标签:
mysql逻辑架构如下:
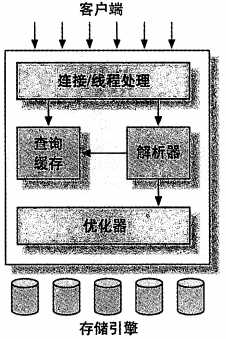
每个客户端连接都会在服务器中拥有一个线程,这个连接的查询只会在这个单独的线程中执行。
MySQL是分层的架构。上层是服务器层的服务和查询执行引擎,下层是存储引擎。虽然有很多不同作用的插件API,但存储引擎API还是最重要的。如果能理解MySQL在存储引擎和服务层之间处理查询时如何通过API来回交互,就能抓住MySQL的核心基础架构的精髓。
数据库系统实现了各种死锁检测和死锁超时机制,InnoDB目前处理死锁的机制是,将持有最少行级排它锁的事务进行回滚。MySQL服务层不管理事务,事务是由下层的存储引擎实现的。
注意,SQL语句一般以‘;‘或者‘\g‘结束。
MySQL支持的其他show语句还有:
SQL语句中最常用的就是select语句了,它用来在一个或多个表中检索数据,select使用示例如下:
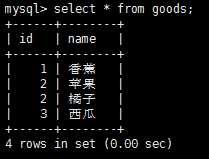
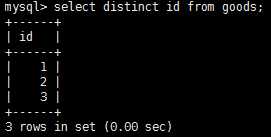
注意,select返回所有匹配的行,但是,如果我们不想每个值都每次出现,怎么办呢?例如,想让上图中输出的id唯一,这样可以再select语句中添加distinct关键字,select distinct id from goods,这样显示结果如下:
有时我们想限制输出的结果,比如返回第一行或前几行,可使用limit子句,如下所示:
当然,我们也可以使用完全限制来进行数据检索:
select goods.id, goods.name from goods 输出goods表中所有记录
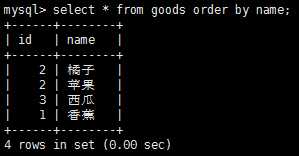
排序检索数据主要使用select语句的order by子句,根据需要排序检索出的数据,select语句默认返回结果是没有特定顺序的,在排序检索数据时也可以指定排序的方向,比如升序或者降序等,order by子句默认为升序排列。
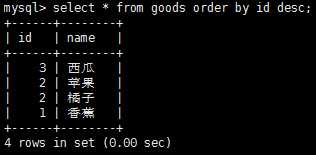 (这个是降序配列)
(这个是降序配列)
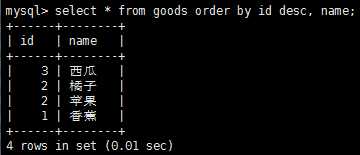
有时,我们需要对多个列排序怎么办呢?这时可以使用如下sql语句来执行,select * from goods order by id desc, name,注意,这里是对id进行降序排列,如果id相同时,对name进行升序排列。如果想对多个列进行降序排列,需要对每个列指定desc关键字。
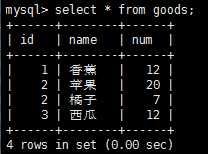
使用order by和limit的组合,我们能够找到一个列中最高或者最低的值,比如这里还用goods表做测试,先给goods表增加一个num字段(alter table goods add num int),并添加上对应的值,最后goods表内容为:
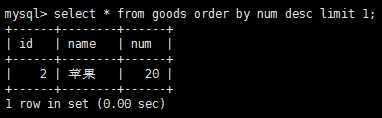
找出剩余数量最多的的水果是:
注意:select语句的order by子句对检索出的数据进行排序,这个字句必须出现在select语句中的最后一条子句。至于为什么,这个我暂时还不知道哈。。。
select语句中,数据可以根据where子句指定的过滤条件进行过滤,where子句在表名(from子句)之后给出,比如,select id, name from goods where id = 2,该语句只显示id为2记录的id和name。注意:如果同时使用where和order by子句,应该让order by子句在where之后,否则会产生错误。
where子句操作符如下:
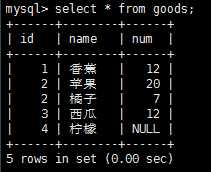
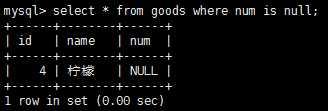
我们在创建表时,可以指定其中的列是否可以不包含值,在一个列不包含值时,其值为空值null,select语句有一个特殊的where子句,用来检测具有null值的列,比如:select * from goods where num is null 就把num是空值得记录给打印出来。
常用的select子句在过滤数据时使用的是单一的条件,为了进行更强的过滤控制,可以下多个where子句,这些子句有两种方式:以and子句和or子句的方式使用。
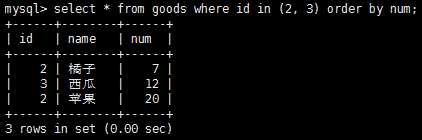
假如多个and和or语句放在一起,则优先处理and操作符,此时可以使用圆括号来改变其优先顺序。圆括号还可以指定in操作符的条件范围,范围中的每个条件都可以进行匹配。
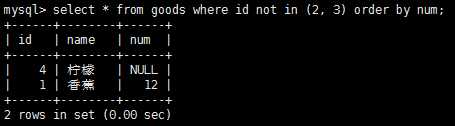
where子句中的not操作符只有否定它之后的任何条件这一作用。
使用like操作符进行通配搜索,以便对数据进行复杂过滤。
百分号(%)操作符 搜索中,%表示任何字符出现任意次数。
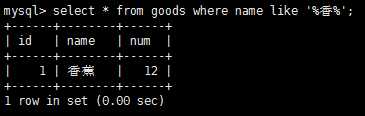
下划线(_)通配符,它用来匹配单个字符而不是多个字符。
通配符很有用,但这是有代价的,通配符的搜索处理一般比其他搜索花费时间长,这里有一些技巧:
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。mysql的where子句对正则表达式提供了初步支持,允许你指定正则表达式 ,过滤select检索出的数据。先看一下表记录:
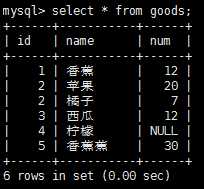
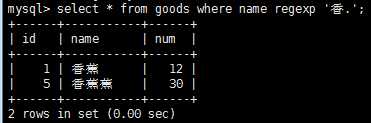
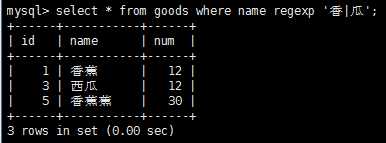
如果记录匹配正则表达式,则就会被检索出来,使用下面正则表达式重复元字符可以进行更强的控制。
注意:regexp和like作用类似,regexp和like不同之处在于,like匹配整个串而regexp匹配子串,利用定位符,通过‘^‘开始每个表达式,用‘$‘结束每个表达式,可以使regexp的作用和like一样。
拼接将值连接到一起构成单个值,在mysql的select语句中,可使用concat()函数来拼接两个列。
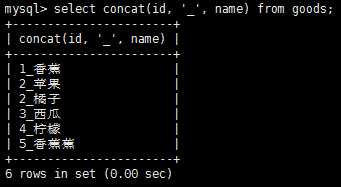
从上图中我们可以看到新的计算列的名字只是一个值,我们可以使用别名来使得它更有意义。同时也可以对检索出的数据进行算术运算,加减乘除都是支持的。
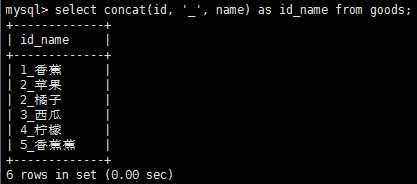
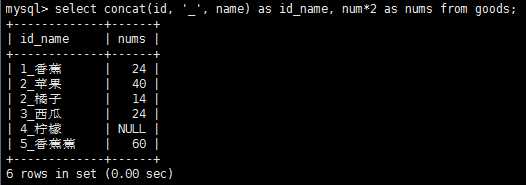
常用的文本处理函数
| 函数 | 说明 |
| left() | 返回串左边的字 |
| length() | 返回串的长度 |
| locate() | 找出串的一个子串 |
| lower() | 将串转换为小写 |
| ltrim() | 去掉串左边的空格 |
| right() | 返回串右边的字符 |
| rtrim() | 返回串右边的字符 |
| soundex() | 返回串的soundex值 |
| substring() | 返回子串的字符 |
| upper() | 将串转换为大写 |
经常需要汇总数据而不是把它们检索出来,为此mysql提供了专门的函数,以便分析和报表生成。常用的例子有:确定表中行数、获取表中行组的和、找出表列的最大值(最小值或平均值)。聚集函数运行在行组上,计算和放回单个值得函数,mysql提供了5个聚集函数,这些函数一般比自己的客户端应用程序中计算要快得多。
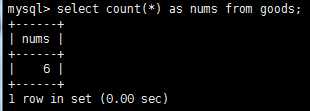
使用关键字distinct使得只选择不同num的记录来参与计算。
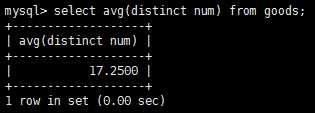
sql聚集函数可以用来汇总数据,这使得我们能够对行计数、计算平均值、获取最大最小值不用检索所有数据。而创建分组允许把数据分为多个逻辑组,以便对每个组进行聚集计算。其涉及到group by子句和having子句。
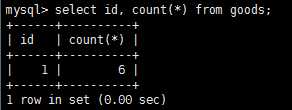
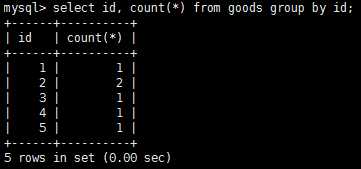
在使用group by子句前,需要知道一些重要的规定:
除了能用group by分组数据外,mysql还允许过滤分组,规定包括哪些分组,排除哪些分组。过滤分组需使用having子句,因为where过滤的是行而不是分组。注意:where是在数据分组前进行过滤,having是在数据分组后进行过滤。

group by和order by经常完成相同的工作,但是二者是非常不同的:
| order by | group by |
| 排序产生的输出 | 分组行,但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列) | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
下面是select语句中子句的顺序,以在select中使用时必须遵循的次序为顺序。
| 子句 | 说明 | 是否必须使用 |
| select | 要返回的列或表达式 | 是 |
| from | 从中检索数据的表 | 仅再从表选择数据时使用 |
| where | 行级过滤 | 否 |
| group by | 分组说明 | 仅在按组计算聚集时使用 |
| having | 组级过滤 | 否 |
| order by | 输出排序顺序 | 否 |
| limit | 要检索的行数 | 否 |
什么是子查询呢?子查询就是嵌套在其他查询中的查询, 在where子句中使用子查询,应该保证select语句具有和where子句中相同数目的列,通常,子查询将返回单个列并且与单个列匹配。
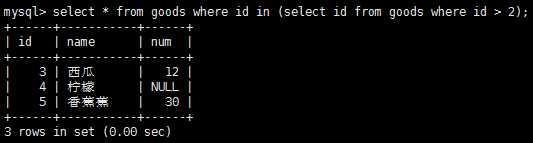
外键为某一个表中的一列,它包含另一个表的主键值,定义了两个表的关系。如果数据存储在多个表中,使用连接可用单条select语句检索出需要的数据。应该保证所有的连联结都有where子句,否则mysql将返回比想要的多的多的数据,因为此时检索出的行数目是第一个表行数乘以第二个表行数。
联结是SQL中最重要最强大的特性。关系表的设计就是要保证把信息分解成多个表,一类数据一个表。各表通过某些常用的值(即关系设计中的关系relational)互相关联。
SELECT vend_name, prod_name, prod_price FROM vecdors, products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name, prod_name; 创建连接表
使用WHERE子句作为过滤条件,它只包含匹配给定给定条件的行。没有WHERE子句,第一个表中的每个行将于第二个表中的每个行配对,而不管它们逻辑上是否可以配对在一起。SQL对一条SELECT语句中可以联结的表的数目没有限制。
基于两个表之间相等测试的联接称为内部联接。其实,对于这种联结可以使用稍微不同的语法来明确指定联结的类型,下面的SELECT语句返回与前面例子完全相同的数据。
SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id;
除了可以给列名和计算字段其别名外,还可以给表起别名。
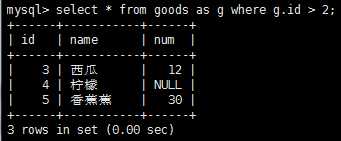
除了使用内部联接(或称为等值联接)的简单链接,还可以使用自联结、自然联结、外部链接。
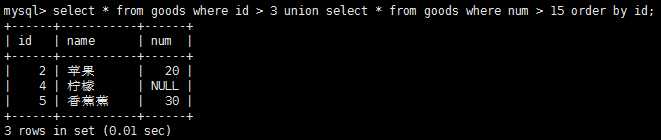
利用union操作符和组合多条SQL查询,让给出的多条select语句结果组合成单个结果集。注意,union必须有2条或者2条以上的select语句组成,union中每个查询必须包含相同的列、表达式或聚集函数(不过每个列不需要以相同的次序列出)。union会自动去除重复的行,这个是默认的行为,如果不想这样,使用union all而不是使用union。
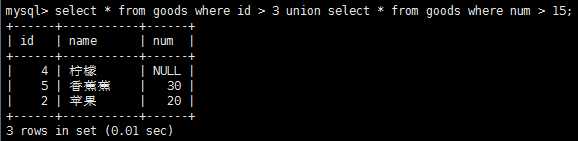
如何对union语句的输出进行排序呢?使用order by子句时,必须放在union最后一条select语句之后,对于结果集,只能有一种排序规则,所以不允许使用功能多条order by子句。
插入语句insert一般会有产生输出,一般只会打印影响的行数。insert时如果不提供列名,则必须给每个表列提供一个值,如果提供列名,则必须对每个列出的列给出一个值,否则报错。
插入一个完整的行:
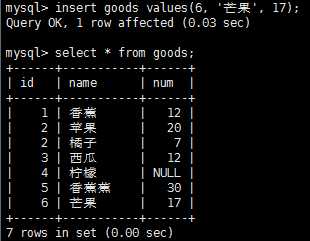
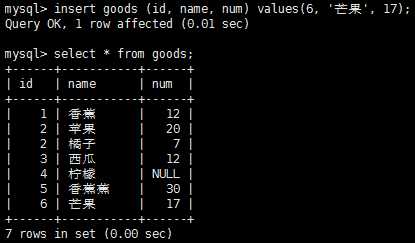
插入多个行:

分别使用update语句和delete语句来进行更新和删除数据操作。先把goods表中数据清除掉一部分,goods表数据如下:
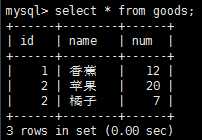
注意,这里有一些使用update和delete语句的一些注意事项:
利用create table创建表,必须给出表的名字,在关键字create table只有给出;表列的名字和定义,用逗号隔开。
create table vendors ( vend_id int not null auto_increment, vend_name char(50) not null, vend_address char(50) null default ‘*‘, vend_city char(40) null, primary key (vend_id) ) engine=InnoDB;
这条语句创建一个vendors表,vend_id和vend_name是必须的,指定为not null,其他的为非必须的,指定为null,null为默认设置。auto_increment关键字告诉mysql,本列每当增加一行时自动增量,可以保证该列值唯一。每个表只允许有一个auto_increment列,而且它必须被索引(如,通过使它为主键)。default为默认值。
注意,主键必须唯一,表中的每个行必须具有唯一的主键,如果主键使用单个列,则它的值必须唯一;如果使用多个列,则这些列的组合必须唯一。外键不能垮跨越引擎。mysql内部打包了多种引擎,以下几个是需要知道的引擎:
使用alter table语句更新表结构。
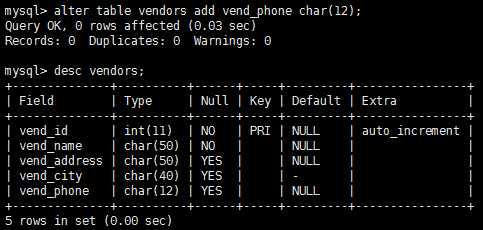
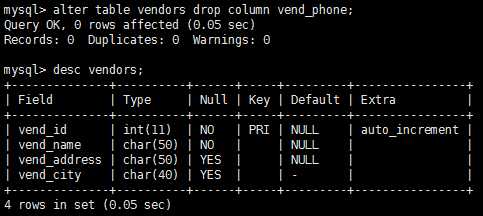
删除表(不是其内容,而是整个表)使用drop语句即可。drop table table_name; 这条语句删除table_name表,只要它存在,注意,删除表时没有确认,也不能撤销。
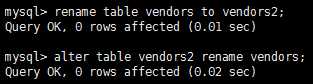
使用rename table语句重命名表。
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询。视图仅仅是用来查看存储在别处数据的一种设施,视图本身不包含数据,因此它们返回的数据是从其他表中检索出来的。视图提供了一种MySQL的SELECT语句层次的封装,可用来简化数据处理以及重新格式化基础数据或保护基础数据。
使用视图的常见应用:
使用视图简化复杂的联结,视图使用create view语句来创建,使用show create view viewname来查看创建视图的语句;用drop删除视图,语法为drop view viewname。
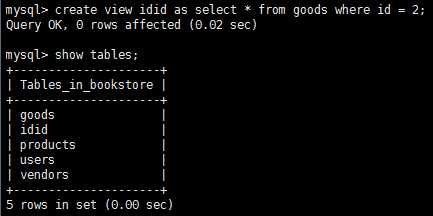
通常,视图是可更新的(可以对它们使用insert、update和delete),更新一个视图将更新其基表,因为视图本身是没有任何数据的。但是,并非所有的视图是可更新的,如果mysql不能正确的确定被更新的基数据,则不能被更新,即如果有一下操作,视图不允许更新:分组、联结、子查询、并、聚集函数、distinct等。
1、MySQL必知必会
2、SQL 教程
3、高性能MySQL
标签:
原文地址:http://www.cnblogs.com/luoxn28/p/5366273.html