标签:
原创博客,转载请联系博主!
前言:几天前华为的这个软件精英(算法外包)挑战赛初赛刚刚落幕,其实这次是我第二次参加,只不过去年只入围到了64强(32强是复赛线),最后搞到了一个华为的一顶帽子(感谢交大某妹纸快递寄过来!),今年小较了一把真,幸运地闯进了排行榜。(第17位的就是我们Team噢!耶鲁顾神很给力!)
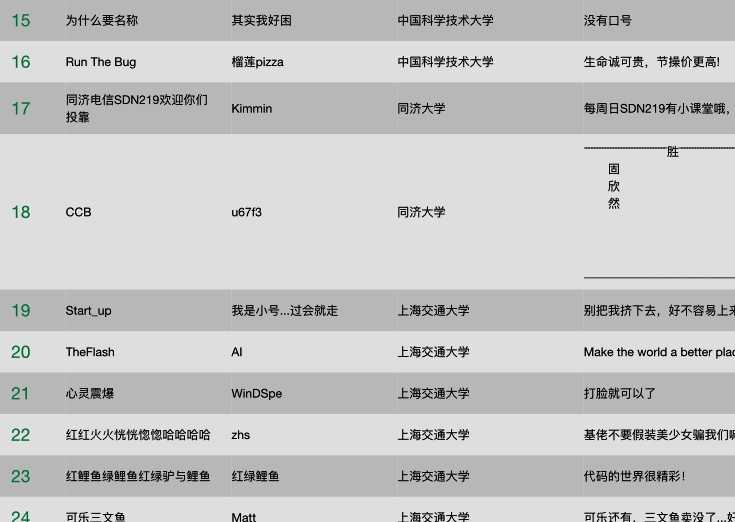
所以呢,回到正题首先来看一下初赛赛题吧!
初赛赛题要求
已知有向图G的拓扑(结点V,边E)和V的一个子图V’,在G内求一条从start结点到end结点的路径,要求经过V’的所有结点并且整个路径要求每个结点每条边只经过一次,在规定的时间内求得的路径的权重越小,则算法得分越高。(start和end结点不在V’中)
当然华为官方提供了专用的sdk(其实用起来很麻烦的好嘛?!)
为什么说这个问题是哈密顿路径问题的变种呢?首先来看一下哈密顿路径问题的定义吧:( 百度百科 )( 维基百科 )
这个赛题在的一个子问题是在V’内求一条哈密顿路径,这个问题本身就是一个np完全的问题 ,直接暴力求解会导致计算时间指数增长,当然利用状态压缩的动态规划可以让哈密顿路径问题在时间复杂度上得到一定的优化。但是无论怎样在这道题中,想要在10秒内稳定地求得要求的路径是随着图的规模增大几乎是不可能的。
所以我们解题的思路经历了如下所示的变化:
深搜/广搜剪枝 -> 遗传算法+深搜 -> 线性规划
解题心路历程
第一阶段 - 深搜/广搜剪枝
其实暴力搜索+剪枝的解法在图的规模比较小的情况下,性能表现甚至会超过其他复杂的算法:
递归的的思路非常简单:
recTraversalGraph:
for every Vertex ’v’ unvisited
mark ’v’ as visited
recTraversalGraph v
unmark ‘v‘ as unvisited
end for
当然直接这么去遍历图的代价是巨大的,所以我们加了一些剪枝的条件:
1. 当前遍历到的点为终点的时候,判断路径是否符合题意,是则记录,否则剪枝。
2. 当前遍历的深度时的cost,已经大于外部记录的最小cost时,剪枝。
3. 当前遍历到的某个边的cost已经大于外部记录的最小cost时,在临接链表删除这个边。
除了剪枝之外,我们还需要简单地压缩图:
1. 将出度仅为1的点和相连接的点merge为同一个点,这个应该很容易理解,暂不赘述。
2. 将出发点和到达点相同的边去除重复,只保留cost最小的边。
当然这么做的提交后的结果果然是令人失望的,只解出了初级的5个测试用例,貌似这些初级用例的点规模不超过100,不过也是在预料之中的事情。
第二阶段 - 遗传算法 + 深搜
到这里我们的算法参考了几篇关于TSP问题的遗传算法求解的论文,在我们决定使用遗传算法的时候,官方提供的比赛环境还是双核的,所以我就果断选择了拥有天生并行性的遗传算法来初步解决,我们的问题,然后再使用深搜去寻找可行/最优解。
针对这个问题我们的遗传算法的解决思路是这样的:
在开始之前我们需要一个SPFA算法,参数可以指定一些图中剔除掉的点,利用Java特性重载Object.clone()即可做到。
for every Vertex ‘v’ in V‘
计算 ‘v’ 的单源最短路径
end for
到这里我们得到了一个|V| * |V‘|的最短路径cost表和一张|V| * |V‘|的路线记录表(路径经过节点顺序,实质上是个生成树)。
然后开始进行遗传算法,这里有三种元操作,详细的介绍请参考上面提供的论文链接。
1. 交配操作,针对TSP问题,我们的交配操作采用的不是通用的k-opt,而是一种叫做‘顺序交叉’的方法。大致就是对于如下所示的AB两个路径序列:
|--- A1 ---|--- A2 ---|--- A3 ---|
|--- B1 ---|--- B2 ---|--- B3 ---|
取随机的两个切割点得到A和B的3*2个子序列,交换A2和B2并且做一些处理,基于随机数解决重复,得到两个孩子序列。
2. 点交换操作
顾名思义,即由随机数交换单个序列上的若干个点后,突变得到的子序列。
3. 段交换操作
和上述操作相似,即由随机数交换单个序列上的若干个段后,突变得到的子序列。
进入遗传算法迭代循环:
while 没有达到大致收敛
RoundRobin法摇随机数
if 符合交配概率: 进行交配操作并淘汰劣者
elsif 符合点突变概率: 进行点突变操作并淘汰劣者
elsif 符合段突变概率: 进行段突变操作并淘汰劣者
else do nothing
end while
值得一提的是,我们利用Java的特性在利用并行性之余,加入了util.concurrent.Exchanger来让两个并行的群组之间一定迭代次数后交换最优秀的个体。
在遗传算法结束之后,我们可以得到若个干个较优秀的候选个体,之后我们需要使用深搜来从这些已知的个体中找出可行解。因为上面遗传算法的评分依据是之前求得的最短路径cost表,我们需要再根据与之对应的最短路径记录表寻找出最短路径之中重叠的边,从图中剔除然后利用带剔除边的SPFA重新计算最短路径。这样一来也就顺便解决了成环的问题。再加上候选个体的数目可以由我们手动控制,所以整个深搜的计算时间是受控制的。初赛赛题中最大规模的点的规模为600个点,遗传算法完成收敛大概需要6~7秒的计算时间,尽管到遗传算法结束,算法的表现依然良好,但是问题出现在了后面。
由于赛题提供的测试用例图都非常稀疏,剔除掉某个边想求出可行解的想法简直Naive,果不其然,我们的算法尽管时间控制得还好,但是将大部分有解的case判定为了无解,尤其是对于唯一可行解就是最优解的case来讲,我们的算法简直不堪一击。在痛下决心之后,我们决定使用数学建模+线性规划来解决这个问题!
第三阶段 - 数学建模+线性规划
我们的规划模型经历了一系列的变化,优化过程其实没有太多参考意义可言,最后的数学模型是这样的:
1. 定义
E1...En为从索引为1...n的边,C1...Cn为边E1...En对应的权重。
系数矩阵为01矩阵,系数矩阵0代表不选择这条边,1代表选择这条边,描述为X1...Xn。
2. 约束函数
对于V内的每个点满足入边系数之和小于等于1: 即每个点最多只能有1个入边。
对于V内的每个点满足出边系数之和小于等于1: 即每个点最多只能由1个出边。
对于V内的每个点满足出边系数之和减去入边系数之和等于0: 即每个点的出边个数和入边个数相等。
对于V‘内的每个点满足出边系数之和等于1: 即必有出边。
对于V‘内的每个点满足入边系数之和等于1: 即必有入边。
无环约束: 1 <= Ui - Uj * Xij*|V| <= |V| - 1
3. 目标函数
MINIMIZE ( C1X1 + C2X2 + ... + Cn-1Xn-1 + CnXn )
一开始我们选择了 GLPK 作为开源库帮助我们求解,但是解不出官方提供的最难的两个case,导致得分一直低迷。后来使用 SCIP-soplex 这个开源库,同样的模型来解决这个问题,再加上SCIP提供了一些非常优秀的启发式,导致我们的得分一路上升。
最后思路锁定下来是这样的:
对于规模小的case,使用深搜+剪枝。
对于规模中的case,使用广搜+剪枝。
对于规模大的case,使用随机化的启发式搜索。
当然最后还有一些优化是语言层面的,比如数组压缩,动态分配之类等等,这篇文章没有聊太多关于实现的细节,有人对具体代码和实现细节感兴趣欢迎留言或者联系我。
<路径算法>哈密顿路径变种问题(2016华为软件精英挑战赛初赛)
标签:
原文地址:http://www.cnblogs.com/guguli/p/5395422.html