以在上例中, 控制台在最后会有两个
update语句, 因为当前添加了一个 Account和两个 Service, 所以 One方要维护两个 Service,即两个 update语句。 如果数据量很大, 则要维护 N个 Service, 则有 N个 updata语句, 此时就会影响性能。
为了使 update语句不出现, 可以在 Account.hbm.xml中的级联属性加 inverse="true"
属性,即当前一方放弃关系维护,将这项工作交给对方负责。
例如: <set name="services" inverse="true" cascade="all">...</set>
u 注意事项:遇到一对多、多对一关系映射时,把 inverse="true"属性加到
one-to-many一方 (One方放弃, Many方维护)。 能起到一定的优化作用。
4)级联删除
在 TestCascade类中添加方法:
@Test
public void testDelete(){
/**Accountaccount=newAccount(); account.setId(id); 级联删除,不要采用
newAccount()方法,因为 new出来的 account,它的 services是空的,那么将是单表操作,
将报错:违反完整性约束*/
Session session=HibernateUtil.getSession(); Transaction tx=session.beginTransaction();
Account account=(Account)session.load(Account.class, 500);//应该先查找
session.delete(account);//再删除 tx.commit(); session.close();
}
Hibernate级联删除的缺点: delete是按 id(主键)一条一条删的,不是按关系字段
删的, 当数据量小时可用 Hibernate的级联删除, 简单方便些。
但是,但当数据量大时, Hibernate的级联删除效率低,则不建议使用 Hibernate的
级联删除, 建议采用 HQL语句的方式, 例如:
delete fromAccount where id=?
delete from Service where account.id=?
u 注意事项:
v 级联删除,不写 inverse="true",且数据库中 SERVICE_CHANG表中的
ACCOUNT_ID为 NOT NULL约束, 那么程序最后会执行 update, 会设置ACCOUNT_ID=null,那么将与数据库冲突!报错!所以,应当加上inverse="true"。
6.5继承关系映射
可以将数据表映射成具有继承关系的实体类。 Hibernate提供了3方式的继承映射。
1)将一个表映射成父类和子类: 采用<subclass>描述子类。
2)将子类表映射成父类和子类(无父类表):采用<union-subclass>描述。
3) 将父类表和子类表映射成父类和子类: 采用<joined-subclass>描述子类继承关系映射。
<joined-subclass name="子类类型" table="子类表" extends="父类类型">
<key column="子类表与父类表关联的字段"></key>
//子类中其他属性的映射 property元素
</joined-subclass>
4)案例:将父类表和子类表映射成父类和子类
step1: PRODUCT表为父表, CAR表和 BOOK表都为子表。 建表语句如下:
CREATE TABLE PRODUCT(
ID NUMBER(5) CONSTRAINT PRODUCT_ID_PK PRIMARY KEY,
NAME VARCHAR2(20),
PRICE NUMBER(15,2),
PRODUCT_PIC VARCHAR2(100) );
CREATE SEQUENCE product_seq;
CREATE TABLE BOOK(
ID NUMBER(5) CONSTRAINT BOOK_ID_PK PRIMARY KEY,
AUTHOR VARCHAR2(20),
PUBLISHING VARCHAR2(50),
WORD_NUMBER VARCHAR2(20),
TOTAL_PAGEVARCHAR2(20) );
CREATE TABLE CAR(
ID NUMBER(5) CONSTRAINT CAR_ID_PK PRIMARY KEY,
BRAND VARCHAR2(20),
TYPE VARCHAR2( 1 ),
COLOR VARCHAR2(50),
DISPLACEMENTVARCHAR2(20) );
u 注意事项:父表即把子表中相同的字段提取出来,作为父表。如:书和汽车都
有ID、名字、价格、产品图片。
step2: 创建实体类 Product、 Book和 Car, 其中 Book和 Car类需要继承 Product。
例如: public class Book extends Product{ ...}、 public class Car extends Product{ ...}
step3:添加映射文件: Product.hbm.xml、 Book.hbm.xml、 Car.hbm.xml
1) Product.hbm.xml
<hibernate-mapping>
<class name="org.tarena.entity.Product" table="PRODUCT">
<id name="id" type="integer" column="ID">
<generatorclass="sequence"><!--指定序列-->
<param name="sequence">PRODUCT_SEQ</param>
</generator>
</id>
<property name="name" type="string" column="NAME"></property> „„其他部分略
2) Book.hbm.xml
<hibernate-mapping><!--描述了 Book与 Product的描述信息-->
<!--name:指明当前子类。 table:哪个表。 extends:继承哪个父类。 -->
<joined-subclassname="org.tarena.entity.Book" table="BOOK"
extends="org.tarena.entity.Product">
<key column="ID"></key><!-- BOOK表中哪个字段与 PRODUCT表关联 -->
<!-- 这里不自动增长, Hibernate会自动的把 Product中的主键值拿过来-->
<property name="author" type="string" column="AUTHOR"></property>
„„其他部分略
3) Car.hbm.xml
<hibernate-mapping><!--描述了 Book与 Product的描述信息-->
<joined-subclass name="org.tarena.entity.Car" table="CAR"
extends="org.tarena.entity.Product">
<key column="ID"></key><!--CAR表中哪个字段与 PRODUCT表关联 -->
<!-- 这里不自动增长, Hibernate会自动的把 Product中的主键值拿过来-->
<property name="brand" type="string" column="BRAND"></property>
„„其他部分略
step4:创建TestExtends类,用于测试继承关系映射
@Test
public void testAddBook(){ Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction(); Book book=new Book();
book.setName("常的书");//设置 product属性 book.setPrice(50);
book.setProductPic("a.jsp");
book.setAuthor("常");//设置 book属性 book.setPublishing("BO出版社");
book.setTotalPage("20"); book.setWordNumber("10000");
session.save(book);//执行保存 tx.commit(); session.close();
}
@Test
public void testFindBook(){ Session session=HibernateUtil.getSession();
Bookbook=(Book)session.load(Book.class, 1); System.out.println(book.getName());
System.out.println(book.getPrice()); System.out.println(book.getAuthor());
System.out.println(book.getPublishing()); session.close();
}
@Test
public void testDeleteBook(){ Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Book book=(Book)session.get(Book.class, 3); session.delete(book);
tx.commit(); session.close();
}
@Test
public void testAddCar(){ Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
Car car=new Car();//product信息 car.setName("Q7"); car.setPrice(800000);
car.setProductPic("b.jsp");
car.setBrand("奥迪");//car信息 car.setType("J");//J轿车 K卡车
car.setColor("黑色"); car.setDisplacement("3.0");//排量
session.save(car);//执行保存 tx.commit(); session.close();
}
@Test
public void testFindAllBook(){ Session session=HibernateUtil.getSession();
String hql="from Book";//from car为所有汽车, from product为所有商品
Query query=session.createQuery(hql); List<Book> books=query.list();
for(Bookbook:books){ System.out.println(book.getId()+" "+book.getName());}
}
七、 Hibernate查询方法
7.1 HQL查询
Hibernate Query Language简称 HQL。
HQL语句是面向对象的一种查询语言。 HQL针对 Hibernate映射之后的实体类型和属性进行查询 (若出现表名和字段名则为错误的!)。
7.2 HQL和 SQL的相同点
1)都支持 select、 from、 where、 groupby、 orderby、 having子句„„。
2)都支持+、-、*、/、>、<、>=、<=、<>等运算符和表达式。
3)都支持in、 notin、 between...and、 isnull、 isnotnull、 like、 or等过滤条件。4)都支持分组统计函数count、 max、 min、 avg、 sum。
7.3 HQL和 SQL的不同点
1) HQL区分大小写(除了关键字外)。
2) HQL使用类名和属性名,不能使用表名和字段名。3) HQL不能使用 select*写法。
4) HQL不能使用 join...on中的 on子句。
5) HQL不能使用数据库端的函数。
u 注意事项: HQL中 selectcount(*)可以使用。
7.4 HQL典型案例
1)案例1:一个主键的情况
step1:借用之前的Account实体、 Account.hbm.xml、 hibernate.cfg.xml
step2:新建TestHQL类,用于测试HQL。查询操作可不写事务控制语句。
@Test //SQL: select*fromACCOUNT_CHANG
public void test1(){//查询所有账务账号信息 String hql="fromAccount";
Sessionsession=HibernateUtil.getSession(); Query query=session.createQuery(hql);
List<Account> list=query.list();//如果查询出多条结果
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
@Test //SQL: select* fromACCOUNT_CHANG where REAL_NAME like?
public void test2() {//按真名模糊查询
//多个条件也可继续加 and XX=? or XX=?
String hql="fromAccount where realName like?";//方式一
//String hql="fromAccount where realName like:n";//方式二
Session session=HibernateUtil.getSession(); Query query=session.createQuery(hql);
query.setString(0, "zhang%");//方式一: 设置查询参数, 从 0开始表示第一个?
//query.setString("n", "zhang%");//方式二: 给:n赋值, 就不用数问号是第几个了
//zhang_表示以 zhang开头的两个字名字
List<Account> list=query.list();//如果查询出多条结果
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo());
}
session.close();
}
@Test //SQL: select ID,REAL_NAME,IDCARD_NO fromACCOUNT_CHANG
public void test3(){//查询部分字段方式一
String hql="select id,realName,idcardNo fromAccount";
Session session=HibernateUtil.getSession(); Query query=session.createQuery(hql);
/**部分查询,默认采用 Object[]封装一行记录的字段值,数组的大小、顺序和写的 HQL 属性的个数、顺序一致!注意事项:只要是单独列出的属性,则返回的就是Object数组!*/
List<Object[]> list=query.list();
for(Object[] objs:list){//若写成原实体 Account则报错类型转换异常
System.out.println(objs[0]+" "+objs[1]+" "+objs[2]);
}
session.close();
}
@Test //SQL: select ID,REAL_NAME,IDCARD_NO fromACCOUNT_CHANG
public void test4(){//查询部分字段方式二
String hql="select newAccount(id,realName,idcardNo) fromAccount";
/**为了支持它,需要在 Account实体中加构造方法,无参的也加上(否则影响其他地方的使用)。或者写个新的实体类也可以。 */
Session session=HibernateUtil.getSession(); Query query=session.createQuery(hql);
//部分查询, 采用指定的 Account的构造方法封装一行记录的字段值
List<Account> list=query.list();
for(Account a:list){//注意: 显示其他属性将会是初始值
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
step3: Account实体中加构造方法和无参构造方法
public Account() { }
public Account(Integer id,String realName,String idcardNo){
this.id=id; this.realName=realName; this.idcardNo=idcardNo;
}
step4:在Account.hbm.xml中添加 HQL语句, step5中会用到
<class name="org.tarena.entity.Account" table="ACCOUNT_CHANG" ></class>
<!--和 class是平级的! 一个 query标签写一个 HQL语句-->
<queryname="findAll"><!--起个名字-->
<! [CDATA[from Account]]><! --怕特殊符号影响语句,放 CDATA段中作为纯文本-->
</query>
step5:其他测试
@Test
public void test5(){//将 HQL定义到 hbm.xml中
Session session=HibernateUtil.getSession();
//session.getNamedQuery()方法,会去 hbm.xml中找 HQL语句
Query query=session.getNamedQuery("findAll");
List<Account> list=query.list();//如果查询出多条结果
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
@Test
public void test6(){//分页查询
String hql="fromAccount"; Session session=HibernateUtil.getSession();
Query query=session.createQuery(hql);
//设置分页参数,就会按分页形式查询
query.setFirstResult(0);
/**设置抓取记录的起点(每页的第一条记录), 0代表第一条“记录”,不是页数*/
query.setMaxResults(5);//设置最大抓取数量
List<Account> list=query.list();//如果查询出多条结果
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
@Test
/** SQL: select s.ID,s.OS_USERNAME,s.UNIX_HOST,a.REAL_NAME,a.IDCARD_NO
from SERVICE_CHANG s join ACCOUNT_CHANG a on(a.ID=s.ACCOUNT_ID) */
public void test7(){//对象关联查询
String hql="";//只要是单独列出的属性则返回的就是 object数组!
//hql+="selects.id,s.osUsername,s.unixHost,a.realName,a.idcardNo";/**方式一*/
//hql+="from Service sjoin s.account a";//不能写 on子句, 多对一
//hql+="fromAccount a join a.services s";//或反过来, 一对多
/**方式二:一定要有“属性”才能"."点出来,若属性是集合、数组,则它们里面
没有其他属性,不能“.”出来*/
hql+="select s.id,s.osUsername,s.unixHost, s.account.realName,s.account.idcardNo";
hql+="from Service s";
//因为不能写 on子句, 再加上 Service中有 account属性, 所以关联属性写 s.account
Session session=HibernateUtil.getSession(); Query query=session.createQuery(hql);
List<Object[]> list=query.list();
for(Object[] objs:list){ System.out.println(objs[0]+" "+objs[1]+" "+objs[2]+" "
+objs[3]+""+objs[4]); }
session.close();
}
2)案例2:联合主键的情况
step1: 创建 PERSON表
CREATE TABLE PERSON(
FIRST_NAME VARCHAR2(20), LAST_NAME VARCHAR2(20), AGE NUMBER);
ALTER TABLE PERSONADD CONSTRAINT PERSON_KEY
PRIMARY KEY(FIRS T_NAME,LAS T_NAME);
step2:1)创建Person实体, Hibernate要求联合主键要再封装
//private String firstName; private String lastName;
private PersonKey id;//主属性
private Integer age; „„get/set方法
2) 创建 PersonKey实体, 用作 Person实体的联合主键
/**必须实现 Serializable否则 load、 get方法不能调用了,因为它们的第二个参数是Serializable类型*/
public class PersonKey implements Serializable{
private String firstName; private String lastName; „„get/set方法
step3: 添加 Person.hbm.xml映射文件
<class name="org.tarena.entity.Person" table="PERSON">
<!--联合主键-->
<composite-id name="id" class="org.tarena.entity.PersonKey">
<!--主键自动生成这里就不适合了,要通过程序操作-->
<key-property name="firstName" type="string" column="FIRST_NAME">
</key-property>
<key-property name="lastName" type="string" column="LAST_NAME">
</key-property>
</composite-id>
<property name="age" type="integer" column="AGE"></property>
</class>
7.5 Criteria查询
1)基本使用方式:
Criteria c=session.createCriteria(实体类.class); List list=c.list();
u 注意事项:分组、太复杂的语句用不了。
2)案例:创建TestCriteria类,用于测试Criteria查询(借助以前的实体和映射)@Test
public void test1(){//没有任何子句 Session session=HibernateUtil.getSession();
Criteria c=session.createCriteria(Account.class); List<Account> list=c.list();
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
@Test
public void test2(){//模糊查询 Session session=HibernateUtil.getSession();
Criteria c=session.createCriteria(Account.class);
//Criteria c1 =session.createCriteria(Service.class);//可以有第二个表
//追加条件,都被封装在了 Restrictions中
c.add(Restrictions.like("realName", "zhang%")); List<Account> list=c.list();
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo()); }
session.close();
}
@Test
public void test3(){//追加两个条件
Session session=HibernateUtil.getSession();
Criteria c=session.createCriteria(Account.class);
//c.add(Restrictions.like("realName", "zhang%"));
c.add(//当条件多时, 就比较麻烦了
Restrictions.and( Restrictions.like("realName","zhang%"),
Restrictions.eq("idcardNo", "410381194302256528")) );
c.addOrder(Order.desc("id"));//追加排序 List<Account>list=c.list();
for(Account a:list) {
System.out.println(a.getId()+" "+a.getRealName()+" "+a.getIdcardNo());
}
session.close();
7.6 Native SQL原生 SQL查询
1) 基本使用:
SQLQuery query=session.createSQLQuery(sql);
List<Object[]> list=query.list();//默认封装成 Object数组
u 注意事项:一些特殊的函数 Hibernate无法执行需使用原生 SQL,极其复杂的
操作也可用原生 SQL。
2)案例:创建 TestSQLQuery类,用于测试原生 SQL查询(同样借助以前的实体和映射)
@Test
public void test1(){//没有用到映射文件
String sql="select* fromACCOUNT_CHANG";
Session session=HibernateUtil.getSession();
SQLQuery query=session.createSQLQuery(sql);
query.setFirstResult(0);//分页查询 query.setMaxResults(5);
List<Object[]> list=query.list();
for(Object[]objs:list){ System.out.println(objs[0]+""+objs[1]+""+objs[2]); }
session.close();
@Test
public void test2(){//改变 test1中的封装类型
String sql="select* fromACCOUNT_CHANG";
Session session=HibernateUtil.getSession();
SQLQuery query=session.createSQLQuery(sql);
/**改变封装类型,利用该类型映射(映射描述将起作用),封装一条记录(全字段
的,部分字段不行) */
query.addEntity(Account.class); List<Account>list=query.list();
for(Accounta:list){ System.out.println(a.getId()+""+a.getRealName()); }
session.close();
}
八、 Hibernate高级特性
8.1二级缓存
二级缓存是 SessionFactory级别的。 由 SessionFactory对象负责管理。通过 Factory创建的 Session都可以访问二级缓存。
二级缓存默认是关闭的。如果二级缓存打开,则先去一级缓存找对象,找不到则去二级缓存, 还找不到则访问数据库。
u 注意事项:
v 一级缓存和二级缓存都是存“单个对象”的!不能存集合、数组!
v Hibernate本身没有提供组件,需要第三方提供的组件。有很多第三方组件,这
里用 ehcache-1.2.3.jar。
8.2 二级缓存开启方法及测试
step1: 引入 ehcache-1.2.3.jar, 在 src下添加 ehcache.xml配置文件
ehcache.xml配置文件说明:
<diskStore path="java.io.tmpdir"/><!--磁盘存储路径-->
<defaultCache <!--默认参数设置-->
maxElementsInMemory="2000" <! --存储的最大对象个数-->
eternal="false" <!--缓存对象的有效期, true为永久存在-->
timeToIdleSeconds="20" <!--空闲时间:某个对象空闲超过20秒则清出二级缓存-->
timeToLiveSeconds="120" <!--某个对象生存了120秒,则自动清出二级缓存-->
overflowToDisk="true"<! --当存储个数超出设置的最大值时, 把超出对象存到磁盘-->
/>
step2:在hibernate.cfg.xml中添加开启配置参数,指定缓存类型
<!--开启二级缓存-->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!--指定二级缓存组件类型, 类似于 JDBC中不同的数据库驱动类型-->
<property name="hibernate.cache.provider_class">
net.sf.ehcache.hibernate.EhCacheProvider
</property><!--在 ehcache-1.2.3.jar中 net.sf.ehcache.hibernate下找-->
step3:在需要缓存的实体类Account.hbm.xml中,添加
<cache usage="read-only" region="采用 ehcache.xml中哪组参数缓存"/>
<class name="org.tarena.entity.Account" table="ACCOUNT_CHANG">
<!--read-only:只读。 read-write:读写。 region:指明用哪组参数缓存-->
<cache usage="read-only" region="sampleCache1"/>
<id name="id" type="integer" column="ID"></id>
„„其他部分略
step4:创建TestSecondCache类,用于测试二级缓存
@Test
public void test1(){//查询一次, 一级缓存的作用
Session session=HibernateUtil.getSession();
Account account=(Account)session.load(Account.class, 1010);
System.out.println(account.getRealName()); System.out.println(account.getIdcardNo());
Account account1=(Account)session.get(Account.class, 1010);
System.out.println(account1.getEmail()); session.close();
}
@Test
public void test2(){//若没有开启二级缓存, 则查询二次, 因为是不同的 Session对象
test1(); System.out.println("-------"); test1();//开启二级缓存后,只查询一次 }
8.3二级缓存管理方法
1) SessionFactory.evict(class);//清除某一类型的对象2) SessionFactory.evict(class,id);//清除某一个对象
3) SessionFactory.evict(list);//清除指定的集合
8.4 二级缓存的使用环境
1)共享数据,数据量不大。
2) 该数据更新频率低 (一更新就涉及到同步, 就要有性能开销了)。
8.5查询缓存
一级和二级缓存只能缓存单个对象。对于其他类型的数据,例如:一组字段或一组对象集合、数组都不能缓存。这种特殊结果,可以采用查询缓存存储。查询缓存默认是关闭的!
8.6 查询缓存开启方法及测试
step1: 开启查询对象的二级缓存 (因为也是跨 Session的)。
step2: 在 hibernate.cfg.xml中设置开启查询缓存参数。
<!--开启查询缓存-->
<property name="hibernate.cache.use_query_cache">true</property>
step3:创建 TestQueryCache类,用于测试查询缓存,并在执行 query.list()方法前,设置query.setCacheable(true);
@Test
public void test1(){ //当传入的参数相同时, 只执行一次查询。 不同时执行两次查询
show("zhang%"); System.out.println("-------"); show("zhang%");//一次查询 }
private void show(String name){
String hql="from Account where realName like?";
/**看 SQL不看HQL, SQL相同则从查询缓存中取,不一样则访问数据库查询*/
Session session=HibernateUtil.getSession(); Query query=session.createQuery(hql);
query.setString(0, name);
/**采用查询缓存机制进行查询(在开启二级缓存的基础上)!去缓存查找,执行过
此次SQL,将结果集返回。未执行过,去数据库查询,并将SQL和结果存入缓存*/
query.setCacheable(true); List<Account>list=query.list();//执行查询
for(Accounta:list){ System.out.println(a.getId()+" "+a.getRealName()); }
session.close(); }
8.7 查询缓存的使用环境
1)共享数据的结果集,结果集数据量不应太大(几十到几百条即可)。
2)查询的结果集数据变化非常小(最好不要变化,几天变一次还可接受,先清原来的缓存再重新载入)。
九、 Hibernate锁机制
Hibernate提供了乐观锁和悲观锁机制, 主要用于解决事务并发问题。
9.1悲观锁
Hibernate认为任何操作都可能发生并发,因此在第一个线程查询数据时,就把该条记录锁住。 此时其他线程对该记录不能做任何操作 (即增删改查四种操作都不能)。 必须等当前线程事务结束才可以进行操作。
9.2 悲观锁的实现原理
Hibernate 悲观锁机制实际上是采用数据库的锁机制实现。
数据库中 SQL语句最后加 for update则把记录直接锁死, 其他用户增删改查都不行, 只能等待: select* from TRAIN where id=1 for update;
Hibernate中 load重载方法: session.load(Train.class,1,LockMode.UPDATE);只能等待当前用户提交或回滚, 若等待超时则报异常!
悲观锁的缺点: 处理效率很低。
9.3 悲观锁使用步骤及测试
step1:创建表 TRAIN(火车)
CREATE TABLE TRAIN(
ID NUMBER PRIMARY KEY, T_START VARCHAR2(20),
T_ENDVARCHAR2(20), T_TICKETNUMBER );
INSERT INTO TRAIN VALUES( 1 ,‘beij ing‘,‘shanghai‘, 1 00);
step2: 创建 Train实体类
private int id; private String start; private String end; private int ticket; „„get/set step3: 添加 Train.hbm.xml映射文件
<class name="org.tarena.entity.Train" table="TRAIN" >
<id name="id" type="integer" column="ID"></id>
<property name="start" type="string" column="T_START"></property>
<property name="end" type="string" column="T_END"></property>
<property name="ticket" type="integer" column="T_TICKET"></property>
</class>
step4:创建 ThreadClient类,用于模拟一个用户操作
public class ThreadClient extends Thread{//继承 Thread
public void run(){//模拟购票操作
Session session=HibernateUtil.getSession();
Transaction tx=session.beginTransaction();
//Train train=(Train)session.load(Train.class, 1);//不加锁时, 查询出火车信息
Train train=(Train)session.load(Train.class,1 ,LockMode.UPGRADE);//设置悲观锁
if(train.getTicket()>= 1 ) {//判断剩余票数>=购买票数
try{//满足购票条件,进行购票操作
Thread.sleep(2000);//模拟用户操作
} catch(InterruptedExceptione) { e.printStackTrace(); }
int ticket=train.getTicket()- 1 ;//将票数更新
train.setTicket(ticket); System.out.println("购票成功!");
}else{ System.out.println("票数不足,购买失败!"); }
tx.commit();//持久对象, 提交就自动同步, 相当于执行了 update
session.close(); } }
step5:创建TestTrain类,用于模拟并发操作
public static void main(String[] args) {
ThreadClient c1=new ThreadClient(); c1.start();
ThreadClient c2=new ThreadClient(); c2.start();
/**若 ThreadClient类为无锁查询,则显示2个购买成功,但数据库却减少1张票。若
ThreadClient类加了悲观锁, 则显示2个购买成功, 数据库减少2张票。 }
9.4乐观锁
认为发生并发几率非常小。 相同的记录不同的用户都可以查询访问, 当多个人都要修改该记录时,只有第一个提交的用户成功,其他的会抛出异常,提示失败!
9.5 乐观锁的实现原理
乐观锁机制是借助于一个“版本”字段实现,当第一个更新用户提交成功后, Hibernate
会自动将该“版本”字段值+1,当其他用户提交,如果版本字段小于数据库中的值,则会抛出异常,提示失败。如果不使用框架技术,那么我们需要手工做对比,使用 Hibernate框架后,Hibernate可以帮助我们做 version对比的操作。
9.6乐观锁使用步骤及测试
step1: 向 TRAIN表中添加一个 T_VERSION版本字段
ALTER TABLE TRAIN ADD T_VERSION NUMBER;
step2: 在 Train实体类中添加 version属性, 以及对应的 get/set方法
private int version;//版本属性
step3:在 Train.hbm.xml中定义版本字段映射
简单说明:
<class name="org.tarena.entity.Train" table="TRAIN" optimistic-lock="version">
<!--采用“版本”机制,不写也可,默认是version-->
<id name="" type="" column=""></id>
<version name="属性名" type="类型" column="字段名"></version>
具体实现:
<class name="org.tarena.entity.Train" table="TRAIN" optimistic-lock="version">
<id name="id" type="integer" column="ID"></id>
<!--定义乐观锁的版本字段,注意顺序-->
<version name="version" type="integer" column="T_VERSION"></version>
<property name=" start" type=" string" column="T_S TART"></property>
step4: 将9.3节 step4中的 ThreadClient类, 改为不加锁的 load方法
Train train=(Train)session.load(Train.class, 1);
step5: 再次执行9.3节 step5中的 TestTrain类
执行结果:先提交的事务执行成功,后提交的事务执行失败,报错信息为:
StaleObjectStateException: Row was updated or deleted by another transaction
十、其他注意事项
10.1源码服务器管理工具
今后工作中会使用到的源码服务器 (或叫版本服务器) 管理工具:
1) CVS常用乐观锁机制 2) SVN常用乐观锁机制
3) VSS用的少悲观锁机制
10.2利用 MyEclipse根据数据表自动生成实体类、 hbm.xml
step1: 进入 DB Browser, 建立一个与数据库的连接
step2: 新建工程, 右键工程-->MyEclipse-->Add Hibernate Capbilities
step3: 弹出添加 Hibernate开发环境界面:
第一个界面选择 Hibernate版本, 然后点 Next;
u 注意事项: 第一个界面中 Select the libraries to add to the buildpath是选择要导入的
Hibernate的 Jar包,有两种选择: MyEclipse自带的“MyEcipse Libraries”,还有自
己导入的“User Libraries”,如果已经手动将所有 Jar包拷贝到了 lib下, 不用再导入
了。那么我们都不选,去掉“MyEcipseLibraries”前面的 checkbox的对勾。
第二个界面添加 hibernate.cfg.xml主配置文件(可默认), 然后点 Next;
第三个界面在 DB Driver下拉菜单中选择第一步建立的连接, 然后点 Next;
第四个界面创建 HibernateSessionFactory类, 其实就是我们写的 HibernateUtil, 然后点击
Finish。
u 注意事项:主配置文件中:
v 对于MySql连接,连接字符串中如若有&符号,需要写成&
v <propertyname="myeclipse.connection.profile">
oracle.jdbc.driver.OracleDriver</property>为链接名, 可以删掉。
step4:在工程中,新建一个package,用于存放实体和hbm.xml
step5: 进入 DB Browser选中需要生成的数据表, 右键选择 Hibernate Reverse Engineering...
第一个界面选择生成 hbm.xml和 POJO(实体类), 及其存放路径, 然后点 Next;
第二个界面选择 Type Mapping为 Hibernat types (其他设置可默认), 然后点 Next;
第三个界面选择数据表,可以设定映射的POJO类名(包名.类名)和主键生成方式,选择字段可以设置属性名和映射类型 (要改, 否则不符合 Java命名规范), 最后点击 Finish。
u 注意事项:第一个界面有个Createabstractclass,创建抽象类。意思为:
public class Foo extends AbstractFoo implements java.io.Serializable{
//里面为构造方法, 没有属性和 getter/setter方法
public abstract class AbstractFoo implements java.io.Serializable{
//里面为属性和 getter/setter方法
step6:完成后,实体类、 hbm.xml和hibernate.cfg.xml都已生成、修改好了。
u 注意事项:
v Hibernate生成的映射文件会有一些问题, 最好再修改一下。
v 可以按“Ctrl”键选择多个表,之后步骤相同,可以同时创建多个表的 POJO类
和映射文件。
10.3根据实体类和 hbm.xml生成数据表
利用 Hibernate框架自带的 hbm2ddl工具, 根据实体类和 hbm.xml生成数据表。step1: 在 hibernate.cfg.xml中添加开启工具的设置
<!--根据实体类和 hbm.xml生成数据表-->
<property name="hbm2ddl.auto">update</property>
step2:在执行添加、查询等操作时,会自动创建数据表,然后再执行操作。
10.4 Hibernate中分页查询使用 join fatch的缺点
使用 Hibernate分页查询时, 若语句中使用了 join fatch语句, 则由“假分页”机制实现。
实际采用可滚动 ResultSet游标实现的数据抓取。 最后的显示结果一样, 但是 SQL语句不同。
假分页 SQL语句: select* from bill, 返回大量数据, 然后利用游标 result.absolute(begin); 即跳着查询, 而 result.next();为下一条记录。
真分页 SQL语句: MySql: select* from bill limit?,?
Oracle: select... (select... rownum<?) where rownum>?
那么假分页的结果就是,一次性把数据全部取出来放在缓存中,比较适合小数据量,如果数据量大, 对内存压力比较大。
所以, 建议 join fatch语句不要和分页查询一起用!
“假分页”详情可看 JDBC笔记9.5节。
10.5 Hibernate的子查询映射
1) 在映射文件中使用如下格式:
<property name="属性名" type="映射类型" formula="(子查询语句)"></property>
在对当前对象查询时, Hibernate 会将子查询执行结果给指定的属性赋值。
2) formula使用注意事项:
①必须将子查询语句用括号括起来。
②子查询语句必须是 SQL语句。
③子查询中使用的表必须用别名 (在查询条件中没有别名的字段都默认是当前映射
实体类的字段)。
④当使用了子查询映射后,如 HQL语句: from Host,默认查询所有字段和子查询
结果。如果只需要部分字段值,不需要子查询结果,可以采用 select单独指定需要的字段属性。
3)案例: 对于 NetCTOSS项目中的每台服务器资费使用量的查询
step1: 在实体类 Host中添加三个属性, 并设置 set/get方法
private int id; private String name; private String location;
private Integer c1;//追加属性, 用于存储包月使用数量
private Integer c2;//追加属性, 用于存储套餐使用数量
private Integer c3;//追加属性, 用于存储计时使用数量
step2: 在映射文件 Host.hbm.xml中添加这三个属性的描述(采用子查询形式)
<!--采用子查询映射将包月使用量结果给 c1,缺点:只要写 from HOST_CHANG就会嵌入子查询,默认查询所有字段和子查询结果,若只需要部分字段值,不要子查询结果,可以采用: select部分字段名 fromHOST_CHANG-->
<property name="c1" type="integer" formula="(select count(*) from SERVICE_CHANG s,COST_CHANG c where s.COST_ID=c.ID and s.UNIX_HOST=ID and c.COST_TYPE=‘1‘)">
</property><!-- s.UNIX_HOST不能写死了, 把 ID赋给它, ID为 HOST中的字段-->
<!-- 采用子查询映射将套餐使用量结果给 c2 -->
<property name="c2" type="integer" formula="(select count(*) from SERVICE_CHANG s,COST_CHANG c where s.COST_ID=c.ID and s.UNIX_HOST=ID and c.COST_TYPE=‘2‘)">
</property>
<!--采用子查询映射将计时使用量结果给 c3 -->
<property name="c3" type="integer" formula="(select count(*) from SERVICE_CHANG s,COST_CHANG c where s.COST_ID=c.ID and s.UNIX_HOST=ID and c.COST_TYPE=‘3‘)">
</property>
26
标签:
原文地址:http://www.cnblogs.com/ios9/p/5399949.html