标签:
本来一篇文章就该搞定的。结果要分上下篇了。主要是最近颈椎很不舒服。同时还在做秒杀的需求也挺忙的。 现在不能久坐。看代码的时间变少了。然后还买了两本治疗颈椎的书。在学着,不过感觉没啥用。突然心里好害怕。如果颈椎病越来越重。以后的路怎么走。
现在上下班有跑步,然后坐一个小时就起来活动活动。然后在跟着同时们一起去打羽毛球吧。也快30的人了。现在发觉身体才是真的。其他都没什么意思。兄弟们也得注意~~
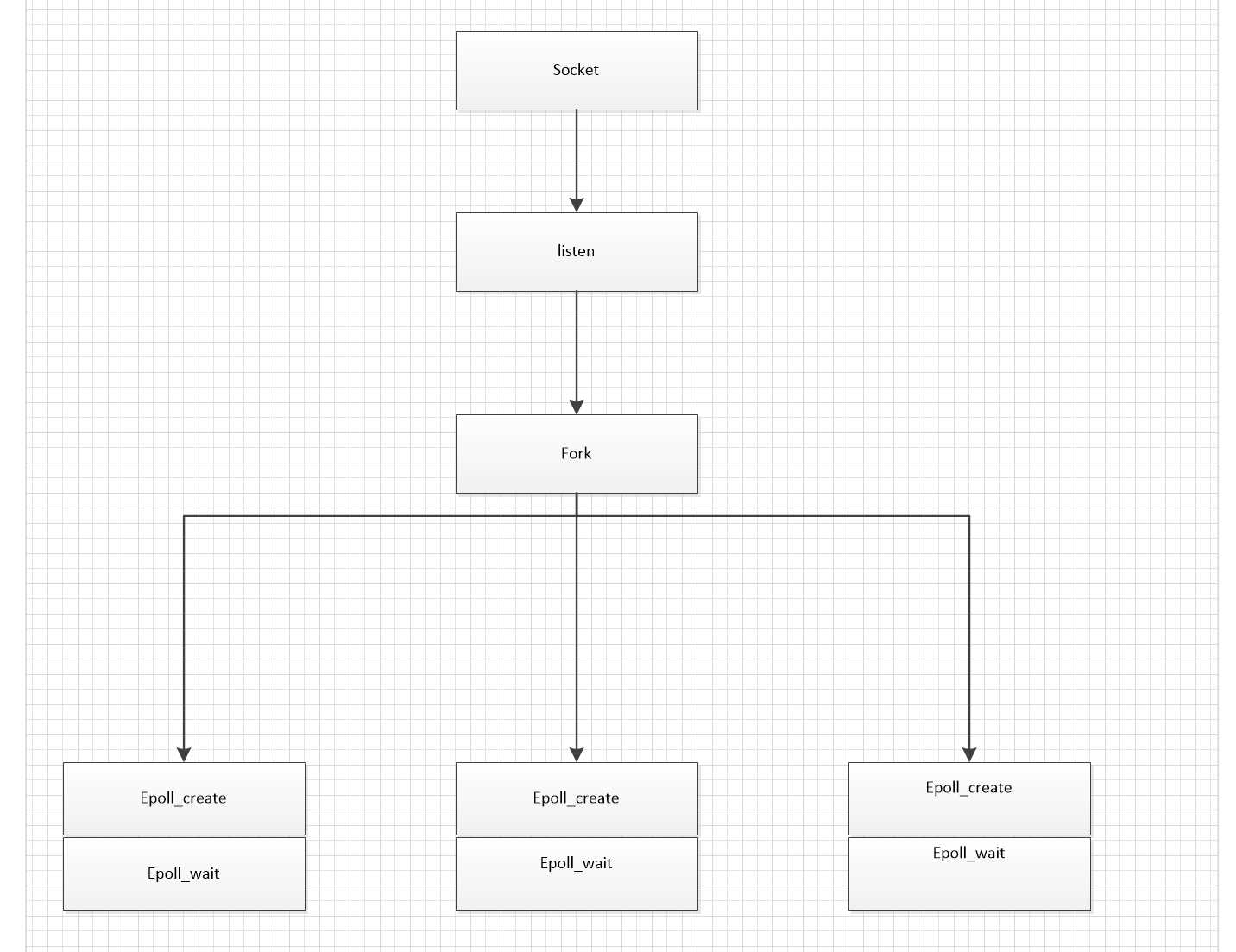
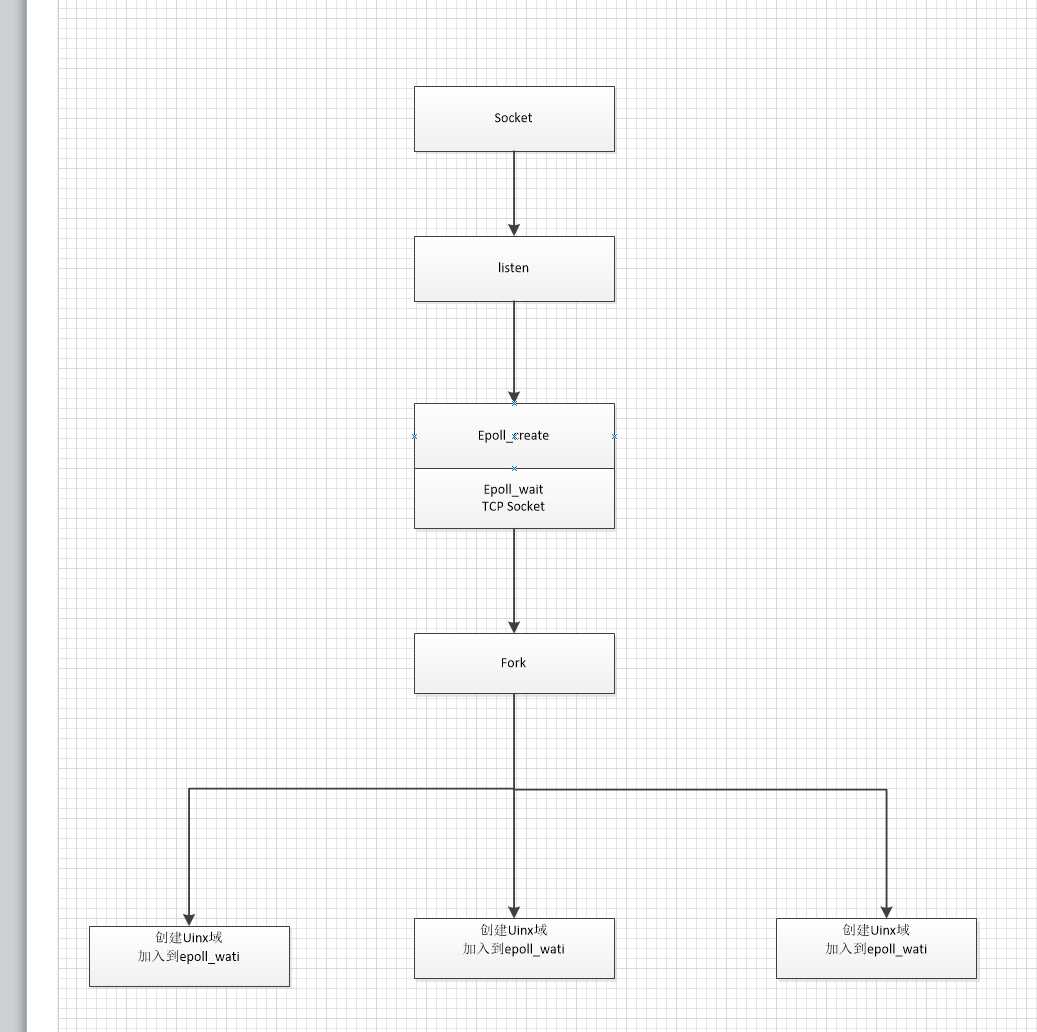
废话不多说。下面介绍下netio。
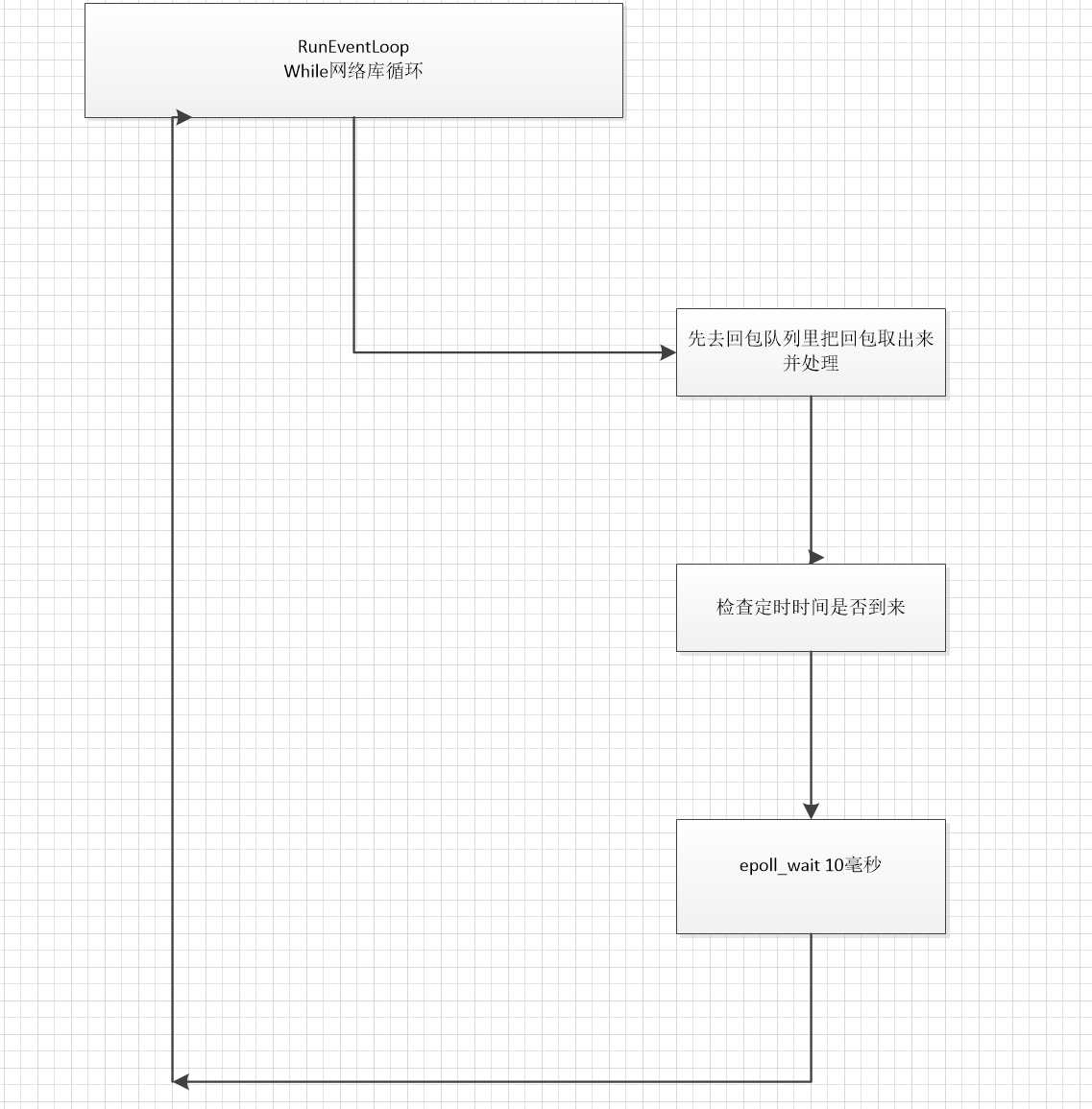
netio在系统中主要是一个分包的作用。netio本事没有任何的业务处理。拿到包以后进行简单的处理。再根据请求的命令字发送到对应的业务处理进程去。
1)比如我们想创建三个进程同时处理一个端口下到来的请求。
james 2356 1 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2357 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2358 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2359 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2360 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml
after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358
after epoll_wait pid:2358 after epoll_wait pid:2358
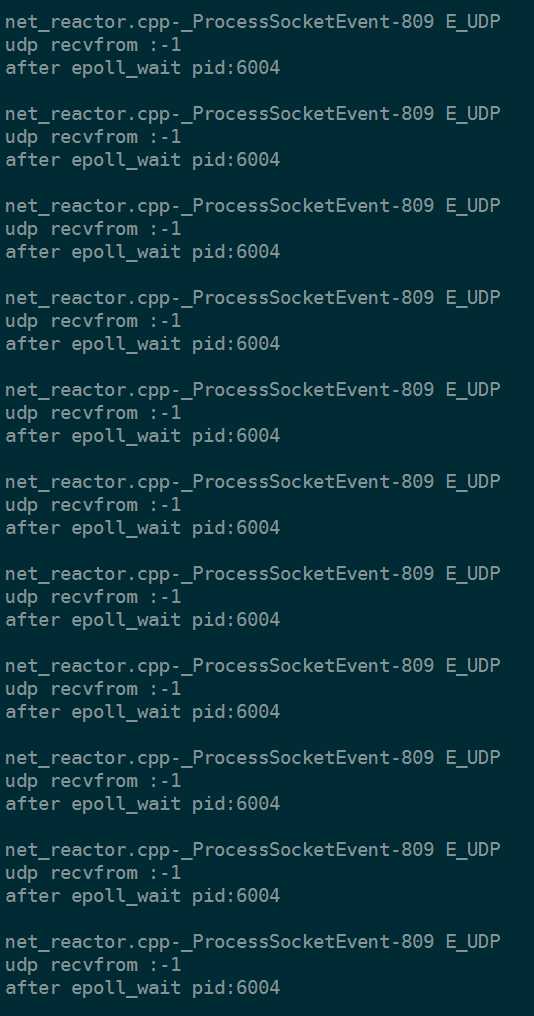
这个时候我们客户端fork8个进程并发请求服务。发现2357和2358开始交替处理
after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358
after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2359 after epoll_wait pid:2356 after epoll_wait pid:2360
after epoll_wait pid:2358
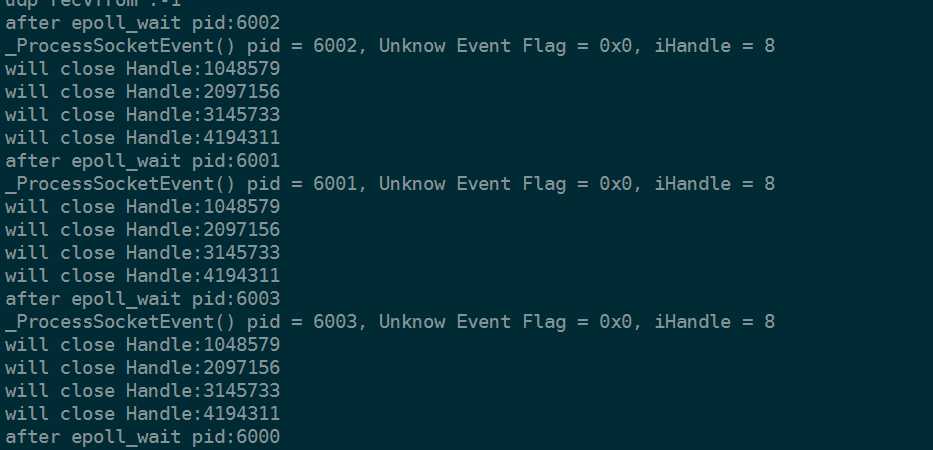
当我们并发两个请求的时候。发现唤醒了两个进程
after epoll_wait pid:2357 after epoll_wait pid:2359

const uint32_t DEFAULT_QUEUE_LEN = 1 + 64; m_pNodeHeap = new CNode*[DEFAULT_QUEUE_LEN];
struct CNode { CNode(ITimerHandler *pTimerHandler = NULL, int iTimerID = 0) : m_pTimerHandler(pTimerHandler) , m_iTimerID(iTimerID) , m_dwCount(0) , bEnable(true) { } ITimerHandler *m_pTimerHandler; int m_iTimerID; CTimeValue m_tvExpired; // TimeValue for first check CTimeValue m_tvInterval; // Time check interval unsigned int m_dwCount; // Counter for auto re-schedule bool bEnable; };
m_pTimerHandler 主要是用来保存父类指针。当时间事件触发的时候。通过父类指针找到继承类。来处理具体的 时间事件 m_tvExpired 记录过期时间。比如一个事件过期时间是10秒。那么m_tvExpired就是存的当前时间+10秒这个值。每次比较的时候。拿最小堆的的这个值跟当前时间比对。如果当前时间小于m_tvExpired说明 没有任何时间时间被触发。如果当前时间大于这个值。则认为需要处理时间事件 m_dwCount 这个是用来设置自动过期时间的次数。比如我们有一个时间事件。我们希望它执行三次。每次的间隔以为1分钟。那么这个值设置为3. 当第一次到达时间时间的时候。我们发现这个值大于0.则对m_tvExpired赋值当前时间+1分钟 重新进入最小堆。然后m_dwCount减一。 下次依然是这样处理。直到m_dwCount这个值到0.我们就认为不需要再自动给这个时间设置定时任务。 bEnable 这个值是用来判断这个事件事件是否还有效。这里的做法很有意思。当一个时间事件执行完。或者不需要的时候。我们先是帮它设置为false.等下次check时间最堆的时候。如果发现这个时间事件是无效的。这个时候在delete m_tvInterval 这个是时间事件的间隔时间。比如我的时间事件是每10秒执行一次。则这个值就设置为10秒 m_iTimerID 这个是时间事件的唯一ID 这个值是自增的。每来一个新时间事件。m_iTimerID都会+1. 因为初始化的时候。这个值为1了。所以最开始的时间事件m_iTimerID的值为2
if (dwCount > 0) m_l_pNode->m_dwCount = dwCount; else m_l_pNode->m_dwCount = (unsigned int)-1;



1)对大型系统。统计日志很重要。可以时事了解系统的状态
2)一定要处理好多进程的关系
3)最后 一定要保护好身体。 身体才是根本啊~~~
标签:
原文地址:http://www.cnblogs.com/ztteng/p/5401783.html