标签:
先记录下我用scrapy做的一个小例子。
使用的软件版本:python 2.7.11, scrapy 1.0.5
1. Scrapy通常所使用操作过程:UR2IM
即URL, Request, Response, Items, More URLs。 可以用下面这张图简单的解释:
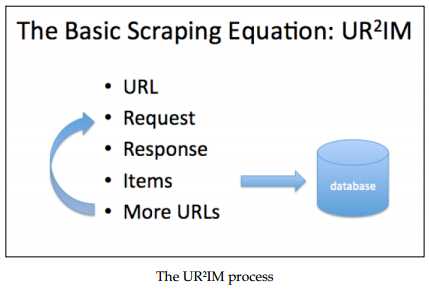
从最初的一个URL发出请求,在得到的Response里面获得需要抓取的信息和获得更多需要抓取的URL,然后将抓取到的信息进行保存并开始更多的抓取工作。
2. Scrapy shell
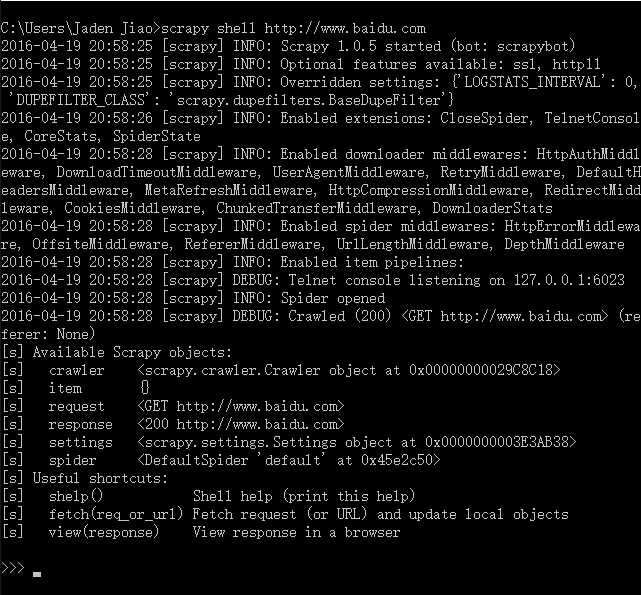
Scrapy shell 是非常有用的工具,经常用来调试使用。那么在 pip install scrapy 安装scrap有成功之后,比如在cmd下输入:
>scrapy shell http://www.baidu.com
得到返回如下,就说明百度的主页已经抓取成功了:
有些网站为了防止被恶意爬虫抓取,需要模拟浏览器进行,我们可以在shell 命令中加入USER_AGENT 属性,即为:
>scrapy shell -s USER_AGENT="Mozilla/6.0" http://www.baidu.com
然后这里便可以使用Xpath解析HTML中所需要的字段,这里再输入:
>>> print response.xpath(‘//title/text()‘).extract()[0] 百度一下,你就知道
3. Xpath表达式
在审查元素中可以看到我们索要抓取内容在HTML中的位置:
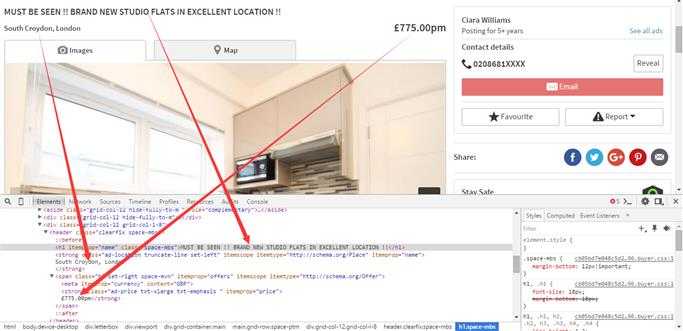
例如项目中所需要抓取的信息有:标题,所在地理位置和价格。
由此可以得到其Xpath表达式为:
>>> response.xpath(‘//h1/text()‘).extract() #title [u‘MUST BE SEEN !! BRAND NEW STUDIO FLATS IN EXCELLENT LOCATION !!‘] >>> response.xpath(‘//strong[@class="ad-price txt-xlarge txt-emphasis "]/text()‘)[0].extract() #price u‘\n\xa3775.00pm‘ >>> response.xpath(‘//*[@class="ad-location truncate-line set-left"]/text()‘).extract() #address [u‘\nSouth Croydon, London\n‘]
4. 创建Scrapy项目
在cmd中cd 到想要创建项目的目录下:
>scrapy startproject <project name>
第一步:定义需要抓取的元素
找到items.py 并编辑,会看到一个类名为项目名称和Item组的组合,编辑之:
from scrapy.item import Item, Field class PropertiesItem(Item): title=Field() price=Field() description=Field() address=Field() image_urls=Field() images=Field() location=Field() url=Field() project=Field() spider=Field() server=Field() date=Field()
第二步:定义爬虫
在项目中cmd 输入:
>scrapy genspider basic gumtree #basic is the name of this spider, gumtree is the attribute of allowd_domain
会看到spider 文件夹下出现basic.py 文件,编辑之:
# -*- coding: utf-8 -*- import scrapy from properties.items import PropertiesItem from scrapy.http import Request import urlparse class BasicSpider(scrapy.Spider): name = "basic" allowed_domains = ["gumtree.com"] start_urls = ( ‘https://www.gumtree.com/all/uk/flat/page1‘, ) def parse(self, response): # get to next page. next_selector=response.xpath(‘//*[@data-analytics="gaEvent:PaginationNext"]/@href‘).extract() for url in next_selector: yield Request(urlparse.urljoin(response.url, url)) # get into each item page. item_selector=response.xpath(‘//*[@itemprop="url"]/@href‘).extract() for url in item_selector: yield Request(urlparse.urljoin(response.url, url), callback=self.parse_item) def parse_item(self, response): item=PropertiesItem() item[‘title‘]=response.xpath(‘//h1/text()‘).extract() item[‘price‘]=response.xpath(‘//strong[@class="ad-price txt-xlarge txt-emphasis "]/text()‘)[0].re(‘[,.0-9]+‘) item[‘description‘]=[response.xpath(‘//p[@itemprop="description"]/text()‘)[0].extract().strip()] item[‘address‘]=[response.xpath(‘//*[@class="ad-location truncate-line set-left"]/text()‘).extract()[0].strip()] item[‘image_urls‘]=[response.xpath(‘//img[@itemprop="image"]/@src‘)[0].extract()] item[‘url‘]=[response.url] return item
在parse函数中我们使用到yield。其实yield我理解它有些像return, 他带有返回;而又不像return,应为他运行之后不会跳出for循环,而是继续执行。这样就达到了获取页面上每个条目,同时进行翻页的效果。
cmd下输入:
>scrapy crawl basic
便可使爬虫运行起来直到爬完这个目录下的所有条目,通常也会设置抓取的条目,来自动终止抓取:
>scrapy crawl basic -s CLOSESPIDER_ITEMCOUNT=100
标签:
原文地址:http://www.cnblogs.com/normalprogrammer/p/5410756.html