标签:
Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
Spring里用的最经典的一个设计模式就是:模板方法模式。
Spring AOP与IOC
一、 IoC(Inversion of control): 控制反转
1、IoC:
概念:控制权由对象本身转向容器;由容器根据配置文件去创建实例并创建各个实例之间的依赖关系
核心:bean工厂;在Spring中,bean工厂创建的各个实例称作bean
二、AOP(Aspect-Oriented Programming): 面向方面编程
1、 代理的两种方式:
静态代理:
针对每个具体类分别编写代理类;
针对一个接口编写一个代理类;
动态代理:
针对一个方面编写一个InvocationHandler,然后借用JDK反射包中的Proxy类为各种接口动态生成相应的代理类
2、动态代理:
不用写代理类,虚拟机根据真实对象实现的接口产生一个类,通过类实例化一个动态代理,在实例化动态代理时将真实对象及装备注入到动态代理中,向客户端公开的是动态代理,当客户端调用动态代理方法时,动态代理根据类的反射得到真实对象的Method,调用装备的invoke方法,将动态代理、 Method、方法参数传与装备的invoke方法,invoke方法在唤起method方法前或后做一些处理。
1、产生动态代理的类:
java.lang.refect.Proxy
2、装备必须实现InvocationHandler接口实现invoke方法
3、反射
什么是类的返射?
通过类说明可以得到类的父类、实现的接口、内部类、构造函数、方法、属性并可以根据构造器实例化一个对象,唤起一个方法,取属性值,改属性值。如何得到一个类说明:
Class cls=类.class;
Class cls=对象.getClass();
Class.forName("类路径");
如何得到一个方法并唤起它?
Class cls=类.class;
Constructor cons=cls.getConstructor(new Class[]{String.class});
Object obj=cons.newInstance(new Object[]{"aaa"});
Method method=cls.getMethod("方法名",new Class[]{String.class,Integer.class});
method.invoke(obj,new Object[]{"aa",new Integer(1)});
4、spring的三种注入方式是什么?
setter
interface
constructor
5、spring的核心接口及核类配置文件是什么?
FactoryBean:工厂bean主要实现ioc/di
ApplicationContext ac=new FileXmlApplicationContext("applicationContext.xml");
Object obj=ac.getBean("id值");
6、Spring框架的7个模块
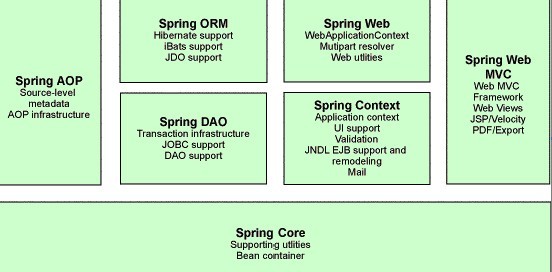
Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在核心容器之上,核心容器定义了创建、配置和管理 bean 的方式,组成 Spring 框架的每个模块(或组件)都可以单独存在,或者与其他一个或多个模块联合实现。每个模块的功能如下:
**核心容器**:核心容器提供 Spring 框架的基本功能。核心容器的主要组件是 BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转 (IOC)模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
**Spring 上下文**:Spring 上下文是一个配置文件,向 Spring 框架提供上下文信息。Spring 上下文包括企业服务,例如 JNDI、EJB、电子邮件、国际化、校验和调度功能。
**Spring AOP**:通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了 Spring 框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
**Spring DAO**:JDBC DAO 抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写的异常代码数量(例如打开和关闭连接)。Spring DAO 的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。
**Spring ORM**:Spring 框架插入了若干个 ORM 框架,从而提供了 ORM 的对象关系工具,其中包括 JDO、Hibernate 和 iBatis SQL Map。所有这些都遵从 Spring 的通用事务和 DAO 异常层次结构。
**Spring Web 模块**:Web 上下文模块建立在应用程序上下文模块之上,为基于 Web 的应用程序提供了上下文。所以,Spring 框架支持与 Jakarta Struts 的集成。Web 模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
**Spring MVC 框架**:MVC 框架是一个全功能的构建 Web 应用程序的 MVC 实现。通过策略接口,MVC 框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括 JSP、Velocity、Tiles、iText 和 POI。
在struts2的应用中,从用户请求到服务器返回相应响应给用户端的过程中,包含了许多组件如:Controller、ActionProxy、ActionMapping、Configuration Manager、ActionInvocation、Inerceptor、Action、Result等。


(1) 客户端(Client)向Action发用一个请求(Request)
(2) Container通过web.xml映射请求,并获得控制器(Controller)的名字
(3) 容器(Container)调用控制器(StrutsPrepareAndExecuteFilter或FilterDispatcher)。在Struts2.1以前调用FilterDispatcher,Struts2.1以后调用StrutsPrepareAndExecuteFilter
(4) 控制器(Controller)通过ActionMapper获得Action的信息
(5) 控制器(Controller)调用ActionProxy
(6) ActionProxy读取struts.xml文件获取action和interceptor stack的信息。
(7) ActionProxy把request请求传递给ActionInvocation
(8) ActionInvocation依次调用action和interceptor
(9) 根据action的配置信息,产生result
(10) Result信息返回给ActionInvocation
(11) 产生一个HttpServletResponse响应
(12) 产生的响应行为发送给客服端。
视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。ActionServlet是一个通用的控制组件。这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数填充 Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。动作类实现核心商业逻辑,它可以访问java bean 或调用EJB。最后动作类把控制权传给后续的JSP 文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。表现逻辑和程序逻辑。
模型:模型以一个或多个java bean的形式存在。这些bean分为三类:Action Form、Action、JavaBean or EJB。Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。Action通常称之为ActionBean,获取从ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
流程:在Struts中,用户的请求一般以.do作为请求服务名,所有的.do请求均被指向ActionSevlet,ActionSevlet根据Struts-config.xml中的配置信息,将用户请求封装成一个指定名称的FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作,数据库操作等。每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。
Struts2和struts1的比较
struts2相对于struts1来说简单了很多,并且功能强大了很多,我们可以从几个方面来看:
从体系结构来看:struts2大量使用拦截器来出来请求,从而允许与业务逻辑控制器 与 servlet-api分离,避免了侵入性;而struts1.x在action中明显的侵入了servlet-api.
从线程安全分析:struts2.x是线程安全的,每一个对象产生一个实例,避免了线程安全问题;而struts1.x在action中属于单线程。
性能方面:struts2.x测试可以脱离web容器,而struts1.x依赖servlet-api,测试需要依赖web容器。
请求参数封装对比:struts2.x使用ModelDriven模式,这样我们 直接 封装model对象,无需要继承任何struts2的基类,避免了侵入性。
标签的优势:标签库几乎可以完全替代JSTL的标签库,并且 struts2.x支持强大的ognl表达式。
当然,struts2和struts1相比,在 文件上传,数据校验 等方面也 方便了好多。在这就不详谈了。
hibernate 简介:
hibernate是一个开源框架,它是对象关联关系映射的框架,它对JDBC做了轻量级的封装,而我们java程序员可以使用面向对象的思想来操纵数据库。
hibernate核心接口
session:负责被持久化对象CRUD操作
sessionFactory:负责初始化hibernate,创建session对象
configuration:负责配置并启动hibernate,创建SessionFactory
Transaction:负责事物相关的操作
Query和Criteria接口:负责执行各种数据库查询
hibernate工作原理:
1.通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
2.由hibernate.cfg.xml中的读取并解析映射信息
3.通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
4.Session session = sf.openSession();//打开Sesssion
5.Transaction tx = session.beginTransaction();//创建并启动事务Transation
6.persistent operate操作数据,持久化操作
7.tx.commit();//提交事务
8.关闭Session
9.关闭SesstionFactory
为什么要用hibernate:
1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
Hibernate是如何延迟加载?get与load的区别
对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。
Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
(2)若为false,就跟Hibernateget方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
load方法可返回没有加载实体数据的代 理类实例,而get方法永远返回有实体数据的对象。
总之对于get和load的根本区别,一句话,hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都是对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many、
说下Hibernate的缓存机制:
Hibernate缓存的作用:
Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据
Hibernate缓存分类:
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存
Hibernate一级缓存又称为“Session的缓存”,它是内置的,意思就是说,只要你使用hibernate就必须使用session缓存。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。在第一级缓存中,持久化类的每个实例都具有唯一的OID。
Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
什么样的数据适合存放到第二级缓存中?
1 很少被修改的数据
2 不是很重要的数据,允许出现偶尔并发的数据
3 不会被并发访问的数据
4 常量数据
不适合存放到第二级缓存的数据?
1经常被修改的数据
2 .绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3 与其他应用共享的数据。
Hibernate查找对象如何应用缓存?
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;如果都查不到,再查询数据库,把结果按照ID放入到缓存
删除、更新、增加数据的时候,同时更新缓存
Hibernate管理缓存实例
无论何时,我们在管理Hibernate缓存(Managing the caches)时,当你给save()、update()或saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。
当随后flush()方法被调用时,对象的状态会和数据库取得同步。 如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合。
Hibernate的查询方式
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
如何优化Hibernate?
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
hibernate的开发步骤:
开发步骤
1)搭建好环境
引入hibernate最小的jar包
准备Hibernate.cfg.xml启动配置文件
2)写实体类(pojo)
3)为实体类写映射文件”User.hbm.xml”
在hibernate.cfg.xml添加映射的实体
4)创建库表
5)写测试类
获得Configuration
创建SessionFactory
打开Session
开启事务
使用session操作数据
提交事务
关闭资源
什么是Mybatis
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)。
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手工设置参数以及抽取结果集。MyBatis 使用简单的 XML 或注解来配置和映射基本体,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
MyBatis是iBatis的升级版,用法有很多的相似之处,但是MyBatis进行了重要的改进。例如:
1、Mybatis实现了接口绑定,使用更加方便。
在ibatis2.x中我们需要在DAO的实现类中指定具体对应哪个xml映射文件, 而Mybatis实现了DAO接口与xml映射文件的绑定,自动为我们生成接口的具体实现,使用起来变得更加省事和方便。
2、对象关系映射的改进,效率更高
3、MyBatis采用功能强大的基于OGNL的表达式来消除其他元素。
原理详解:
MyBatis应用程序根据XML配置文件创建SqlSessionFactory,SqlSessionFactory在根据配置,配置来源于两个地方,一处是配置文件,一处是Java代码的注解,获取一个SqlSession。SqlSession包含了执行sql所需要的所有方法,可以通过SqlSession实例直接运行映射的sql语句,完成对数据的增删改查和事务提交等,用完之后关闭SqlSession。
MyBatis的优缺点
优点:
1、简单易学
mybatis本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
2、灵活
mybatis不会对应用程序或者数据库的现有设计强加任何影响。 sql写在xml里,便于统一管理和优化。通过sql基本上可以实现我们不使用数据访问框架可以实现的所有功能,或许更多。
3、解除sql与程序代码的耦合
通过提供DAL层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
4、提供映射标签,支持对象与数据库的orm字段关系映射
5、提供对象关系映射标签,支持对象关系组建维护
6、提供xml标签,支持编写动态sql。
缺点:
1、编写SQL语句时工作量很大,尤其是字段多、关联表多时,更是如此。
2、SQL语句依赖于数据库,导致数据库移植性差,不能更换数据库。
3、框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
4、二级缓存机制不佳
总结
mybatis的优点同样是mybatis的缺点,正因为mybatis使用简单,数据的可靠性、完整性的瓶颈便更多依赖于程序员对sql的使用水平上了。sql写在xml里,虽然方便了修改、优化和统一浏览,但可读性很低,调试也非常困难,也非常受限。
mybatis没有hibernate那么强大,但是mybatis最大的优点就是简单小巧易于上手,方便浏览修改sql语句。
SpringMVC框架介绍
1) Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。
Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块。使用 Spring 可插入的 MVC 架构,可以选择是使用内置的 Spring Web 框架还是 Struts 这样的 Web 框架。通过策略接口,Spring 框架是高度可配置的,而且包含多种视图技术,例如 JavaServer Pages(JSP)技术、Velocity、Tiles、iText 和 POI。Spring MVC 框架并不知道使用的视图,所以不会强迫您只使用 JSP 技术。
Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。
2) Spring的MVC框架主要由DispatcherServlet、处理器映射、处理器(控制器)、视图解析器、视图组成。
SpringMVC原理图

SpringMVC接口解释
DispatcherServlet接口:
Spring提供的前端控制器,所有的请求都有经过它来统一分发。在DispatcherServlet将请求分发给Spring Controller之前,需要借助于Spring提供的HandlerMapping定位到具体的Controller。
HandlerMapping接口:
能够完成客户请求到Controller映射。
Controller接口:
需要为并发用户处理上述请求,因此实现Controller接口时,必须保证线程安全并且可重用。
Controller将处理用户请求,这和Struts Action扮演的角色是一致的。一旦Controller处理完用户请求,则返回ModelAndView对象给DispatcherServlet前端控制器,ModelAndView中包含了模型(Model)和视图(View)。
从宏观角度考虑,DispatcherServlet是整个Web应用的控制器;从微观考虑,Controller是单个Http请求处理过程中的控制器,而ModelAndView是Http请求过程中返回的模型(Model)和视图(View)。
ViewResolver接口:
Spring提供的视图解析器(ViewResolver)在Web应用中查找View对象,从而将相应结果渲染给客户。
SpringMVC运行原理
1. 客户端请求提交到DispatcherServlet
2. 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller
3. DispatcherServlet将请求提交到Controller
4. Controller调用业务逻辑处理后,返回ModelAndView
5. DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
6. 视图负责将结果显示到客户端
DispatcherServlet是整个Spring MVC的核心。它负责接收HTTP请求组织协调Spring MVC的各个组成部分。其主要工作有以下三项:
1. 截获符合特定格式的URL请求。
2. 初始化DispatcherServlet上下文对应的WebApplicationContext,并将其与业务层、持久化层的WebApplicationContext建立关联。
3. 初始化Spring MVC的各个组成组件,并装配到DispatcherServlet中。
Spring struts2 hibernate MyBatis SpringMVC 原理
标签:
原文地址:http://blog.csdn.net/hj7jay/article/details/51206148
