标签:
1.从csv文件导入数据
原理:with语句打开文件并绑定到对象f。不必担心在操作完资源后去关闭数据文件,with的上下文管理器会帮助处理。然后,csv.reader()方法返回reader对象,通过该对象遍历所读取文件的所有行。
1 #!/usr/bin/env python 2 3 import csv 4 5 filename = ‘ch02-data.csv‘ 6 7 data = [] 8 try: 9 with open(filename) as f: 10 reader = csv.reader(f) 11 c = 0 12 for row in reader: 13 if c == 0: 14 header = row 15 else: 16 data.append(row) 17 c += 1 18 except csv.Error as e: 19 print "Error reading CSV file at line %s: %s" % (reader.line_num, e) 20 sys.exit(-1) 21 22 if header: 23 print header 24 print ‘==================‘ 25 26 for datarow in data: 27 print datarow
实验结果截图:
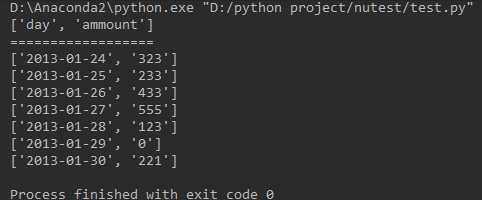
2.从Excel中导入文件数据
Excel文件可以转换成csv文件,然后通过上述的方法导入,但是如果想自动化地对大量文件进行数据管道处理(作为数据连续处理流程的一部分),那么手动把每个Excel文件转换成CSV文件的做法就行不通了。
原理:使用xlrd模块打开文件的工作簿,然后根据行数(nrows)和列数(ncols)读取单元格的内容,通过调用open_workbook()方法,返回一个xlrd.book实例。
1 import xlrd 2 from xlrd.xldate import XLDateAmbiguous 3 4 file = ‘ch02-xlsxdata.xlsx‘ 5 6 wb = xlrd.open_workbook(filename=file) 7 8 ws = wb.sheet_by_name(‘Sheet1‘) 9 10 dataset = [] 11 12 for r in range(ws.nrows): 13 col = [] 14 for c in range(ws.ncols): 15 col.append(ws.cell(r, c).value) 16 if ws.cell_type(r, c) == xlrd.XL_CELL_DATE: 17 try: 18 print ws.cell_type(r, c) 19 from datetime import datetime 20 date_value = xlrd.xldate_as_tuple(ws.cell(r, c).value, wb.datemode) 21 print datetime(*date_value) 22 except XLDateAmbiguous as e: 23 print e 24 dataset.append(col) 25 26 from pprint import pprint 27 28 pprint(dataset)
实验结果:
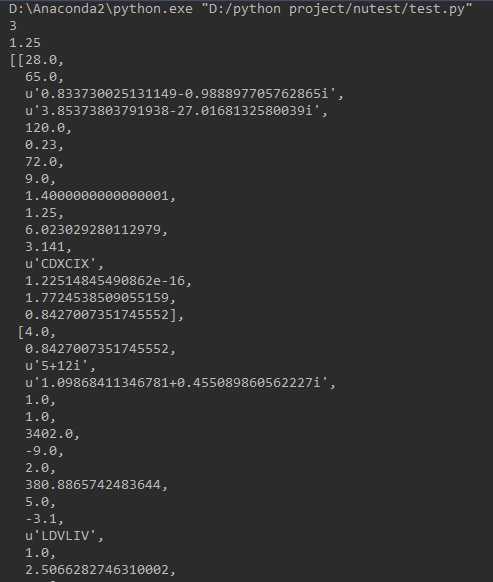
3.从定宽数据文件导入数据
时间的日志文件和基于时间序列的文件是数据可视化中最常见的数据源。有时候,可以以制表符分隔数据这种CSV方言来读取它们,但有时它们不是通过任何特殊字符分隔的。实际上,这些文件的字段是有固定宽度的,我们能通过格式来匹配并提取数据。
例如(本例子的数据是使用代码生成的):
处理方法:
1.指定要读取的数据文件。2.定义数据读取的方式。3.逐行读取文件并根据格式把每行解析成单独的数据字段。4.安单独数据字段的形式打印每一行。
1 import struct 2 import string 3 4 mask=‘9s14s5s‘ 5 parse = struct.Struct(mask).unpack_from 6 print ‘formatstring {!r}, record size: {}‘.format( 7 mask, struct.calcsize(mask)) 8 9 datafile = ‘ch02-fixed-width-1M.data‘ 10 11 with open(datafile, ‘r‘) as f: 12 for line in f: 13 fields = parse(line) 14 print ‘fields: ‘, [field.strip() for field in fields]
实验结果:

4.从JSON数据源导入数据
操作步骤如下:1.指定GitHub URL来读取JSON格式数据。2.使用requests模块访问指定的URL,并读取内容。3.读取内容并将之转化为JSON格式的对象。4.迭代访问JSON对象,对于其中的每一项,读取每个代码库的URL值。
原理:首先,使用requests模块获取远程资源。Requests模块提供了简单的API来定义HTTP谓词,我们只需要发出get()方法调用。我们只对Response.json()方法感兴趣,这个方法可以读取Response.content的内容,把它解析成JSON并加载到JSON对象中。
代码如下:
1 import requests 2 from pprint import pprint 3 url = ‘https://api.github.com/users/justglowing‘ 4 r = requests.get(url) 5 json_obj = r.json() 6 pprint(json_obj)
结果:
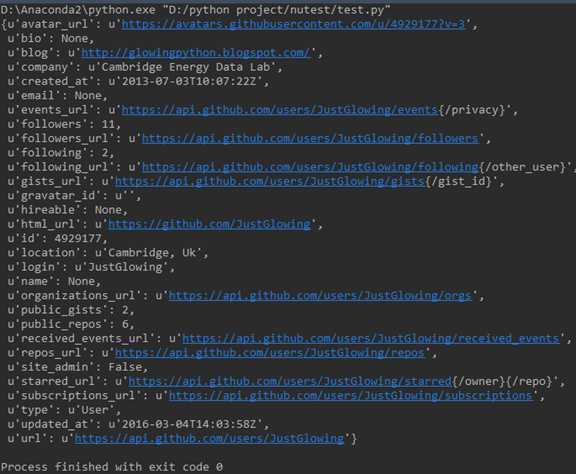
结语:上个月在帮别人做毕业设计,用的FLASK,然后这个月还要用JAVA EE来写个商城网站,忙的要死,一直没更新博客,今天周日图书馆看了python数据可视化,走神一大半,唉,还是更博客吧,可惜的是,说好的要做的精品系列呢。。。。。。。
标签:
原文地址:http://www.cnblogs.com/w1570631036/p/5400870.html