标签:
一、什么是lucene
官方的理解:全文检索首先是将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的,这种先建立索引,在根据索引搜索文档的过程叫做全文检索
1、Lucene其实就是一套完整的jar包,可以让程序员使用它来实现全文检索应用的开发
2、全文检索应用,它是完整的索引系统
二、Lucene实现全文检索的流程
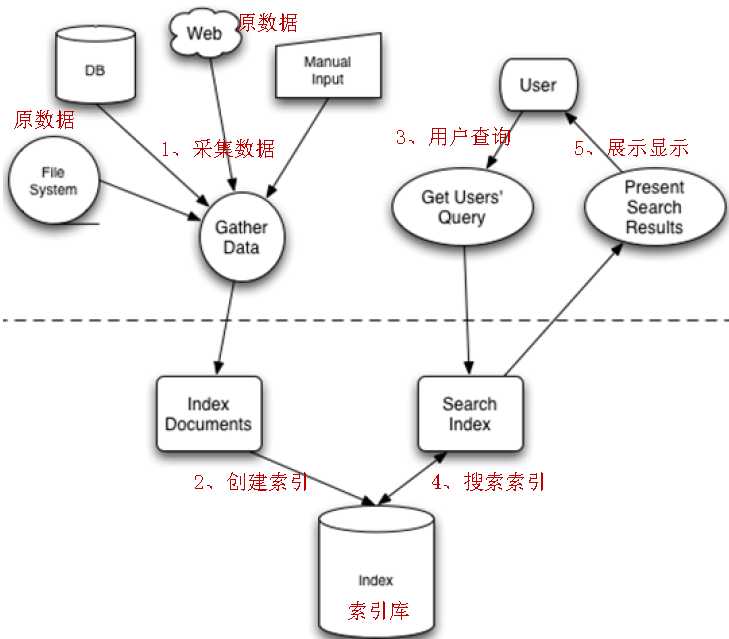
全文检索分为两大流程
1、索引的流程 采集数据---创建索引文档---保存索引到索引库
2、搜索流程 创建查询对象---通过searcher查询索引---从索引库中获取搜索结果---展示搜索结果
注意:Lucene是不具备搜索结果的页面展示功能
三、索引流程实现
分析
: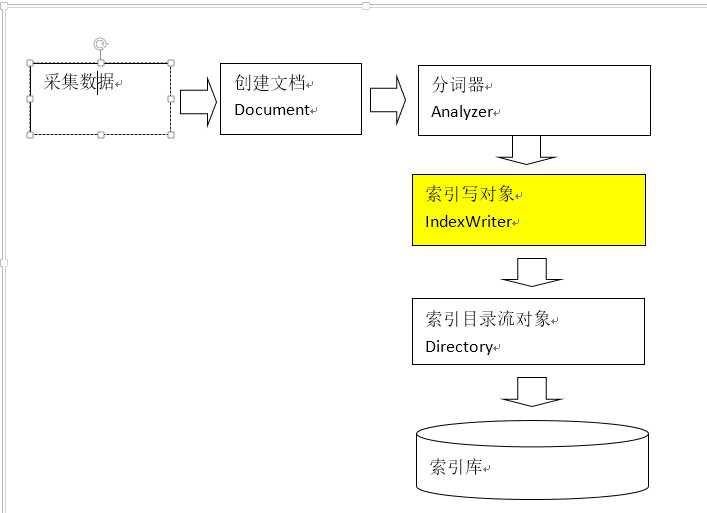
indexWriter对象是索引流程的核心组建,我们可以使用该组件对索引库进行增删改操作
indexWriter不能直接操作索引库,需要通过Directory操作索引库
Directory主要描述了索引库所在的位置,它是抽象类,其中最主要有两种自实现:FSDirectory(文件系统目录)、RAMDirectory(内容的存储目录)
四、为什么我们要采集数据
全文检索要搜索的数据,格式多种多样,比如互联网中网页信息、MP3、avi格式。
这些多种多样的格式的数据,叫非结构化数据。
非结构化数据:格式不固定、长度不固定的数据。比如:互联网数据、word、邮件。
结构化数据:格式固定、长度固定的数据,比如数据库数据。
对于结构化数据的搜索:
由于结构化的数据格式是固定的,所以可以针对固定的格式设置一些算法。比如sql中的like查询。
对于非结构化的数据搜索:
将非结构化数据,转成结构化数据。需要进行数据采集,采集到本地,进行一些处理,转成结构化数据。
五、索引文件的逻辑结构
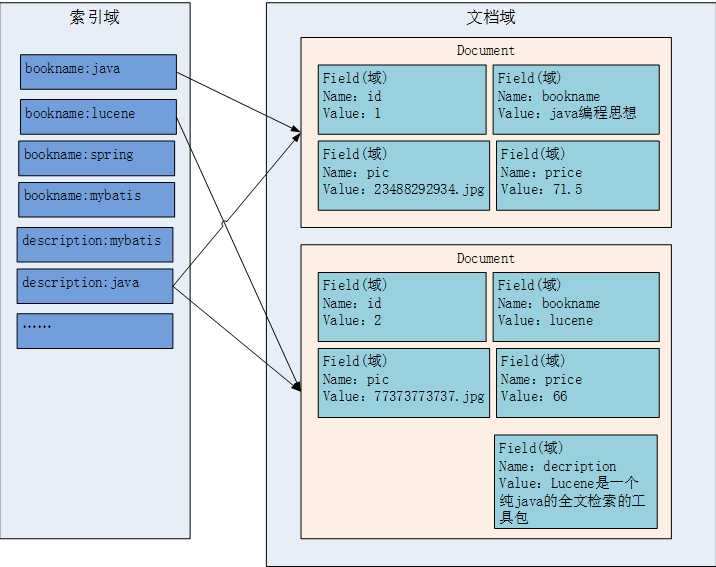
六、代码实现
package my.dizang.po; /** * * @Title: Book.java * @Package my.dizang.po * @Description: TODO(用一句话描述该文件做什么) * @author 地藏 1281782012@qq.com * @date 2016-4-19 下午6:48:15 * @version V1.0 */ public class Book { // 图书ID private Integer id; // 图书名称 private String name; // 图书价格 private Float price; // 图书图片 private String pic; // 图书描述 private String description; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Float getPrice() { return price; } public void setPrice(Float price) { this.price = price; } public String getPic() { return pic; } public void setPic(String pic) { this.pic = pic; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } }
package my.dizang.dao; import java.util.List; import my.dizang.po.Book; /** * * @Title: BookDao.java * @Package my.dizang.dao * @Description: 接口 * @author 地藏 1281782012@qq.com * @date 2016-4-19 下午6:54:25 * @version V1.0 */ public interface BookDao { public List<Book> queryBookList(); }
package my.dizang.dao; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.util.ArrayList; import java.util.List; import my.dizang.po.Book; /** * * @Title: BookDaoImpl.java * @Package my.dizang.dao * @Description: BookDao实现类 * @author 地藏 1281782012@qq.com * @date 2016-4-19 下午6:57:17 * @version V1.0 */ public class BookDaoImpl implements BookDao { @Override public List<Book> queryBookList() { // 使用JDBC获取采集数据 // 数据库连接 Connection connection = null; // 预编译statement PreparedStatement preparedStatement = null; // 结果集 ResultSet resultSet = null; // 图书列表 List<Book> list = new ArrayList<Book>(); try { // 加载数据库驱动 Class.forName("com.mysql.jdbc.Driver"); // 连接数据库 connection = DriverManager.getConnection( "jdbc:mysql://localhost:3306/mybatis", "root", "1234"); // SQL语句 String sql = "SELECT * FROM book"; // 创建preparedStatement preparedStatement = connection.prepareStatement(sql); // 获取结果集 resultSet = preparedStatement.executeQuery(); // 结果集解析 while (resultSet.next()) { Book book = new Book(); book.setId(resultSet.getInt("id")); book.setName(resultSet.getString("name")); book.setPrice(resultSet.getFloat("price")); book.setPic(resultSet.getString("pic")); book.setDescription(resultSet.getString("description")); list.add(book); } } catch (Exception e) { e.printStackTrace(); } return list; } }
package my.dizang.index; import java.io.File; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.BooleanClause.Occur; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.NumericRangeQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; /** * * @Title: IndexSearch.java * @Package my.dizang.index * @Description: 搜索测试类 注意:搜索时的分词器必须和索引的分词器一致 * @author 地藏 1281782012@qq.com * @date 2016-4-20 上午10:50:57 * @version V1.0 */ public class IndexSearch { @Test public void createIndex() throws Exception{ //采集数据 BookDao dao = new BookDaoImpl(); List<Book> bookList = dao.queryBookList(); //创建Document List<Document> docList = new ArrayList<>(); Document document; for (Book book : bookList) { document = new Document(); //创建Field域 //Store :表示是否存储到文档域 //商品ID Field idField = new TextField("id",book.getId().toString(),Store.YES); //商品名称 Field nameField = new TextField("name",book.getName(),Store.YES); //商品价格 Field priceField = new TextField("price",book.getPrice().toString(),Store.YES); //商品图片地址 Field picField = new TextField("pic",book.getPic(),Store.YES); //商品描述 Field descField = new TextField("description",book.getDescription(),Store.YES); document.add(idField); document.add(nameField); document.add(priceField); document.add(picField); document.add(descField); docList.add(document); } //进行分词处理 Analyzer analyzer = new StandardAnalyzer(); //创建Directory //指定索引库所在的路径 Directory directory = FSDirectory.open(new File("E:\\11-index\\1223\\")); //创建IndexWriterConfig IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建IndexWriter IndexWriter writer = new IndexWriter(directory, cfg); //通过IndexWriter经做过分词处理的Document对象存储到索引库 for (Document doc : docList) { writer.addDocument(doc); } //关闭资源 writer.close(); } }
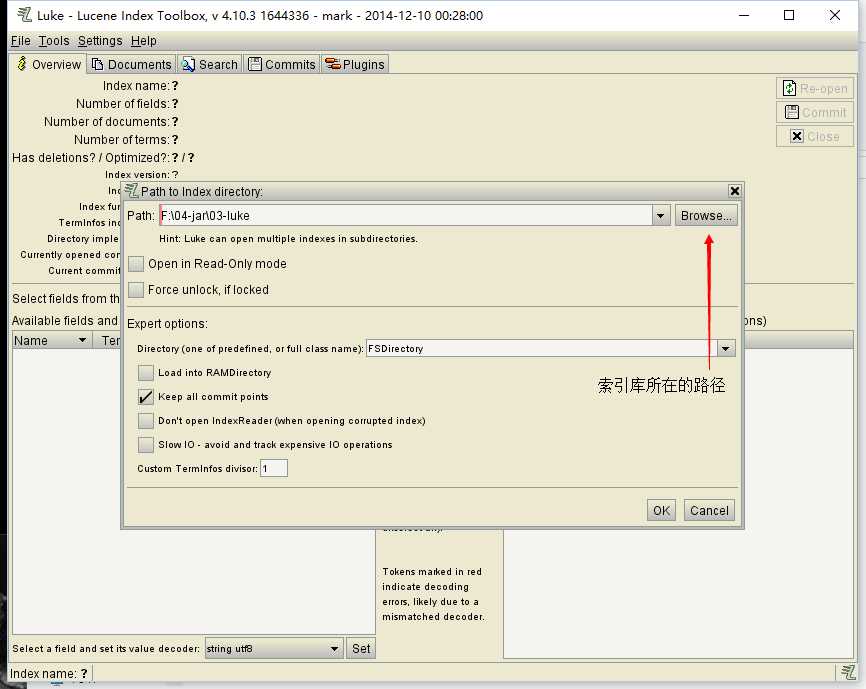
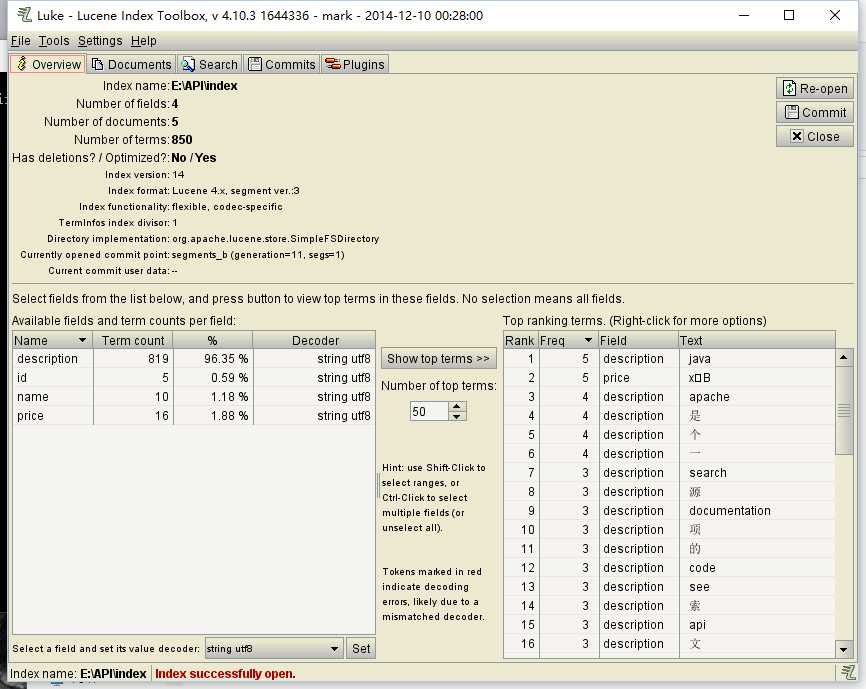
使用luke工具查询索引
标签:
原文地址:http://www.cnblogs.com/dizang/p/5410908.html